文章目录
主要参考链接:
python 是一个基于虚拟机的语言,“先编译后解释”, Python解释器将源码转换为字节码(跨平台,统一的,只不过不同OS的虚拟机基于它产生不同的机器指令实现跨平台),然后再由解释器来执行这些字节码,转化为合适的机器指令,然后执行。 一般的IDE,会将编译与解释这两步合成一步。
1. python执行过程简介
对于Python的解释语言特性,我们要一分为二的看待。
- 一方面,每次运行时都要进行转换成字节码,然后再由虚拟机把字节码转换成机器语言,最后才能在硬件上运行。较之于编译性编程语言,每次运行都会多出两道工序,所以它的性能会受到影响。
- 另一方面,由于不用关心程序的编译以及库的连接等问题,所以开发工作会变得更轻松;同时虚拟机距离物理机器更远了,所以Python程序更加易于移植,实际上无需改动就能在多种平台上运行。
- 另外,可以 防止源码的泄露 。因为py文件是可以直接看到源码的,如果你是开发商业软件的话,不可能把源码也泄漏出去吧?所以就需要编译为pyc后,再发布出去。当然,pyc文件也是可以反编译的,不同版本编译后的pyc文件是不同的,根据python源码中提供的opcode,可以根据pyc文件反编译出py文件源码,网上可以找到一个反编译python2.3版本的pyc文件的工具,不过该工具从python2.4开始就要收费了,如果需要反编译出新版本的pyc文件的话,就需要自己动手了,不过你可以自己修改python的源代码中的opcode文件,重新编译python,从而防止不法分子的破解。
解释型语言的实现中,翻译器并不产生目标机器代码,而是产生易于执行的中间代码,这种中间代码与机器代码是不同的,中间代码的解释是由软件支持的,不能直接使用硬件,软件解释器通常会导致执行效率较低。用解释型语言编写的程序是由另一个可以理解中间代码的解释程序执行的。与编译程序不同的是,解释程序的任务是逐一将源程序的语句解释成可执行的机器指令,不需要将源程序翻译成目标代码后再执行。对于解释型Basic语言,需要一个专门的解释器解释执行Basic程序,每条语言只有在执行才被翻译。这种解释型语言每执行一次就翻译一次,因而效率低下。
Java很特殊,Java程序也需要编译,但是没有直接编译称为机器语言,而是编译称为字节码,然后在Java虚拟机上用解释方式执行字节码。Python的也采用了类似Java的编译模式,先将Python程序编译成Python字节码,然后由一个专门的Python字节码解释器负责解释执行字节码。
另外Python还提供了-O选项,可以编译生成"优化"的bytecode,文件扩展名是.pyo。但实际上优化的内容有限,作用不大。如果希望生成可执行文件,就要依赖于第三方的工具了。
1.1 PyCodeObject 和 pyc文件
pyc文件其实是PyCodeObject的一种持久化保存方式。
- 当
python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。 - 当
python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
1.2 运行一个python文件
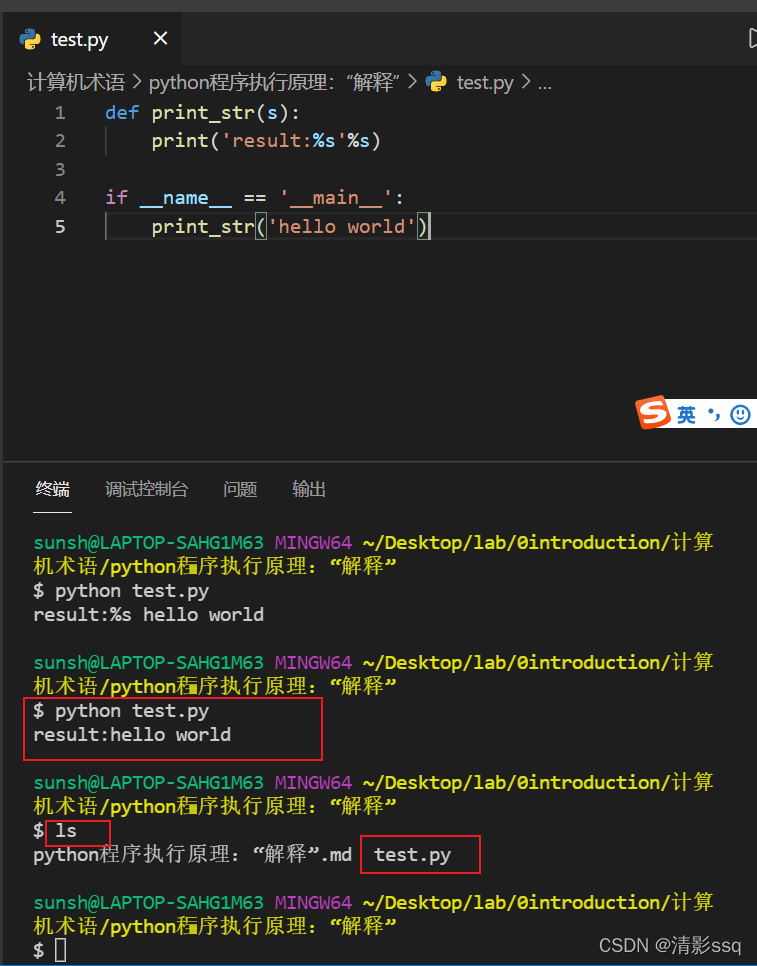
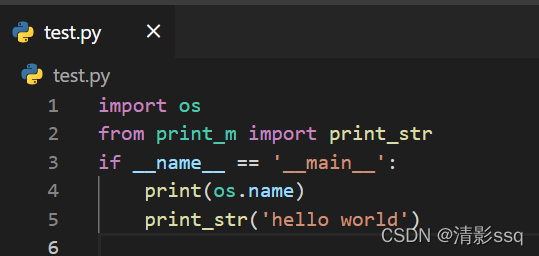
程序中并没有看到pyc文件,仍然是test.py孤零零地呆在那! 我们换一种写法,我们把print_str方法换到另外的一个python模块中:
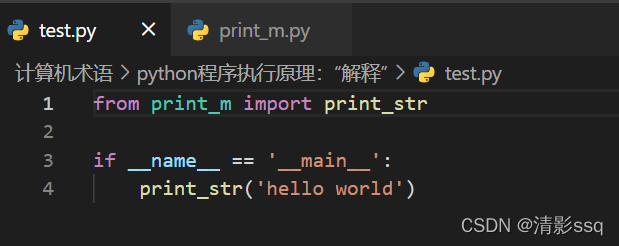
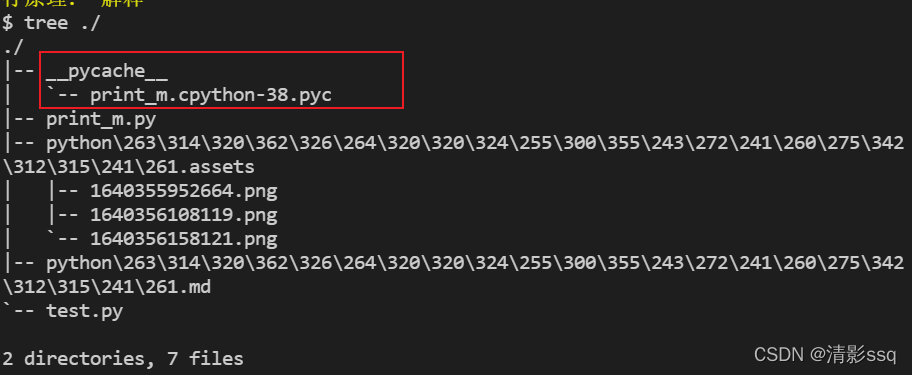
2. pyc文件
pyc是一种二进制文件,pyc的目的是重用。Python解释器只把我们可能重用到的模块持久化成pyc文件,一般是import的模块。 主文件一般只需要加载一次不会被其他模块导入,所以一般主文件不会生成pyc文件。
- 我们之所以要把py文件编译成pyc文件,最大的优点在于我们在运行程序时,不需要重新对该模块进行重新的解释。 所以,我们需要编译成pyc文件的应该是那些可以重用的模块,这于我们在设计软件类时是一样的目的。所以Python的解释器认为:只有import进来的模块,才是需要被重用的模块。
2.1 pyc文件的生成
-
python提供了内置的类库来实现吧py文件编译为pyc文件, 这个模块就是
py_compile模块。compile函数的原型:compile(file[, cfile[, dfile[, doraise]]]),具体参数不多介绍。 -
批量生成pyc文件: 一般来说,我们的工程都是在一个目录下的,一般不会说仅仅编译一个py文件而已,而是需要把整个文件夹下的py文件都编译为pyc文件,python又为了我们提供了另一个模块:
compileall。使用方法如下: 这样就把game目录,以及其子目录下的py文件编译为pyc文件了。import compileall compileall.compile_dir(r'H:/game')
2.2 pyc文件的过期时间
pyc文件的过期时间:说完了pyc文件,可能有人会想到,每次Python的解释器都把模块给持久化成了pyc文件,那么当我的模块发生了改变的时候,是不是都要手动地把以前的pyc文件remove掉呢?当然Python的设计者是不会犯这么白痴的错误的。而这个过程其实就取决于PyCodeObject是如何写入pyc文件中的。
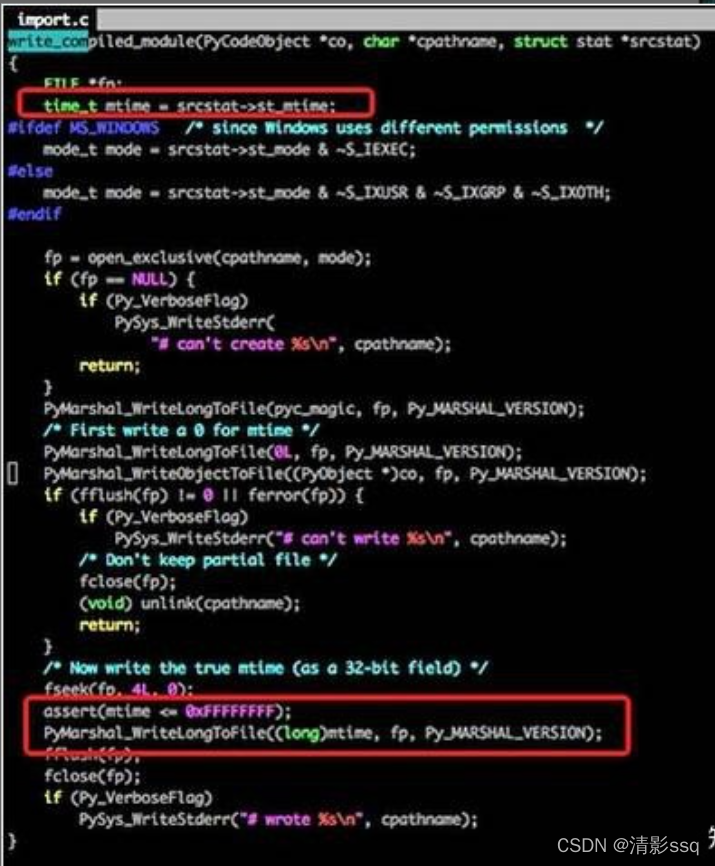
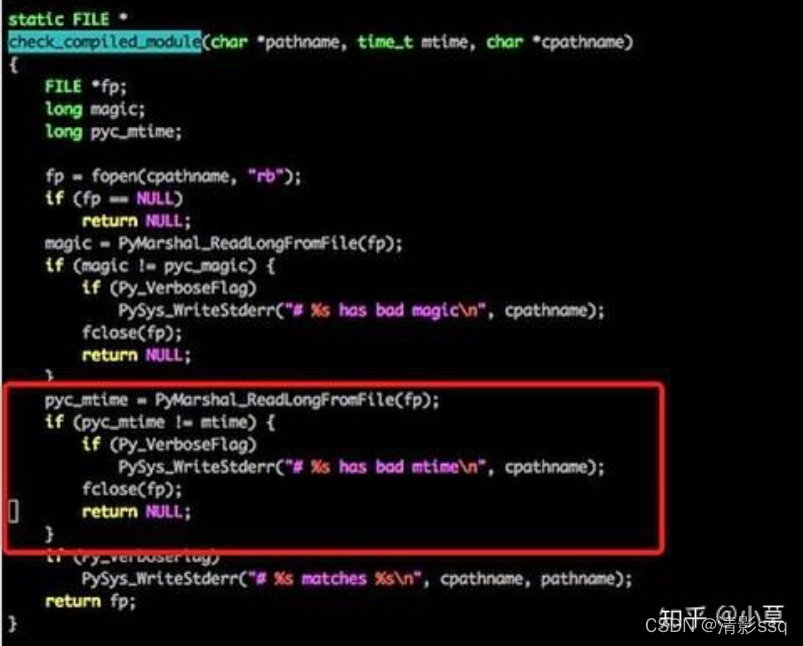
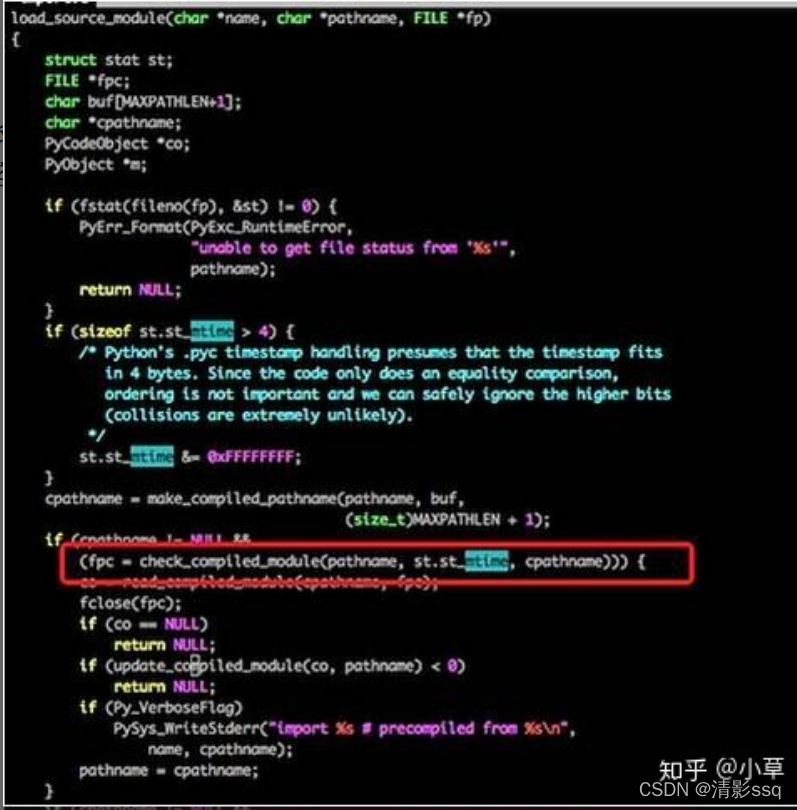
- 我们来看一下import过程的源码吧: 这段代码比较长,我们只来看我标注了的代码,其实他在写入pyc文件的时候,写了一个Long型变量,变量的内容则是文件的最近修改日期,同理,我们再看下载入pyc的代码: 不用仔细看代码,我们可以很清楚地看到原理,其实每次在载入之前都会先检查一下py文件和pyc文件保存的最后修改日期,如果不一致则重新生成一份pyc文件。
2.3 pyc文件的运行
- 如果你的程序只import了标准库,或者import的库都是用pip安装的,那么ok,你可以直接运行.pyc文件:
python -m test.py后生成对应的test.pyc文件(字节码),然后用python test.pyc解释器解释执行。 - 如果你的程序还import了你自己的库,比如通目录下的其它.py文件,要运行.pyc文件,需要修改一点文件名。比如你的程序 import misc,这时,你要把misc.cpython-38.pyc这个文件名修改为misc.pyc后,才能正常执行的pyc程序。(这就是说,python的import,可以是一个py,也可以是pyc)
2.4 pyc文件的组成
pyc文件一般由3个部分组成:
- 最开始4个字节是一个Maigc int,标识此pyc的版本信息,不同的版本的 Magic 都在 Python/import.c 内定义
- 接下来四个字节还是个int,是pyc产生的时间(1970.01.01到产生pyc时候的秒数)
- 接下来是个序列化了的 PyCodeObject(此结构在 Include/code.h 内定义),序列化方法在 Python/marshal.c 内定义
3. python终端命令

-
python test.py,只会对自己写的函数产生.pyc文件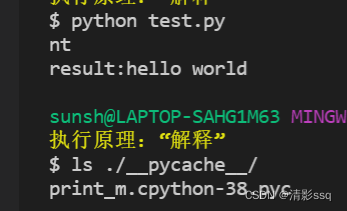
-
python -m test,模块执行,-m 类似import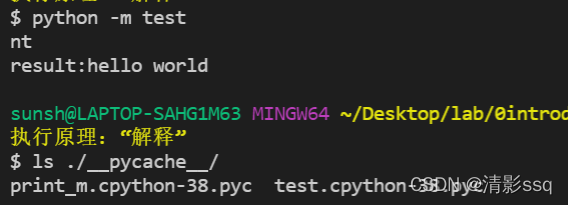
-
python -O test.py,优化生成pyc或pyo文件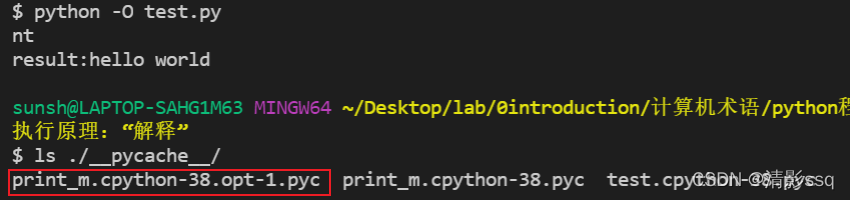
-
python ./__pycache__/test.cpython-38.pyc,执行pyc文件,首先将引入模块的文件修改名字,再执行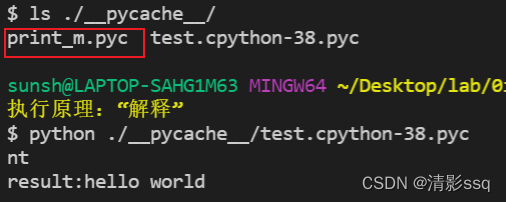
4.总结
- 其实Python是否保存成pyc文件和我们在设计缓存系统时是一样的,我们可以仔细想想,到底什么是值得扔在缓存里的,什么是不值得扔在缓存里的。
- 在跑一个耗时的Python脚本时,我们如何能够稍微压榨一些程序的运行时间,就是将模块从主模块分开。(虽然往往这都不是瓶颈)
- 在设计一个软件系统时,重用和非重用的东西是不是也应该分开来对待,这是软件设计原则的重要部分。
我们如何能够稍微压榨一些程序的运行时间,就是将模块从主模块分开。(虽然往往这都不是瓶颈) - 在设计一个软件系统时,重用和非重用的东西是不是也应该分开来对待,这是软件设计原则的重要部分。
- 在设计缓存系统(或者其他系统)时,我们如何来避免程序的过期,其实Python的解释器也为我们提供了一个特别常见而且有效的解决方案。