多线程爬取小说
例子:
网站:https://www.17k.com/
随便找个小说爬

代码:
这是用佛如循环一个一个的爬取
import time
from concurrent.futures import ThreadPoolExecutor
from lxml import etree
import requests
url ="https://www.17k.com/list/3379384.html"
resq = requests.get(url)
resq.encoding = "utf-8"
ht = resq.text
ee= etree.HTML(ht)
nr = ee.xpath("/html/body/div[5]/dl/dd/a/@href")
url1 ="https://www.17k.com"
def getwz(surl):
resq1 = requests.get(surl)
resq1.encoding = "utf-8"
nr1 = resq1.text
ee1 = etree.HTML(nr1)
wz = ee1.xpath("//*[@id='readArea']/div[1]/div[2]/p/text()")
print(wz)
t1= time.time()
for urll in nr:
surl =url1+urll
getwz(surl)
t2 = time.time()
print(t2-t1)#这是测试时间
这是上面的运行时间
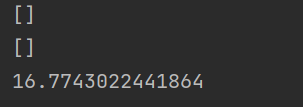
可以看到效率是极其低下的
另一种
下面是利用线程池创建多个线程进行爬取
import time
from concurrent.futures import ThreadPoolExecutor #创建线程池所需的模块
from lxml import etree
import requests
url ="https://www.17k.com/list/3379384.html"
resq = requests.get(url)
resq.encoding = "utf-8"
ht = resq.text
ee= etree.HTML(ht)
nr = ee.xpath("/html/body/div[5]/dl/dd/a/@href")
url1 ="https://www.17k.com"
def getwz(surl):
resq1 = requests.get(surl)
resq1.encoding = "utf-8"
nr1 = resq1.text
ee1 = etree.HTML(nr1)
wz = ee1.xpath("//*[@id='readArea']/div[1]/div[2]/p/text()")
print(wz)
if __name__ == '__main__':
t1=time.time()
with ThreadPoolExecutor(50) as t: #创建线程池的格式,50是代表这个线程池有50个线程
for urll in nr:
surl = url1 + urll
t.submit(getwz,surl) #让对象t去调用函数 这样多个函数同时进行效率高
t2= time.time()
print(t2-t1)
0.9097669124603271
这是程序运行时间,可以看出效率高了很多
用异步操作爬取
并将内容存入文件
代码:
import asyncio
import aiohttp
import requests
from lxml import etree
url ="https://www.17k.com/list/3379384.html"
resq = requests.get(url)
resq.encoding = "utf-8"
ht = resq.text
ee= etree.HTML(ht)
nr = ee.xpath("/html/body/div[5]/dl/dd/a/@href")
url1 ="https://www.17k.com"
async def getwz(surl):
async with aiohttp.ClientSession() as session:
async with session.get(surl) as resq:
resq.encoding="utf-8"
nr1 = await resq.text()
ee1 =etree.HTML(nr1)
name = ee1.xpath('//*[@id="readArea"]/div[1]/h1/text()') #文章题目
name1 = ''.join(name) #将列表转化成字符串
nr2 = ee1.xpath("//*[@id='readArea']/div[1]/div[2]/p/text()")
nr3= ''.join(nr2) #文章内容
with open(name1+".txt", mode="w",encoding="utf-8") as f:
f.write(nr3) #写入
async def main():
tasks=[]
for urll in nr:
surl = url1 + urll
tasks.append(asyncio.create_task(getwz(surl)))
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
if __name__ == '__main__':
asyncio.run(main())
爬取的效率也很快
总结
多线程爬取和与异步操作爬取效率很高