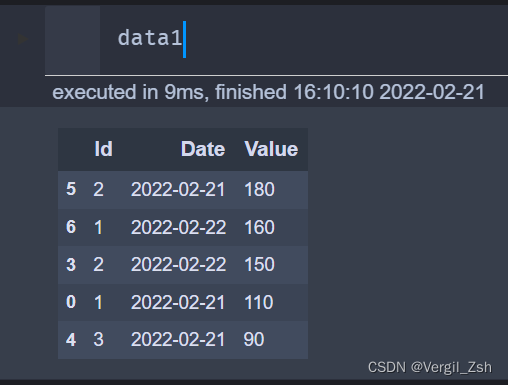
pandas对数据去重,并保留最大值
pandas **drop_duplicates()**函数使用方法
DataFrame.duplicates(subset,keep,inplace)
・subset参数用来指定识别重复的列标签/列标签序列,当未指定时默认比较整行的所有列来判别是否有重复
・keep参数用来指定如何标记重复行,它的值有三个: first,last,False.当选择first时,重复行中除了第一次出现的全部标记为True(保留第一次出现的);当选择last时,重复行中除最后一次出现的全部标记为True;(保留最后一次出现的),当选择False时,所有重复行都标记为True;
・inplace参数时决定文本对象直接删除重复行(inplace=True,需显示指定),还是返回一个文本对象的副本并删除了对应的重复行(inplace=False,为默认情况)
直接使用drop_duplicates()不能直接实现保留最大值,需要进行一下小小的变化
直接上代码
我的做法是通过降序value,然后使用drop_duplicates函数,删除具有重复Date和id值的值
data.sort_values('Value', ascending=False).drop_duplicates(subset=['Date', 'Id'], keep='first')
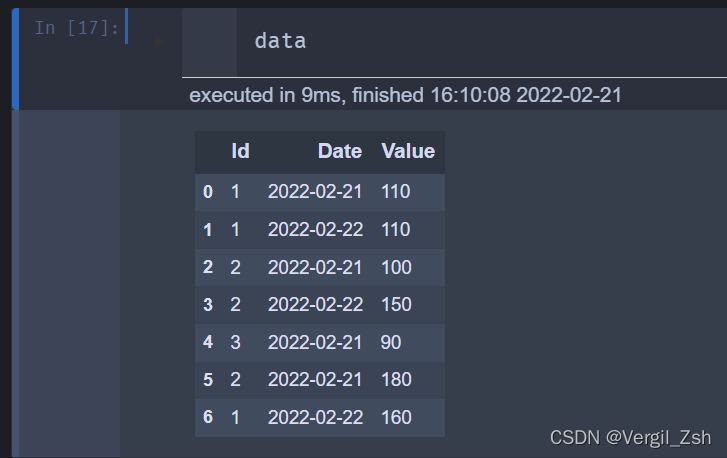
去重前:
去重后: