大家好,作为爱学习的自己,我特意用python做了个测词汇量的小工具,让自己每天都能够快乐的学习!
1.页面分析
这次我们采用的是扇贝网来进行词汇量测试,如图:

我们还是老规矩,首先按F12打开开发者工具,然后点击开始。然后在name里面寻找到存有我们想要数据的网页,如图:
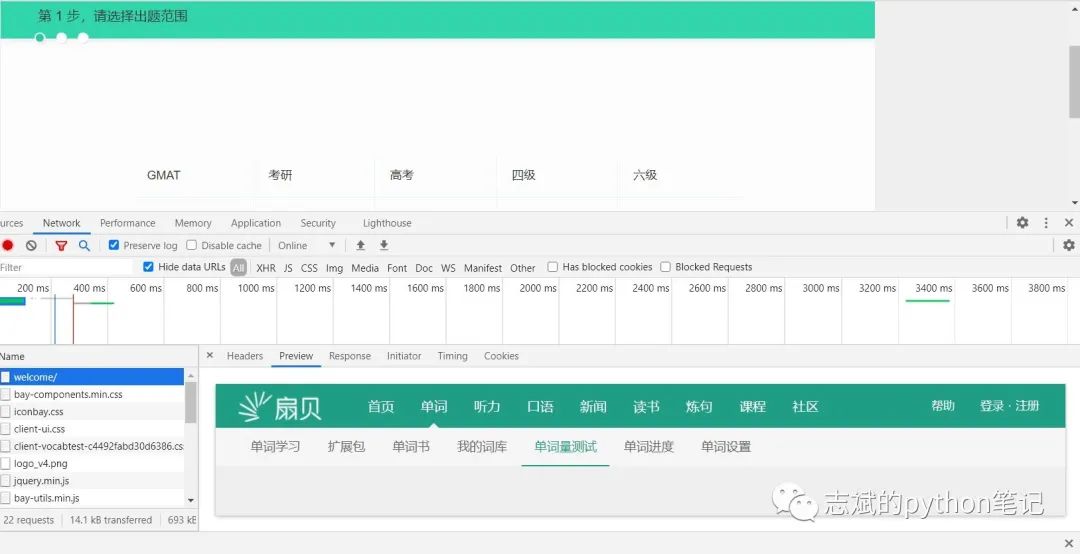
嗷,我们发现源网页中,并没有我们想要的数据,那么这个网页就是使用动态加载的网页(关于这类网页之后会专门出一篇文章来进行讲解,这里直接将解决办法),那么我们就需要勾选住“Preserve log”,然后重新刷新页面,然后观察name里面新增的网页,如图
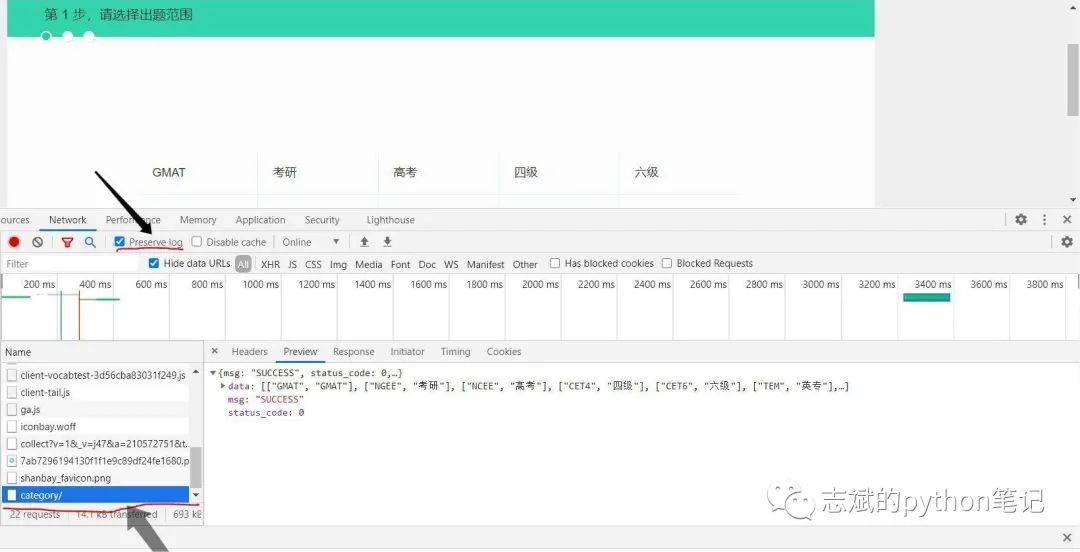
果然,我们发现了我们想要的数据,接下来我们随便点击一个进行下一步,我选择的是考研,然后找到存储我们想要的数据的网页,观察它的url,我们发现:
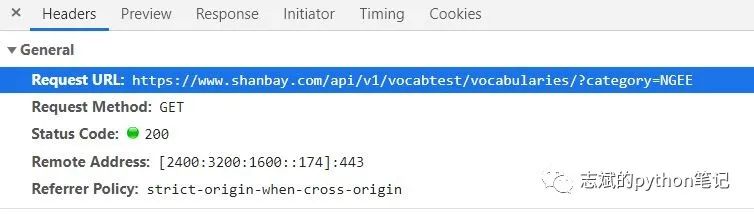
那个NGEE好熟悉啊!不就是我们第一步寻找到的数据嘛!我们用如下代码将url构造出来:
ceshi_danci = requests.get('https://www.shanbay.com/api/v1/vocabtest/vocabularies/?category='+ciku)
2.开始测试
我们已经找到了数据存放的网页,那么我们现在就可以直接对该网页发起请求然后获取数据,代码如下:
ceshi_danci = requests.get('https://www.shanbay.com/api/v1/vocabtest/vocabularies/?category='+ciku)
#获取本轮测试的50个单词
jiexi_ceshi_danci = ceshi_danci.json()我们将获取的单词,让用户开始进行测试,将用户认识和不认识的单词分别记录下来,对于认识的单词,给用户选项让用户再次验证自己的印象,此时仍将用户认识的单词和不认识的单词分别记录,最后生成一份报告给用户,部分代码如下:
a = 0
for i in jiexi_ceshi_danci['data']:
a = a + 1
print("\n第" + str(a) + '个:' + i['content']) # 加一个\n,用于换行。
# 让用户输入自己是否认识。
answer = input('认识请敲Y,否则敲Enter:')
# 如果用户认识:
if answer == 'Y':
renshi_danci.append(i['content'])
# 就把这个单词,追加进列表know_danci。
know_danci.append(i)
else:
# 就把这个单词,追加进列表no_danci。
no_danci.append(i)
总结
这篇文章难度不大,但是非常考验大家的基本功,数据的提取较为麻烦,希望大家可以跟着代码好好复现一下,温故而知新!