Python实现股票查询
需求:
- 根据输入的名字,进行模糊查询股票
- 根据输入的公式,筛选出符合条件的股票,筛选项包括:当前价、涨跌幅、换手率!比如输入
当前价>30 - 能够重复查询,并对符合条件的股票计数、打印出来!
数据源: stock_data.txt
股票代码,股票名称,当前价,涨跌额,涨跌幅,年初至今,成交量,成交额,换手率,市盈率(TTM),股息率,市值
SH601778,N晶科,6.29,+1.92,+43.94%,+43.94%,259.66万,1625.52万,0.44%,22.32,-,173.95亿
SH688566,路飞学城,52.66,+6.96,+15.23%,+122.29%,1626.58万,8.09亿,42.29%,89.34,-,98.44亿
SH688268,华特气体,88.80,+11.72,+15.20%,+102.51%,622.60万,5.13亿,22.87%,150.47,-,106.56亿
SH600734,实达集团,2.60,+0.24,+10.17%,-61.71%,1340.27万,3391.14万,2.58%,亏损,0.00%,16.18亿
SH900957,凌云B股,0.36,+0.033,+10.09%,-35.25%,119.15万,42.10万,0.65%,44.65,0.00%,1.26亿
SZ000584,当前价智能,6.01,+0.55,+9.07%,-4.15%,2610.86万,1.53亿,4.36%,199.33,0.26%,36.86亿
SH600599,熊猫金控,6.78,+0.62,+10.06%,-35.55%,599.64万,3900.23万,3.61%,亏损,0.00%,11.25亿
SH600524,文一科技,8.21,+0.75,+8.05%,-24.05%,552.34万,4464.69万,3.49%,亏损,0.00%,13.01亿
SH600520,华特科技,6.21,+0.75,+10.05%,-2.05%,552.34万,4464.69万,3.49%,亏损,0.00%,13.01亿
思路
-
首先吧txt文档数据读取到内存中
- 涉及多次查询,所以存到一个字典里,查询速度比较快
- 第一行明显区别于其他行,是一个表头,单独存放到一个列表内,可以利用这个列表获得输入的查询项的索引值
- 每行末尾都有一个空格,利用
strip()函数格式化,并使用split(',')切割每行成列表格式 - 因为ID是唯一的,一般都把ID拿来做字典的键,这里为”股票代码“
-
能重复查询则用while死循环
- 引入变量
count对查询结果计数,每次循环开始清零 input()函数接受输入指令
- 引入变量
-
利用正则表达式判断公式的合法性
- 使用
<>对输入命令进行切割 - 如果切割长度为1,则公式格式不合法。
- 进行股票名称模糊查询,打印结果,结束循环
- count首次计数前打印出表头,方便阅读查询结果
- 如果切割长度为2,则公式格式合法
- 公式格式合法判断列名是否合法
- 列名合法,判断数值是否合法
- 使用
-
公式合法,进行股票筛选并打印结果
- 判断输入命令中是
<还是>,并根据判断结果在字典中查询 - 有的数值有百分号,使用
strip('%')格式化, - 输入的数值和字典中的数值都是字符型,需要转为float型
- 判断输入命令中是
实现结果实例
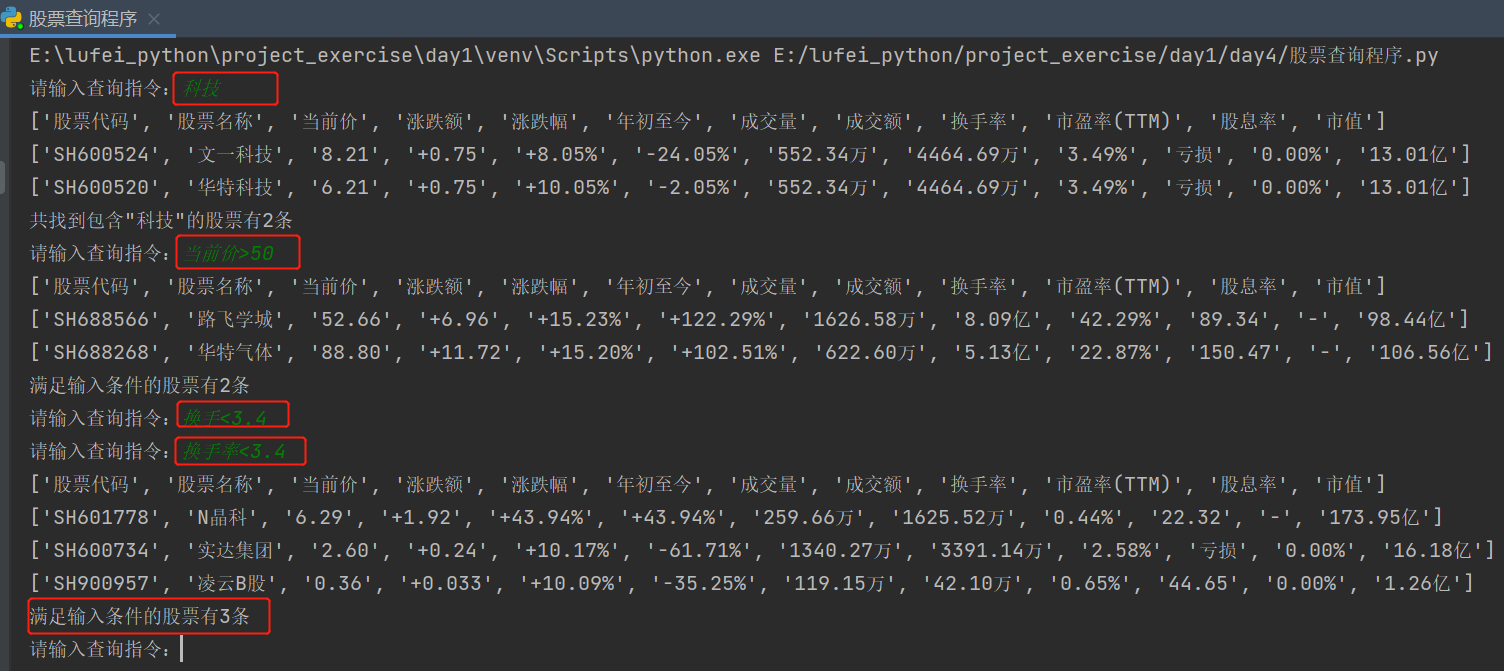
- 输入***”科技“***,查询带有这两个字的股票
- 输入***当前价>50***,找出2条记录
- 输入***换手<3.4***,因为输入的列名少一个字,不合法,所以要求重新输入
- 输入***换手率<3.4***,筛选出3条记录
完整代码实现
import re #导入re模块,使用正则表达式
# ------------打开文件,读取数据到字典--------------
s_dict = {} # 存放读取的数据,字典结构
f = open('stock_data', 'r', encoding='utf-8') #
header = f.readline().strip().split(',') # 吧第一行的表头读取出来单独存放到一个列表
for line in f:
line = line.strip().split(',')
s_dict[line[0]] = line
f.close()
# for key, value in s_dict.items():
# print(key, value)
# 重复查询那肯定是死循环,使用while,用户输入,接受一个指令
while True:
count = 0
cmd = input("请输入查询指令:")
# ------------判断公式合法性--------------
cmd_parser = re.split("[<>]", cmd) # 导入re模块,利用正则表达式进行切割
if len(cmd_parser) != 2: # 判断公式合法性,
# ------------模糊查询股票--------------
for i in s_dict: # 公式不合法,进行模糊查询股票
if cmd in s_dict[i][1]:
if count == 0: # 显示一次表头,方便阅读搜索结果,下同
print(header)
count += 1
print(s_dict[i])
print(f'''共找到包含"{cmd}"的股票有{count}条''')
continue # 公式不合法,模糊查询股票后返回重新输入指令
if cmd_parser[0] not in ['当前价', '涨跌幅', '换手率']: # 判断列表合法性
continue
try: # 判断数值的合法性,比如输入当前价>a,a是不合法的,如果没有这里的判断,成勋会报ValueError错误
cmd_parser[1] = float(cmd_parser[1])
except ValueError:
continue
# ------------根据公式筛选股票--------------
s_index = header.index(cmd_parser[0]) # 从表头获取列名的索引
for s_id, s_value in s_dict.items():
if '>' in cmd:
if float(s_value[s_index].strip('%')) > float(cmd_parser[1]):
if count == 0:
print(header)
print(s_value)
count += 1
else:
if float(s_value[s_index].strip('%')) < float(cmd_parser[1]):
if count == 0:
print(header)
print(s_value)
count += 1
print(f"满足输入条件的股票有{count}条")