前言
很多时候使用爬虫时并不能或许到我们想要的信息,这是因为有些数据是用json代码书写,并通过xhr异步加载到网页。
因此我们并不能在页面中获取,此时可通过解析json代码获取目标信息。
一、如何找到目标xhr地址?
以抖音中的canvas图片信息为例,从下图可以看出,图中有数字出现,但定位到canvas中却并没附带这些数据:
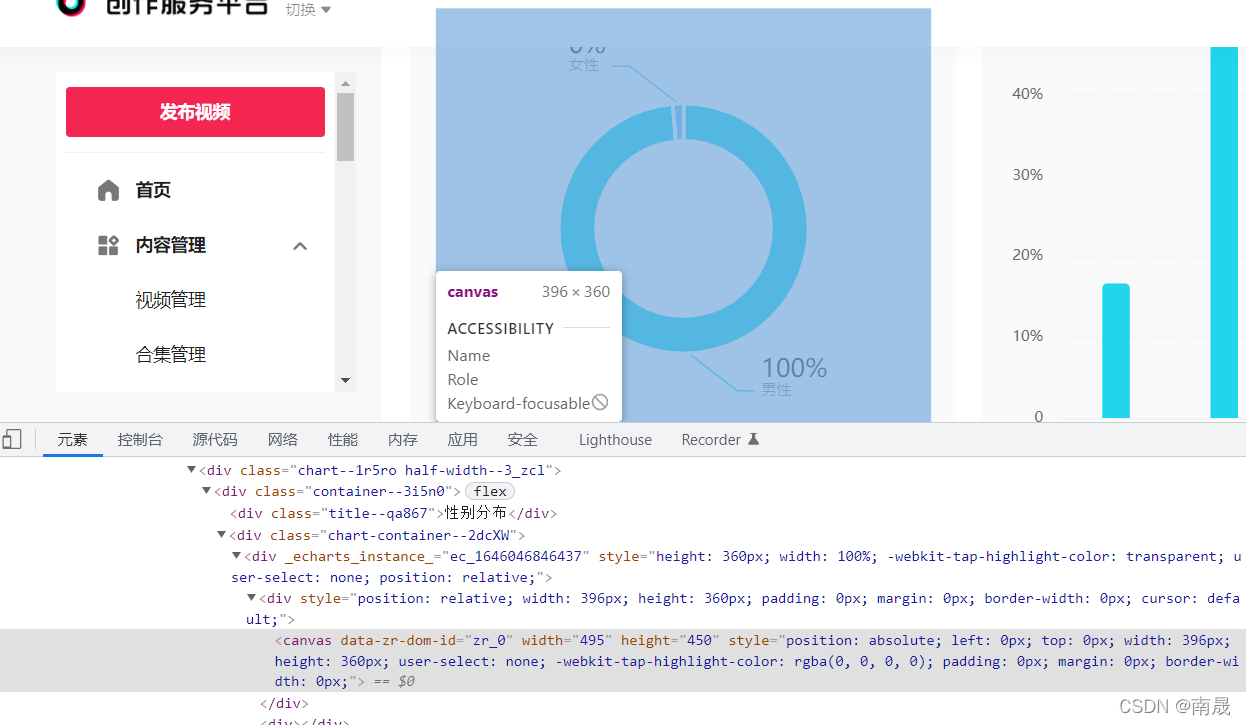 这个时候我们可以通过查找网络中的xhr请求,找到初始数据的链接,如下图操作,在出现的xhr请求中寻找到目标文件,如果xhr下没有所需数据,可以尝试刷新页面:
这个时候我们可以通过查找网络中的xhr请求,找到初始数据的链接,如下图操作,在出现的xhr请求中寻找到目标文件,如果xhr下没有所需数据,可以尝试刷新页面:
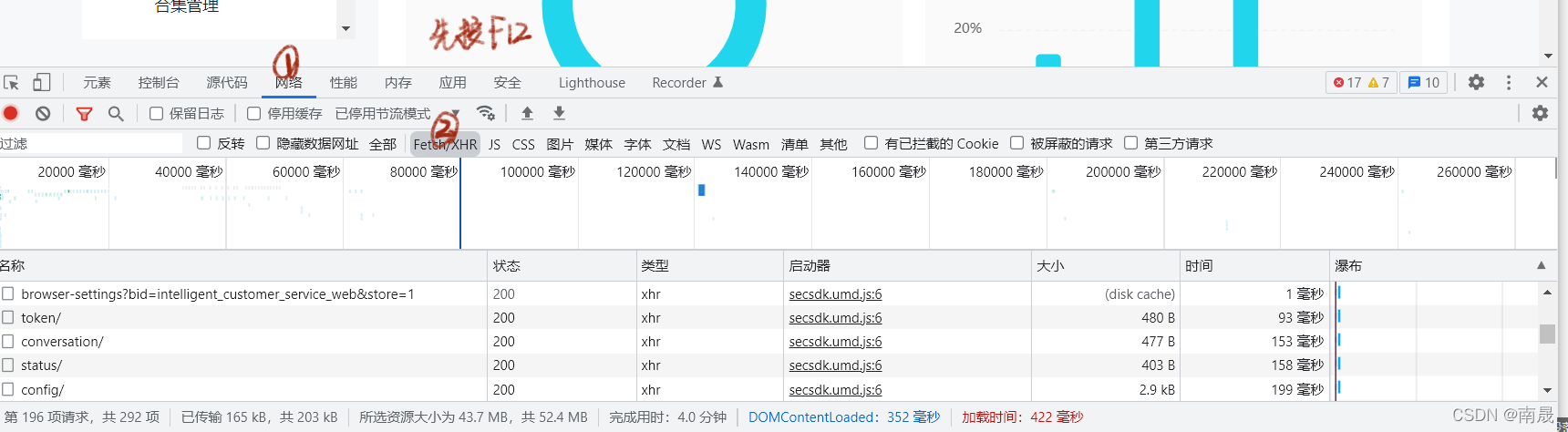
经尝试后不难找到初始数据存放位置,可以看出请求方法为get,从图中很容以看到我们所需要的性别数据:


接下来就是用代码实现这一步骤。
二、代码实现
1.准备条件
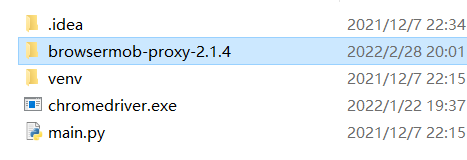
安装Browsermob-Proxy和chromedriver.exe:
下载chromedriver驱动
将下载好后的brosermob-proxy-2.1.4和浏览器对应版本的chromedriver保存至main.py的同级目录下:
2.编写代码
引入库:
import json#读取json数据时需要用到
import os
import requests
from selenium import webdriver
from browsermobproxy import Server
配置代理环境和chrome浏览器:
path=os.getcwd()#获取当前路径
server = Server(path+"\\browsermob-proxy-2.1.4\\bin\\browsermob-proxy")
server.start()
proxy = server.create_proxy()
chrome_options =webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument("---kiosk")#设置全屏
driver = webdriver.Chrome(options=chrome_options)
#
proxy.new_har(options={'captureHeaders': True, 'captureContent': True})
使用cookie给chrome浏览器增加用户信息:
因为我这里是以抖音为例,抖音里的json数据需要登陆账号才能获取,否则会报“无操作权限”,可根据自己的需求选择是否使用。
cookie=driver.get_cookies()
jsonCookies=json.dumps(cookie)
with open ("driver.json",'w') as f:
f.write(jsonCookies)
with open('driver.json','r',encoding='utf-8') as f:
listCookies=json.loads(f.read())
cookie = [item["name"] + "=" + item["value"] for item in listCookies]
cookiestr = '; '.join(item for item in cookie)
获取的网络请求和读取数据:
result = proxy.har#读取当前网页信息
for rs in result['log']['entries']:
a=rs['request']['url']#获取url链接
if "aweme/v1/creator/data/item/audience" in a:#查找目标关键字(这里可根据自己的需求更改搜索内容)
url=a#得到目标url
#以下是使用cookie获取到get请求中的json数据
headers = {'cookie': cookiestr,#若不使用cookie可去掉这句话
"User_Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
html=requests.get(url=url,headers=headers)#用request登陆目标url
data=html.text
data=json.loads(data)#将json数据转为字典数据,以便使用
使用获取到的数据:
查看数据如下:

此处用字典的获取方法或用正则表达式获取均可
for k in data:
if k == 'gender_data':
gender = data.get(k)
for i in gender:
for j in i.values():
if j == '1':
dict['gender_num'] =dict.get('gender_num',0) + int(i.get('value'))
dict['male'] = int(i.get('value'))
if j == '2':
dict['female'] = int(i.get('value'))
dict['gender_num'] =dict.get('gender_num',0) +int(i.get('value'))
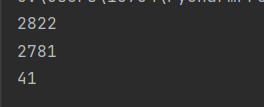
打印数据
print(dict['gender_num'])
print(dict['male'])
print(dict['female'])
总结
这是寒假做一个项目时遇到的问题,网上没找到完整的方法,自己到处查阅资料最后做出来的。
browsermobproxy的使用稍显麻烦,希望可以给大家一个参考,当然这里我只是提供了一些必要的流程,有些使用爬虫的细节我略去了,比如在不同的网页中可以都使用一次proxy.new_har(),可以避免proxy.har获取到的信息重复出现等等。