目录
学习记录:
一、目标网址分析
目标网址:化妆品生产许可信息管理系统服务平台?, 进入网址:
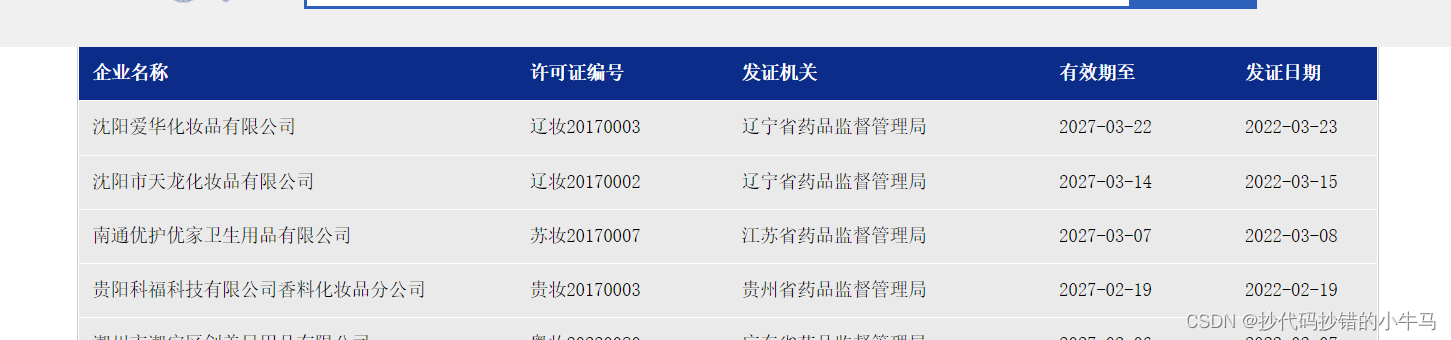
?随便点击一个公司,会跳转一个新的页面:想要收集的数据也在里面。

现在,可以先看看网页的源码:

在这里ctr+f定位我们想要的数据,发现并没有搜索到,再此处找到数据:
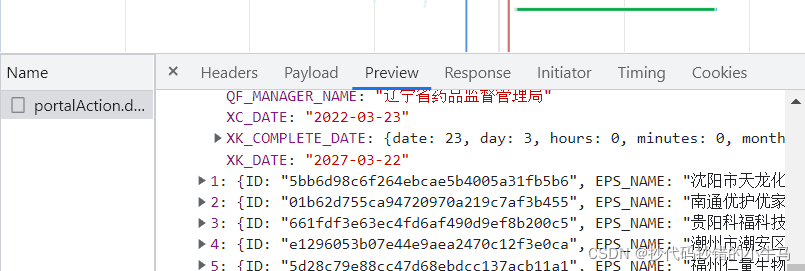
?再对其检查:
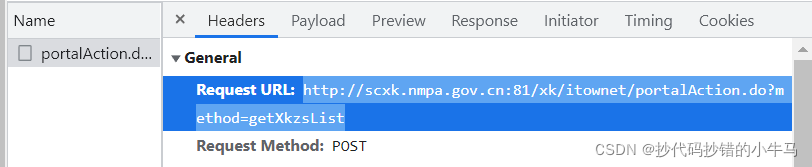
?参数:多找几页后
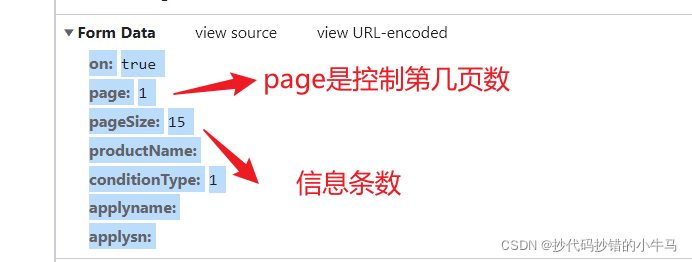
?打开返回给我们的数据:
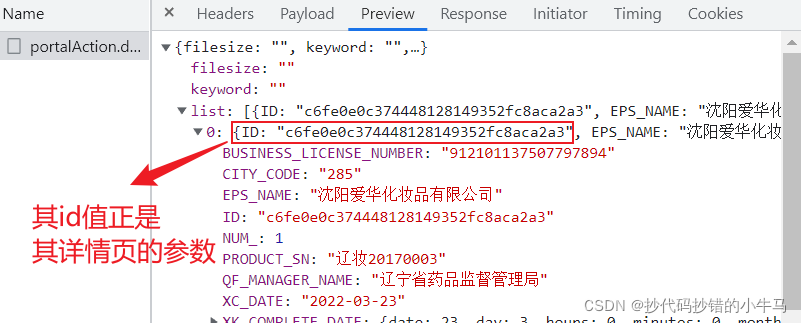
?来到其详情页:
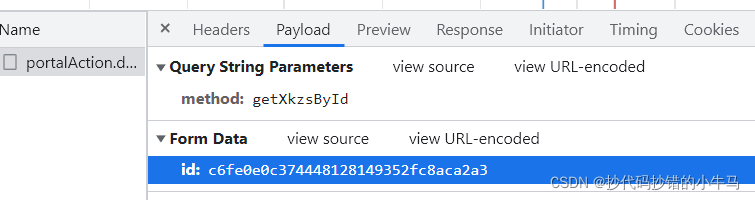
?我们将返回的json数据复制出来,提取数据:

?发现是个字典形式:
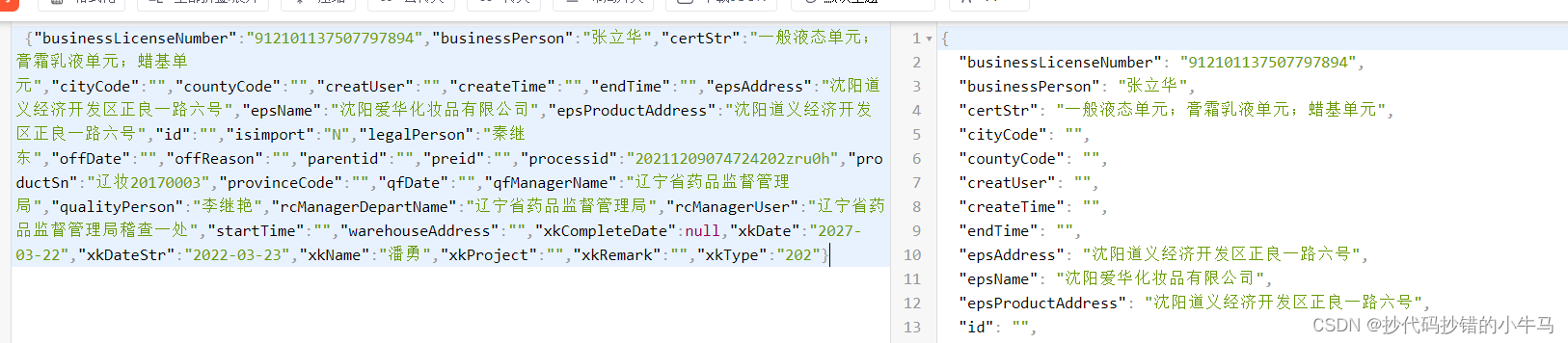
?哦可,可以代码了
二、代码部分
1)构造主页面的url参数,并通过requests拿到json 数据:
import requests
import csv
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'
}
def get_down(page):
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
data = {
'on': 'true',
'page': page,
'pageSize': 15,
'productName': '',
'conditionType': 1,
'applyname': '',
'applysn': ''
}
resp = requests.post(url=url, headers=headers, data=data).json()提取出详情页需要的ID值:
dict_list = resp['list']
for ids in dict_list:
_id = ids['ID']2)对详情页请求:
url2 = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
data2 = {
'id': _id
}
resp2 = requests.post(url=url2, headers=headers, data=data2).json()?3)提取数据:
com_name = resp2['epsName'] # 企业名称
number = resp2['productSn'] # 许可证编号
allow_p = resp2['certStr'] # 生产许可证项目
epsAddress = resp2['epsAddress'] # 企业住址
epsProductAddress = resp2['epsProductAddress'] # 生产地址
businessLicenseNumber = resp2['businessLicenseNumber'] # 信用编号
legalPerson = resp2['legalPerson'] # 法定代表人
qfManagerName = resp2['qfManagerName'] # 发证机关
xkDate = resp2['xkDate'] # 有效期至
xkDateStr = resp2['xkDateStr'] # 发证日期总代吗:
"""
2022年
CSDN:抄代码抄错的小牛马
"""
import requests
import csv
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'
}
def get_down(page):
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
data = {
'on': 'true',
'page': page,
'pageSize': 15,
'productName': '',
'conditionType': 1,
'applyname': '',
'applysn': ''
}
resp = requests.post(url=url, headers=headers, data=data).json()
dict_list = resp['list']
for ids in dict_list:
_id = ids['ID']
url2 = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
data2 = {
'id': _id
}
resp2 = requests.post(url=url2, headers=headers, data=data2).json()
f = open('数据.csv', mode='a', encoding='utf-8', newline='') # newline=''可以免空行写入
csvwriter = csv.writer(f)
com_name = resp2['epsName'] # 企业名称
number = resp2['productSn'] # 许可证编号
allow_p = resp2['certStr'] # 生产许可证项目
epsAddress = resp2['epsAddress'] # 企业住址
epsProductAddress = resp2['epsProductAddress'] # 生产地址
businessLicenseNumber = resp2['businessLicenseNumber'] # 信用编号
legalPerson = resp2['legalPerson'] # 法定代表人
qfManagerName = resp2['qfManagerName'] # 发证机关
xkDate = resp2['xkDate'] # 有效期至
xkDateStr = resp2['xkDateStr'] # 发证日期
csvwriter.writerow([com_name, number, allow_p, epsAddress,
epsProductAddress, businessLicenseNumber, legalPerson, qfManagerName, xkDate,
xkDateStr]) # 列表写入
f.close()
def main():
stat_page = int(input("请输入起始页码:"))
end_page = int(input("请输入结束页码:"))
for page in range(stat_page, end_page + 1):
get_down(page)
if __name__ == '__main__':
main()
运行看看:

?
记录~~~

?