csdn的朋友们,好久不见。这次是对 1 月份和 2 月份的知识点总结。
python 歪门邪道
os.path.splitext
os.path.splitext 可以对文件路径进行分割得到 文件后缀名 和 刨除后缀名 两部分
对于文件名,直接是 name + .xyz
对于路径,是 path/to/name + .xyz
注意,这里的后缀名是 .xyz 而不是 xyz
大多数函数中,对于 format 的要求是后者,是不带点的 xyz
如果路径是字符串类型,可以用列表的方式索引 [0 : -4]
但这样子索引只是去除后三位,长一点的,比如 pickle 需要到-6
这种方法索引得到的前半部分,带有小数点,再加后缀名时不用再加小数点,或者索引时到-5
typing 模块的 union
使用 typing 模块的 union 可以指定某参数的类型,多个候选
vars: Union[int, str]
vars 可以是 int ,也可以是 str
optional,只能有一个候选(如果None也算一个的话,可以有两个候选)
https://www.cnblogs.com/poloyy/p/15170066.html
https://www.cnblogs.com/poloyy/p/15170297.html
进制转换去掉标志符
https://blog.csdn.net/kongtaoxing/article/details/119699820
Python进制转换后去掉“0b“,“0x“,“0o“
一种方式是利用字符串列表的索引 [2: ]
另一种是使用format
slice 对象
python 内置对象 slice 的源码
class slice(object):
start: Any
step: Any
stop: Any
@overload
def __init__(self, stop: Any) -> None: ...
@overload
def __init__(self, start: Any, stop: Any, step: Any = ...) -> None: ...
__hash__: None # type: ignore
def indices(self, len: int) -> Tuple[int, int, int]: ...
输入是 start, stop, step 三个对象,只有一个方法,indices,该方法返回一个元组
注意三者的顺序,是先 start 再 stop 最后 step
python的global关键字
正常情况下在函数体外定义的变量可以在全局使用,但是如果在函数体内对其有修改,python就认为该变量是一个局部变量,会报错。因为该变量在函数体外定义过了,一个变量不能即是全局变量,又是局部变量
为了解决上述问题,在函数体内加上global关键字,此时再对该变量进行修改,python仍然认为其是全局变量。简单说就是在面临二选一时,选择了全局变量。
https://zhuanlan.zhihu.com/p/111284408
需要注意的是,全局变量在经过修改后,其内部存储的数值会发生变化
不加global的关键字,进入函数体后不再改变,可以看成C语言里的宏
def add():
global x
x = x + 1
print(x)
x=1
add()
print(x)
#2
#2
cython
网上介绍cython的文章很多,不如官方文档清晰
https://moonlet.gitbooks.io/cython-document-zh_cn/content/ch1-basic_tutorial.html
简记:
$ python setup.py build_ext --inplace
运行完上述命令会在你的当前目录生成一个新文件,如果你的系统是 Unix,文件名为 helloworld.so,如果你的系统是 Windows,文件名为 helloworld.pyd
有的python库中包含cython,c拓展
如果是源码安装需要分成两步
python setup.py build_ext --inplace
这句话编译pyx(cython)文件,生成可执行的pyd文件
python setup.py install 这句话把整个包装到环境里
seaborn保存图片
https://blog.csdn.net/qq_39560620/article/details/105596149
删除文件
python os 模块删除一个文件,或者文件夹
os.remove( ‘path/to/file’ )
os.unlink( ‘path/to/file’ )
这两种都是删除单个文件,区别在于后者在删除时,如果被删除文件正在被使用(比如正在被记事本打开浏览),会抛出异常。前者不会
os.rmdir( ‘path/to/dir’ ) 只能用来删除空的文件夹
os.removedirs( ‘path/to/dir’ ) 递归的删除文件夹,只能是空的
可以用shutil模块
import shutil
shutil.rmtree()
这个可以删除含有文件的文件夹
https://www.cnblogs.com/aaronthon/p/9509538.html
图卷积神经网络
官方文档&论文链接&论文通俗解释
GCNConv的简单实现:https://pytorch-geometric.readthedocs.io/en/latest/notes/create_gnn.html
论文:https://arxiv.org/abs/1609.02907
论文通俗解释:http://tkipf.github.io/graph-convolutional-networks/
symlink
symlink可以symlink symlink文件
target可以是symlink文件
文件的type是最终的根文件
symlink文件完全可以当成正常的文件,前提是根文件存在
注意!!!symlink 的母文件路径一定是绝对路径,不能是相对路径
python 改写文件
读取旧文件,新建文件,把旧文件内容写入新文件,删掉旧文件,重命名新文件
https://www.cnblogs.com/wc-chan/p/8085452.html
https://www.yiibai.com/python/python_files_io.html
一天一句linux
rm -rf *
清除当前文件夹下所有文件
https://blog.csdn.net/xuehuafeiwu123/article/details/78563295
linux &和nohup(no hang up)
& 是任务放到后台处理,但是退出会话窗口后,任务中断
no hang up是不挂起,hang up就是挂断电话的意思,no hang up是不挂断的意思
该命令经常和&一起使用
但是只有二者的话
比如
nohup ./frps -c ./frps.ini &
会有如下信息:
nohup: 忽略输入并把输出追加到"nohup.out"
原因在于,程序运行过程中可能会报错,如果没有nohup,报错可以直接在终端窗口显示。
但是有了nohup,报错就没地方显示了,linux默认输出到nohup.out
如果当前目录没有nohup.out,则会新建一个
常见的还有,输出到当前目录下的null文件里
nohup ./frps -c frps.ini >> null 2>&1 &
输出到当前目录下的my.log文件里
nohup ./frps -c frps.ini >> my.log 2>&1 &
https://blog.csdn.net/qq_26129413/article/details/109890013
taskset -c 1
这种应该算是辅助命令,如果放在真正执行的命令后面,比如python dispatch.py,taskset将不被执行
top命令详解
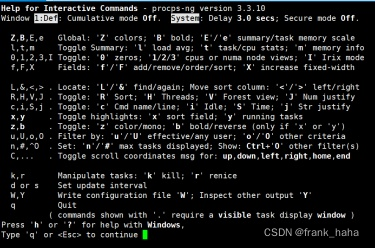
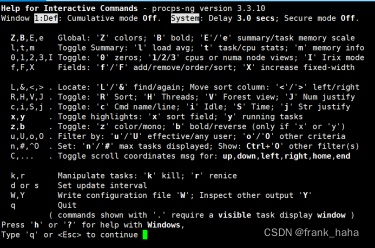
https://linux.cn/article-2290-1.html
linux 查看内存,cpu使用情况
https://www.cnblogs.com/li-xingtao/p/4372500.html
一分钟了解 load average
https://www.w3cschool.cn/architectroad/architectroad-loadaverage.html
ls | wc -w
linux查询当前目录下有多少文件
https://blog.csdn.net/a1007720052/article/details/79408681
nvidia-smi
中间的 - 链接二者,没有间隙
升级cmake、安装GCC
- 升级centos系统下的cmake版本
https://www.cnblogs.com/chenjian688/p/14446094.html - 离线安装gcc
https://www.cnblogs.com/liuxingcheng/p/11404806.html
注意,最后 make 和 make install 的时候需要用到 root 权限。最好一开始就用 root 装 - https://blog.csdn.net/qq_32486011/article/details/106871012
在更新gcc版本以后,使用软链接替换旧 gcc 版本
linux文件路径
./ 表示当前文件夹
/ 表示当前文件夹所在的根目录
git
git clone 报错的其中一种解决办法
https://blog.csdn.net/zxhzm_life/article/details/120253790
把链接开头的 https 换成 git 即可
git rebase 简记
https://blog.csdn.net/weixin_42310154/article/details/119004977
rebase 可以看作 re-base 换基
常用场景如下:
个人分支作了一些修改,此时主分支有一些新的重要的修改,通过rebase操作可以让个人分支的 base 更新到最新的主分支,同时个人分支上的修改保留。
pycharm 专业版 对于 git 模块有非常好的教程!
https://ruanyifeng.com/blog/2020/04/git-cherry-pick.html cherry pick 和 merge 也很重要
gaussian
gaussian使用虚原子小技巧:
gaussian默认使用冗余内坐标进行分子构型优化(俺不是很懂,反正这么多年了,一直用它肯定很厉害)
但对于线性分子,比如氰分子等,优化会出现问题,因为出现了180°的角
为了解决这个问题需要引入虚原子,在关键词opt=z-matrix下优化
即,从,冗余内坐标转变为内坐标
虚原子建模方法:
①先用xtb粗优化一下,然后把线性片段涉及的三个原子的xyz坐标调整到最后
②把xyz坐标复制到一个gjf文件里,gview打开该文件
③虚原子放置在线性分子中间原子附近,二者加上单键
④此时虚原子是新加的,序号在最后,不能有效改善成键180°的问题,解决方法是随便找一个原子代替线性片段中的一个原子(比如Ar代替线性片段中的O),再用原来的原子替换回来。这样子倒腾一下,新加的x原子的序号就不是最后了。
⑤文件另存为时把xyz格式那个√去掉,加上关键字opt=z-matrix即可
注:可以使用 atom list 调整原子序号
需要注意的是,邻接矩阵中,虚原子是不算的,所以排在虚原子后面的原子的序号集体前进一位
此外还需要固定虚原子与其他原子的键长、键角和二面角,方法①是把虚原子对应的三个数据直接填上去,方法②是在其他原子的键长键角二面角数据后面,空一行,再写虚原子的。
http://sobereva.com/404
使用list调整虚原子序号,更方便
http://bbs.keinsci.com/thread-1972-1-1.html
ase
neighborlist 里面有一个cutoff,还有一个skin
cutoff 本意是当两原子距离小于了二者的 cutoff 之和,二者成键
因此这个cutoff设定为原子的共价键半径
ase的view里面,就是按照这个cutoff来的
skin是原子的皮肤厚度,即,原子处于无序化运动时,如果动的很小,我们认为它没动,之前的邻居关系可以保留
当原子跑出了它的皮肤,就需要更新它的邻居了
但是bug在,neighborlist在初始化时,cutoff是naturalcutoff和skin之和
比如,两个碳原子相距2.0A,碳原子的naturalcutoff是0.76,如果不算skin的话,二者不成键,算的话就要成键了。所以在不需要频繁update neighborlist的情况下(不跑MD, MC),skin需要显式的设为零。
abcluster 安装问题
今天忙活大半天只改了一个bug
/usr/lib64/libstdc++.so.6: version `GLIBCXX 3.4.21’ not found
简述:需要安装一个软件,但这个软件需要一个动态链接库。我们服务器连不到外网,gcc版本只有4.8.5,不支持需要的那个动态链接库(GLIBCXX 3.4.21)
解决方案:
最开始想的是借一台超算,gcc版本大于4.8.5即可,问了一大圈,要么是不满足条件,要么是各种拖,最烦那种接了别人的活儿,也不干,就一直拖。
后来仔细想一想,软件只是依赖于那个特定版本的动态链接库,我直接下下来,手动安装不就行了。网址在https://pkgs.org/download/libstdc++.so.6(GLIBCXX_3.4.20)(64bit),网址是好网址,东西是好东西,拖到超算上以后发现gcc不支持,白瞎。
崩了,俺上网租一台服务器还不行。
网上一搜,没有适合的,多核的CPU租赁平台。要么是面向网页开发,要么是面向机器学习。没有专门租CPU的。
俺甚至申请了账号,上去一看CPU只有两个核,还不如俺的台式机。
最后又回到了第一条路,四处跪舔别人,求借节点。
终于!!功夫不负老舔狗,有一个师姐说,她遇到过类似的问题。
真正的解决方案是:
anaconda在安装的过程中会自带一个gcc和完整的一套动态链接库。
在.bashrc里把动态链接库链接到anaconda的lib路径即可!
也就是一句话
export LD_LIBRARY_PATH=/home/xxx/anaconda3/lib:$LD_LIBRARY_PATH
改的第二个bug是:
If you prepare an input file on Windows and copy it to Linux, ABCluster may not recognize its format and report such an error.
张老师完美预判了我经历的两个bug!在手册里他说解决办法是:In this case, please transform the Windows file format into Linux one by dos2unix or using :set fileformat=unix in VIM.
俺看不懂,但大受震撼。因为俺的服务器连不上网,又没有dos2unix,俺要哭了,还好俺坚强。
土方法:
用linux下跑过的,生成出来的xyz文件做母体,把里面内容情况,把准备好的内容直接复制进去。问题解决。
原理是为什么,至今俺还没想明白。大概是linux生的xyz文件和win下的不一样,即使他俩内容标题完全一致,也不行!不同的出身,不同的阶级!