对于语音转文字的实现,可以调用如科大讯飞,百度之类的API实现,如果自己实现思路也非常简单
第一步将汉字转化为拼音,第二步通过拼音调用相对应声调的音频文件,以下介绍详细的实现方法。
参考文章链接:https://www.v2ex.com/t/393743
全文Github资源地址:https://github.com/wenyichuan/-python
运行环境
Python3.x
Unicode编码表
语音文件
Pygame,pypinyin,unidecode库
一、前置工作
1、在进行语音转文字功能前首先需要统计汉语中一共有多少个音节
此项工作前置条件
安装pypinyin,unidecode,pygame库(可通过cmd界面下Pip install安装)
在百度搜索获取汉字列表复制粘贴到同目录下的all.txt文件
from pypinyin import pinyin
from unidecode import unidecode
import pypinyin
import re
import json
import collections
import itertools
chars = [] # 存储所有汉字
with open("all.txt", "r") as file:
for line in file:
try:
chars.append(line.strip())
except:
pass
# 将每个字符映射到拼音
l = list(map(lambda x: pinyin(x, heteronym=True,strict=True,style=pypinyin.NORMAL), chars))
# 扁平表
l = list(itertools.chain(*list(itertools.chain(*l))))
# 将Unicode解码为ASCII
l = list(map(unidecode, l))
# 删除重复
syllables = list(set(l))
# 过滤器无效拼音
r = re.compile("[a-z]+")
syllables = list(filter(r.match, sorted(syllables)))
# 建立字典
d = {}
for i in syllables:
start = i[0]
if d.get(start) == None:
d[start] = [i]
else:
d[start].append(i)
od = collections.OrderedDict(sorted(d.items()))
# 写JSON表示法
f = open("./result.json","w")
dump = json.dumps(od, indent=4)
print(dump)
f.write(dump)
f.close()
print(len(syllables))
最终可提取出汉字一共有419个音节如下
{
“a”: [
“a”,
“ai”,
“an”,
“ang”,
“ao”
],
“b”: [
“ba”,
“bai”,
“ban”,
“bang”,
“bao”,
“bei”,
“ben”,
“beng”,
“bi”,
“bian”,
“biao”,
“bie”,
“bin”,
“bing”,
“bo”,
“bu”
],
“c”: [
“ca”,
“cai”,
“can”,
“cang”,
“cao”,
“ce”,
“cen”,
“ceng”,
“cha”,
“chai”,
“chan”,
“chang”,
“chao”,
“che”,
“chen”,
“cheng”,
“chi”,
“chong”,
“chou”,
“chu”,
“chua”,
“chuai”,
“chuan”,
“chuang”,
“chui”,
“chun”,
“chuo”,
“ci”,
“cong”,
“cou”,
“cu”,
“cuan”,
“cui”,
“cun”,
“cuo”
],
“d”: [
“da”,
“dai”,
“dan”,
“dang”,
“dao”,
“de”,
“dei”,
“den”,
“deng”,
“di”,
“dia”,
“dian”,
“diao”,
“die”,
“ding”,
“diu”,
“dong”,
“dou”,
“du”,
“duan”,
“dui”,
“dun”,
“duo”
],
“e”: [
“e”,
“ei”,
“en”,
“eng”,
“er”
],
“f”: [
“fa”,
“fan”,
“fang”,
“fei”,
“fen”,
“feng”,
“fiao”,
“fo”,
“fou”,
“fu”
],
“g”: [
“ga”,
“gai”,
“gan”,
“gang”,
“gao”,
“ge”,
“gei”,
“gen”,
“geng”,
“gong”,
“gou”,
“gu”,
“gua”,
“guai”,
“guan”,
“guang”,
“gui”,
“gun”,
“guo”
],
“h”: [
“ha”,
“hai”,
“han”,
“hang”,
“hao”,
“he”,
“hei”,
“hen”,
“heng”,
“hm”,
“hng”,
“hong”,
“hou”,
“hu”,
“hua”,
“huai”,
“huan”,
“huang”,
“hui”,
“hun”,
“huo”
],
“j”: [
“ji”,
“jia”,
“jian”,
“jiang”,
“jiao”,
“jie”,
“jin”,
“jing”,
“jiong”,
“jiu”,
“ju”,
“juan”,
“jue”,
“jun”
],
“k”: [
“ka”,
“kai”,
“kan”,
“kang”,
“kao”,
“ke”,
“kei”,
“ken”,
“keng”,
“kong”,
“kou”,
“ku”,
“kua”,
“kuai”,
“kuan”,
“kuang”,
“kui”,
“kun”,
“kuo”
],
“l”: [
“la”,
“lai”,
“lan”,
“lang”,
“lao”,
“le”,
“lei”,
“len”,
“leng”,
“li”,
“lia”,
“lian”,
“liang”,
“liao”,
“lie”,
“lin”,
“ling”,
“liu”,
“lo”,
“long”,
“lou”,
“lu”,
“luan”,
“lun”,
“luo”,
“lv”,
“lve”
],
“m”: [
“m”,
“ma”,
“mai”,
“man”,
“mang”,
“mao”,
“me”,
“mei”,
“men”,
“meng”,
“mi”,
“mian”,
“miao”,
“mie”,
“min”,
“ming”,
“miu”,
“mo”,
“mou”,
“mu”
],
“n”: [
“n”,
“na”,
“nai”,
“nan”,
“nang”,
“nao”,
“ne”,
“nei”,
“nen”,
“neng”,
“ng”,
“ni”,
“nian”,
“niang”,
“niao”,
“nie”,
“nin”,
“ning”,
“niu”,
“nong”,
“nou”,
“nu”,
“nuan”,
“nun”,
“nuo”,
“nv”,
“nve”
],
“o”: [
“o”,
“ou”
],
“p”: [
“pa”,
“pai”,
“pan”,
“pang”,
“pao”,
“pei”,
“pen”,
“peng”,
“pi”,
“pian”,
“piao”,
“pie”,
“pin”,
“ping”,
“po”,
“pou”,
“pu”
],
“q”: [
“qi”,
“qia”,
“qian”,
“qiang”,
“qiao”,
“qie”,
“qin”,
“qing”,
“qiong”,
“qiu”,
“qu”,
“quan”,
“que”,
“qun”
],
“r”: [
“ran”,
“rang”,
“rao”,
“re”,
“ren”,
“reng”,
“ri”,
“rong”,
“rou”,
“ru”,
“rua”,
“ruan”,
“rui”,
“run”,
“ruo”
],
“s”: [
“sa”,
“sai”,
“san”,
“sang”,
“sao”,
“se”,
“sen”,
“seng”,
“sha”,
“shai”,
“shan”,
“shang”,
“shao”,
“she”,
“shei”,
“shen”,
“sheng”,
“shi”,
“shou”,
“shu”,
“shua”,
“shuai”,
“shuan”,
“shuang”,
“shui”,
“shun”,
“shuo”,
“si”,
“song”,
“sou”,
“su”,
“suan”,
“sui”,
“sun”,
“suo”
],
“t”: [
“ta”,
“tai”,
“tan”,
“tang”,
“tao”,
“te”,
“tei”,
“teng”,
“ti”,
“tian”,
“tiao”,
“tie”,
“ting”,
“tong”,
“tou”,
“tu”,
“tuan”,
“tui”,
“tun”,
“tuo”
],
“w”: [
“wa”,
“wai”,
“wan”,
“wang”,
“wei”,
“wen”,
“weng”,
“wo”,
“wu”
],
“x”: [
“xi”,
“xia”,
“xian”,
“xiang”,
“xiao”,
“xie”,
“xin”,
“xing”,
“xiong”,
“xiu”,
“xu”,
“xuan”,
“xue”,
“xun”
],
“y”: [
“ya”,
“yan”,
“yang”,
“yao”,
“ye”,
“yi”,
“yin”,
“ying”,
“yo”,
“yong”,
“you”,
“yu”,
“yuan”,
“yue”,
“yun”
],
“z”: [
“za”,
“zai”,
“zan”,
“zang”,
“zao”,
“ze”,
“zei”,
“zen”,
“zeng”,
“zha”,
“zhai”,
“zhan”,
“zhang”,
“zhao”,
“zhe”,
“zhei”,
“zhen”,
“zheng”,
“zhi”,
“zhong”,
“zhou”,
“zhu”,
“zhua”,
“zhuai”,
“zhuan”,
“zhuang”,
“zhui”,
“zhun”,
“zhuo”,
“zi”,
“zong”,
“zou”,
“zu”,
“zuan”,
“zui”,
“zun”,
“zuo”
]
}
2、然后根据所获取的音节信息进行语音库的录制
每个音节分为五个声调,平声、一声、二声、三声、四声,最终录制获得2062个音频
文件如下图:

3、进行完音频文件的收集后进行汉字转拼音的操作
我们需要将汉字先变为Unicode编码,然后通过在网上搜索下载的Unicode转拼音文件将Unicode转为拼音
文件如下图:

其中英文字母后的1,2,3,4,5分别表示1,2,3,4和平声
到此准备工作全部完成。
二、代码部分
代码部分整体思路分为两个部分
1、汉语转拼音
此部分输入参数为汉字字符串,返回是一个拼音字符串
def chinese_to_pinyin(x):
y = ''
dic = {}
with open("unicode_py.txt") as f:
for i in f.readlines():
dic[i.split()[0]] = i.split()[1]
for i in x:
i = str(i.encode('unicode_escape'))[-5:-1].upper()
try:
y += dic[i] + ' '
except:
y += 'XXXX '#表示非法字符
return y
运行结果如下图:

其中XXXX表示为非法字符的标点符号
2、拼音转语音
此部分需根据上一部分所获取的拼音字符串来调取单个音的音频文件,并用Pygame库提供的mixer方法将其组合为一个完整的发音
def make_voice(x):
pygame.mixer.init(frequency = 22050,size = -16,channels = 2,buffer = 4096)
#初始化混音器模块以进行声音加载和播放。默认参数可以被覆盖以提供特定的音频混合。关键字参数被接受。为了后向兼容性,将参数设置为零,使用默认值(可能会通过pre_init调用进行更改)。
#size参数表示每个音频采样有多少位。如果该值为负值,则将使用带符号的采样值。正值表示将使用未签名的音频采样。无效值引发异常。
#通道参数用于指定是使用单声道还是立体声。1为单声道,2为立体声。没有其他值被支持(负值被视为1,大于2的值被视为2)。
#缓冲区参数控制混音器中使用的内部采样的数量。默认值应该适用于大多数情况。它可以降低以减少延迟,但可能发生声音丢失。可以将其提高到更大值以确保播放不会跳过,但会对声音播放造成延迟。缓冲区大小必须是2的幂(如果不是,则将其舍入到下一个最接近的2的幂)。
voi = chinese_to_pinyin(x).split()
for i in voi:
if i == 'XXXX':#对于非法字符将其跳过
continue
pygame.mixer.music.load( "voice/"+i.lower() + ".wav")
#这将加载音乐文件名/文件对象并准备播放。如果音乐流正在播放,则会停止播放。这不会启动音乐播放。
pygame.mixer.music.play()
#这将播放加载的音乐流。如果音乐已经播放,它将被重新启动。
while pygame.mixer.music.get_busy() == True:
#当音乐流正在播放时返回True。当音乐闲置时,返回False。
pass
return None
while True:
p = input("请输入文字:")
make_voice(p)
3、完整代码如下
import pygame
def chinese_to_pinyin(x):
y = ''
dic = {}
with open("unicode_py.txt") as f:
for i in f.readlines():
dic[i.split()[0]] = i.split()[1]
for i in x:
i = str(i.encode('unicode_escape'))[-5:-1].upper()
try:
y += dic[i] + ' '
except:
y += 'XXXX '#表示非法字符
return y
def make_voice(x):
pygame.mixer.init(frequency = 22050,size = -16,channels = 2,buffer = 4096)
#初始化混音器模块以进行声音加载和播放。默认参数可以被覆盖以提供特定的音频混合。关键字参数被接受。为了后向兼容性,将参数设置为零,使用默认值(可能会通过pre_init调用进行更改)。
#size参数表示每个音频采样有多少位。如果该值为负值,则将使用带符号的采样值。正值表示将使用未签名的音频采样。无效值引发异常。
#通道参数用于指定是使用单声道还是立体声。1为单声道,2为立体声。没有其他值被支持(负值被视为1,大于2的值被视为2)。
#缓冲区参数控制混音器中使用的内部采样的数量。默认值应该适用于大多数情况。它可以降低以减少延迟,但可能发生声音丢失。可以将其提高到更大值以确保播放不会跳过,但会对声音播放造成延迟。缓冲区大小必须是2的幂(如果不是,则将其舍入到下一个最接近的2的幂)。
voi = chinese_to_pinyin(x).split()
for i in voi:
if i == 'XXXX':#对于非法字符将其跳过
continue
pygame.mixer.music.load( "voice/"+i.lower() + ".wav")
#这将加载音乐文件名/文件对象并准备播放。如果音乐流正在播放,则会停止播放。这不会启动音乐播放。
pygame.mixer.music.play()
#这将播放加载的音乐流。如果音乐已经播放,它将被重新启动。
while pygame.mixer.music.get_busy() == True:
#当音乐流正在播放时返回True。当音乐闲置时,返回False。
pass
return None
while True:
p = input("请输入文字:")
make_voice(p)
4、后期改进
此程序面对数字时会将其当作非法字符跳过,后期针对此问题参考网上实例,修改后得出以下程序
unitArab=(2,3,4,5,9)
unitStr=u'十百千万亿'
unitStr=u'拾佰仟万亿'
#单位字典unitDic,例如(2,'十')表示给定的字符是两位数,那么返回的结果里面定会包含'十'.3,4,5,9以此类推.
unitDic=dict(zip(unitArab,unitStr))
numArab=u'0123456789'
numStr=u'零一二三四五六七八九'
numStr=u'零壹贰叁肆伍陆柒捌玖'
#数值字典numDic,和阿拉伯数字是简单的一一对应关系
numDic=dict(zip(numArab,numStr))
def ChnNumber(s):
def wrapper(v):
'''针对多位连续0的简写规则设计的函数
例如"壹佰零零"会变为"壹佰","壹仟零零壹"会变为"壹仟零壹"
'''
if u'零零' in v:
return wrapper(v.replace(u'零零',u'零'))
return v[:-1] if v[-1]==u'零' else v
def recur(s,bit):
'''此函数接收2个参数:
1.纯数字字符串
2.此字符串的长度,相当于位数'''
#如果是一位数,则直接按numDic返回对应汉字
if bit==1:
return numDic[s]
#否则,且第一个字符是0,那么省略"单位"字符,返回"零"和剩余字符的递归字符串
if s[0]==u'0':
return wrapper(u'%s%s' % (u'零',recur(s[1:],bit-1)))
#否则,如果是2,3,4,5,9位数,那么返回最高位数的字符串"数值"+"单位"+"剩余字符的递归字符串"
if bit<6 or bit==9:
return wrapper(u'%s%s%s' % (numDic[s[0]],unitDic[bit],recur(s[1:],bit-1)))
#否则,如果是6,7,8位数,那么用"万"将字符串从万位数划分为2个部分.
#例如123456就变成:12+"万"+3456,再对两个部分进行递归.
if bit<9:
return u'%s%s%s' % (recur(s[:-4],bit-4),u"万",recur(s[-4:],4))
#否则(即10位数及以上),用"亿"仿照上面的做法进行划分.
if bit>9:
return u'%s%s%s' % (recur(s[:-8],bit-8),u"亿",recur(s[-8:],8))
return recur(s,len(s))
while True:
p = input("请输入数字:")
print(ChnNumber(p))
运行截图如下
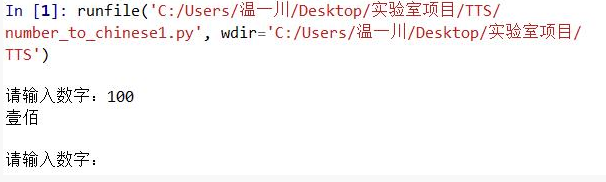
PS:鸽了好久的文章
