Ҫ��:
��ȡ����top250�ĵ�Ӱ��Ϣ,����:
����
����
����
���
����
����
��������
����
������
����Щ��Ӱ��Ϣ������һ����Ϊmovie.txt���ļ���
˼·:
1.��requests��ȡԴ����
2.��re��ȡ��Ϣ
3.����õ����ݴ洢��movie.txt��
ʾ�������:chrome
1.�ȵ����,����url(requestsҪ��ǰ��װ,ָ��pip install requests,û��pip�İٶ��������)?
import requests
import re
import os
import time
# os��timeģ�鵽ʱ����õ�
url = "https://movie.douban.com/top250"2.�������,���붹��ҳ��(movie.douban.com/top250),����f12,��������½���:
?Ȼ��,�ҵ�����(Network),������:
 ?
?
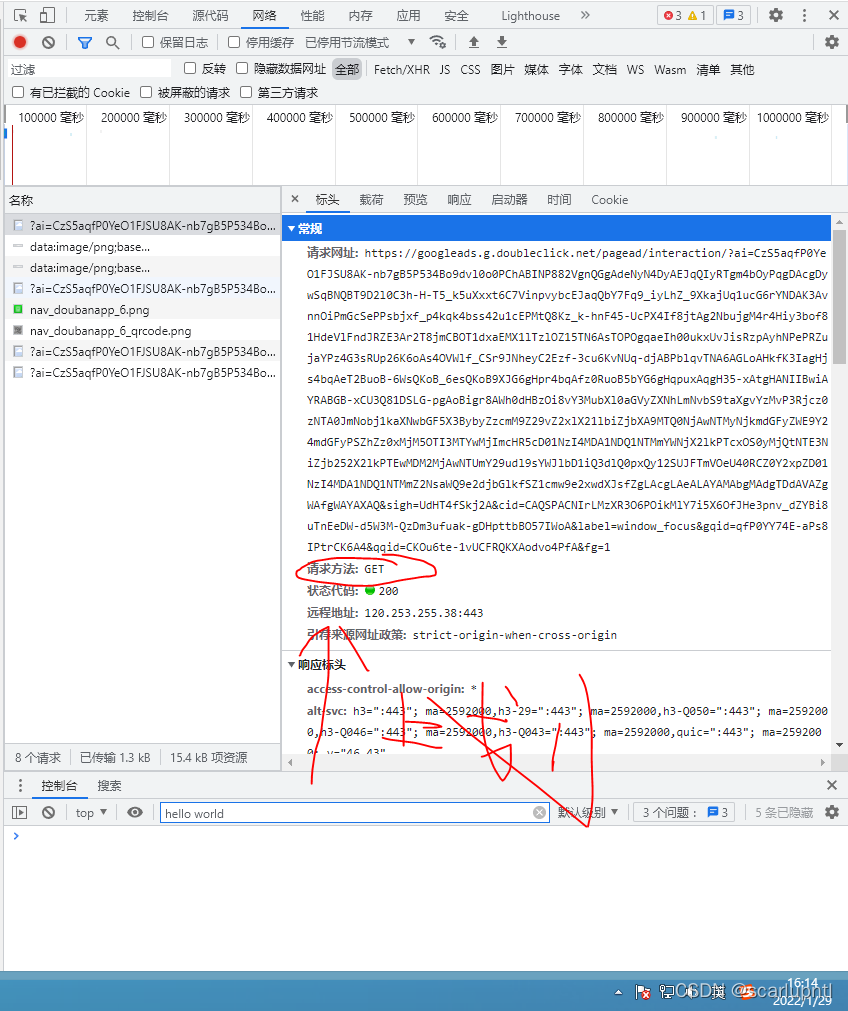
�����һ����Ŀ(û�о�ˢ��),�ڡ���ͷ�����ҵ�user-agent,��������,��һ��Ҫ�õ�:
 ?
?
?3.��Ϊ�����з�������,��������Ҫ�ֶ�ָ��headers:����Ҳ�ܼ�,ֻҪ�������user-agent�������Ϳ�����(��ͬϵͳ��headers��һ��,��Ҫ���в鿴)
headers = {
"user-agent":
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}����,����Ҫȥ�鿴��ҳ������,������Ϊget��post,�����ǿ�user-agent�����������
���Կ���������get����,����,��������������ȡ��ҳԴ����requests.get(url��ַ,���headers),��Ϊget�����ķ���ֵ�����ı�,����������text����+һ������������Դ�����ı�
resp = requests.get(url, headers=headers)
page_content = resp.text # page_content ����Դ����?
3.���Ϸ��������Ժ�,re���ѵ��������ʽ������,�����һᾡ��������~
�ص������,ˢ����ҳ,�����ῴ��һ����"top250"����,��
?����"��Ӧ",�л�����ҳԴ����,��ctrl+shift+f��������
 ?
?
?Ȼ��,����Ҫ�˽�һ����λ��������������
(һ)
.*? �����ʶ������ľ�����ɴӱ�ʶ��ǰ�������������ʶ�����������
�ٸ�����:
"�ֵ���ʱ�����Ϸ��?�ֵ�����,����Ϸ��,�����Ϻ�?ιιι,���ڲ��ڰ�,����Ϸ��ͷ��?"
������,�������������ʽ��: �ֵ�.*?��Ϸ �Ļ�
��ƥ��ľ���:
�ֵ���ʱ�����Ϸ
�����DZ��,��������� ��? ����ƥ��
�������˰�?
(��)
?P �����ʶ���ܺ�����,���ǾͰ�������һ���������;Ϳ�����,��ʽ��(?P<����>����)
���������������˵,������ȡ��ʶ��.*?�е�����,Ҳ����"��ʱ���"����ַ���,�����ǿ�����ôд:
�ֵ�(?P<string>.*?)��Ϸ
�������ǵ�<string>�оͳɹ��������м�IJ���~
������ô��������ٽ�?�˽����,��������ȡ��Ӱ����Ϣ,������������һ����Ӱ������(�������Ե�һ����Ϊ��):
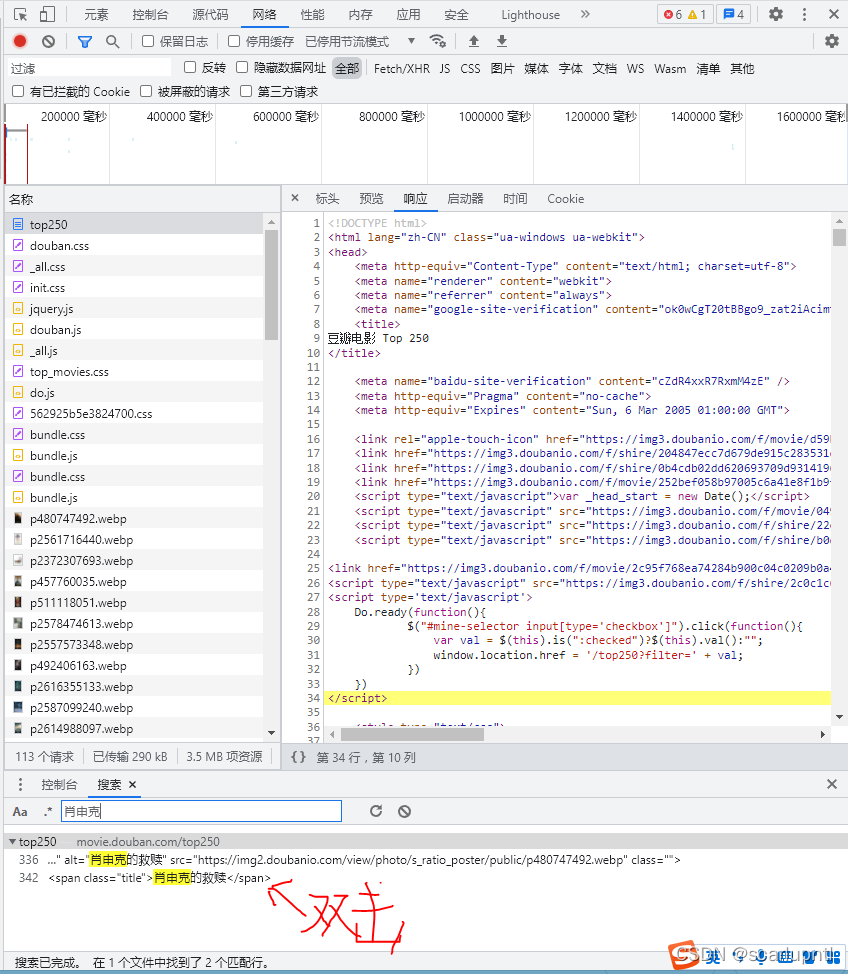
 ?
?
Ȼ��,���Ƿ���,�ⲿ��Ӱ���е����ݶ���������,��֮ǰ����������ʶ��,���Ǿ��ܰ���Щ����д������
������д��,�����ο�.��Ϊ��װ��?��˼·�������д���ڵ��û��Ҫ��
obj = re.compile('<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?'
'<div class="bd">.*?<p class="">(?P<dy>.*?) .*?<br>(P<year>.*?) '
'.*?/ (?P<country>.*?) .*? (?P<lx>.*?)</p>'
'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
'.*?<span>(?P<people>.*?)</span>'
'.*?</div>.*?<span class="inq">(?P<xcy>.*?)</span>', re.S)��obj�е�finditer��������ȡ���,ͬ����������
result = obj.finditer(page_content)д���ļ�,Ҫ����obj�е�name dy�ȱ���,��.group("������")����
������ڿ�ͷ������һ��s=0����ͳ������
with open("movie.txt", mode="a", encoding="utf-8") as f:
for it in result:
s+=1
f.write("����:"+str(s)+"\n")
f.write("��Ӱ��:"+it.group("name").strip()+"\n")
f.write("����:"+it.group("country").strip()+"\n")
f.write("���:"+it.group("year").strip()+"\n")
f.write(it.group("dy").strip()+"\n")
f.write("����:"+it.group("score").strip()+"\n")
f.write("��������:"+it.group("people").strip()+"\n")
f.write("����:"+it.group("lx").strip()+"\n")
f.write("������:"+it.group("xcy").strip()+"\n")
f.write("----------------------------------\n")
f.write("\n")
print("�ѳɹ���ȡ", s, "���Ӱ��Ϣ")��Ҫ���ǰ�resp�ص�,��Ȼ�ᱻ��ip
resp.close()�����������ǻᷢ��һ������,��movie.txt��ֻ��һҳ������,��ʱ��Ҫ��Ϊ�Լ�����������,��ҳ�е���һҳ����ַ��:

 ?
?
�����˰�?ÿ��һҳ���е�startֵ�ͻ�����25,�������Ǹ�дһ�¿�ͷ,�ǵðѺ���Ĵ����������
for i in range(10):
a = i * 25
url = "https://movie.douban.com/top250?start="+str(a)+"&filter="?
������û������!
����,����ֻ��Ҫ�Ѵ�������ɫһ�¾Ϳ�����
��������д���ʱ�����õ�"a"��ģʽ,������д��ͻ���Ϣ��ը,�������ǵ�osģ�����������,��os.path.exists�����ж��ļ��Ƿ����,�о�ɾ��
if not os.path.exists("./movie.txt"):
pass
else:
os.remove("./movie.txt")��Ϊ��ϰ�����ն����г���,�����Ҽ�����os.system("cls"),linux����clear,Ȼ��,Ϊ���ó���һ��ʼ��������,���ڿ�ͷ���˼���
os.system("cls")
print("��3���ʼ��ȡ����top250��Ӱ��Ϣ...")
time.sleep(1)
print("3...")
time.sleep(1)
print("2...")
time.sleep(1)
print("1...")
time.sleep(1)����,��������!��������:
import requests
import re
import os
import time
s = 0
os.system("@echo off")
# ɾ���ļ������ظ��ı�
if not os.path.exists("./movie.txt"):
pass
else:
os.remove("./movie.txt")
os.system("cls")
print("��3���ʼ��ȡ����top250��Ӱ��Ϣ...")
time.sleep(1)
print("3...")
time.sleep(1)
print("2...")
time.sleep(1)
print("1...")
time.sleep(1)
for i in range(10):
a = i * 25
url = "https://movie.douban.com/top250?start="+str(a)+"&filter="
headers = {
"user-agent":
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
resp = requests.get(url, headers=headers)
page_content = resp.text # page_content ����Դ����
obj = re.compile('<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?</span>.*?'
'<div class="bd">.*?<p class="">(?P<dy>.*?) .*?<br>(?P<year>.*?) '
'.*?/ (?P<country>.*?) .*? (?P<lx>.*?)</p>'
'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
'.*?<span>(?P<people>.*?)</span>'
'.*?</div>.*?<span class="inq">(?P<xcy>.*?)</span>', re.S)
result = obj.finditer(page_content)
with open("movie.txt", mode="a", encoding="utf-8") as f:
for it in result:
s+=1
f.write("����:"+str(s)+"\n")
f.write("��Ӱ��:"+it.group("name").strip()+"\n")
f.write("����:"+it.group("country").strip()+"\n")
f.write("���:"+it.group("year").strip()+"\n")
f.write(it.group("dy").strip()+"\n")
f.write("����:"+it.group("score").strip()+"\n")
f.write("��������:"+it.group("people").strip()+"\n")
f.write("����:"+it.group("lx").strip()+"\n")
f.write("������:"+it.group("xcy").strip()+"\n")
f.write("----------------------------------\n")
f.write("\n")
print("�ѳɹ���ȡ", s, "���Ӱ��Ϣ")
resp.close()
os.system("cls")
print("��ȡ���,���ڱ�Ŀ¼�µ�movie.txt�鿴")
���˲���,��ӭ�����d(゚?゚�g)