1、Beautiful Soup简介
1.1含义
Beautiful Soup 是?个可以从HTML或XML?件中提取数据的Python库,它可以通过你喜欢的转换器实现惯?的?档导航,查找,修改?档的?式.
Beautiful Soup是利?此关系:HTML的属性都具有结构上的层级关系, ?且有css和id属性,来进?提取的
1.2解析器
使用BeautifulSoup解析代码,能够发出一个BeautifulSoup的对象,并按照标准的缩进格式的输出结构
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,一般常用lxml HTML 解析器
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库、执行速度适中、文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, [“lxml”, “xml”])、BeautifulSoup(markup, “xml”) | 速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
2、Beautiful Soup包的安装与导?
Beautiful Soup包的安装
pip install bs4
Beautiful Soup包的导?
from bs4 import BeautifulSoup
3、中文文档
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
4、构建对象
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment .
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法.
5、一个简单的Beautiful Soup例子
计划下载“夜的命名术”此小说,但是网页里面广告弹窗过多,打算自己爬取,此次主要是获取规整的页面结构
5.1获取网页源码
#导入所需要的包
import requests
from bs4 import BeautifulSoup
#网址
url = "http://www.shuquge.com/txt/3478/index.html"
#构造虚拟浏览器
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
r = requests.get(url,headers=headers)
# 给encoding属性重新赋值, 用推测的编码去解析网页内容
r.encoding = r.apparent_encoding
#查看网页源代码
r.text
 结构很乱,很难看明白
结构很乱,很难看明白
5.2查看网页源码的类型,并将其变成BeautifulSoup类型
#查看源码类型,是文本类型
type(r.text)

# 为了在这个字符串中高效的搜索出我们需要的内容
# 利用BeautifulSoup 将这个字符串改变成BeautifulSoup类型
bs = BeautifulSoup(r.text,"lxml")
#查看bs类型
type(bs)
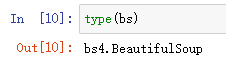
5.3 查看bs中内容
bs中内容变得规整,符合HTML的页面结构,方便阅读