nltk_data --wordnet
1. Resource wordnet not found.Please use the NLTK Downloader to obtain the resource:
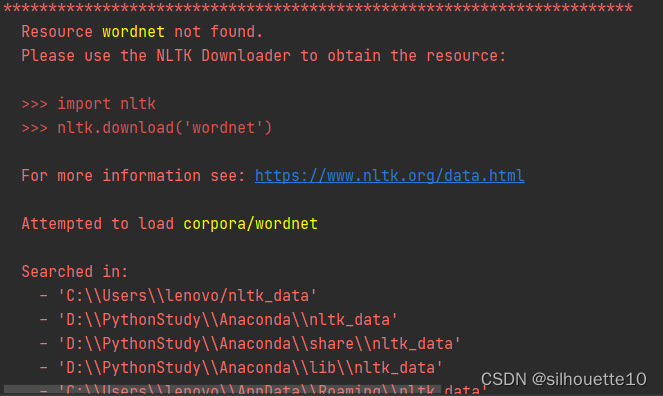
错误1:
Resource wordnet not found.
Please use the NLTK Downloader to obtain the resource:
如下图:
解决办法:
自己在终端下载wordnet,然后放在他搜索的文件夹中即可。我选择的是D:\PythonStudy\Anaconda\nltk_data
然后在下载的时候遇到了第二个错误
2. [nltk_data] Error loading wordnet: <urlopen error [Errno 11004]
错误2. [nltk_data] Error loading wordnet: <urlopen error [Errno 11004]
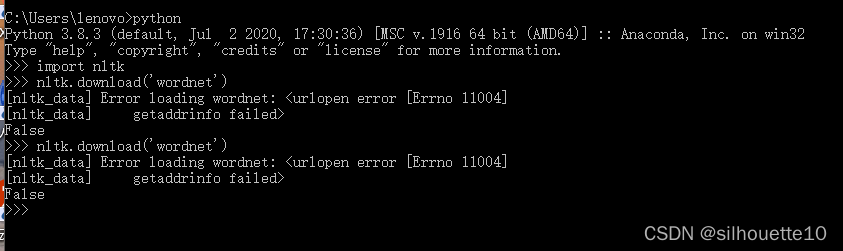
解决办法:
在C:\Windows\System32\drivers\etc 路径下找到hosts文件,在最后一行添加:199.232.68.133 raw.githubusercontent.com,然后重新运行代码即可。
import nltk
nltk.download('wordnet')
(若这个IP地址失效,可重新查询:
打开ip查询网站
https://www.ipaddress.com/
输入如下代码
raw.githubusercontent.com
使用查询到的ip地址进行替换
)
但是。。。。有时候还会遇到网不好的问题,或者其他原因导致下面错误
3.[nltk_data] Error loading wordnet: <urlopen error [WinError 10054]
错误3.[nltk_data] Error loading wordnet: <urlopen error [WinError 10054]

这时候可采取离线下载的方法,自己手动下载wordnet语料库,然后放在指定路径上。
方法一:
手动下载wordnet语料库,下载地址是https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/corpora/wordnet.zip。其它语料库同样可以在路径:http://www.nltk.org/nltk_data/ 中找到。
将下载好的包解压后放在nltk可以找到的位置【这个位置就是第一幅图中的Searched in :中的路径】
最后得到的路径就是D:\PythonStudy\Anaconda\nltk_data\corpora\wordnet
注意:中间多一个目录corpora(这个和原始nltk_data数据目录有关,这里的方法相当于只下载了其中一个数据集,方法二相当于把所有数据都下载了,自己选用的方法一)
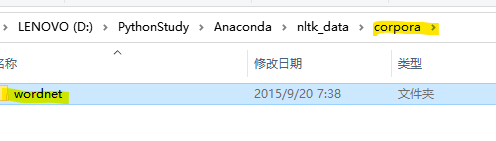
方法二:
离线下载NLTK Data,地址:https://github.com/nltk/nltk_data
将解压文件后得到的packages文件夹目录下面的所有文件(防止再少什么文件报错)按照第一幅图中的Searched in :中的路径挑选一个,复制到里面即可。
全文参考:
https://blog.csdn.net/weixin_44056753/article/details/118873282
https://blog.csdn.net/liu16659/article/details/109691534
https://blog.csdn.net/Gabriel_wei/article/details/113360751