文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MRVBuJR0-1646835638211)(../Figure/image-20220309173903724.png)]](https://img-blog.csdnimg.cn/2b271137cf71468fa3f9ff7d8cb787ee.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA54Gv56y85Y-q6IO95p2l5pWZ5a6k5L2T6aqM55Sf5rS7,size_20,color_FFFFFF,t_70,g_se,x_16)
game.py
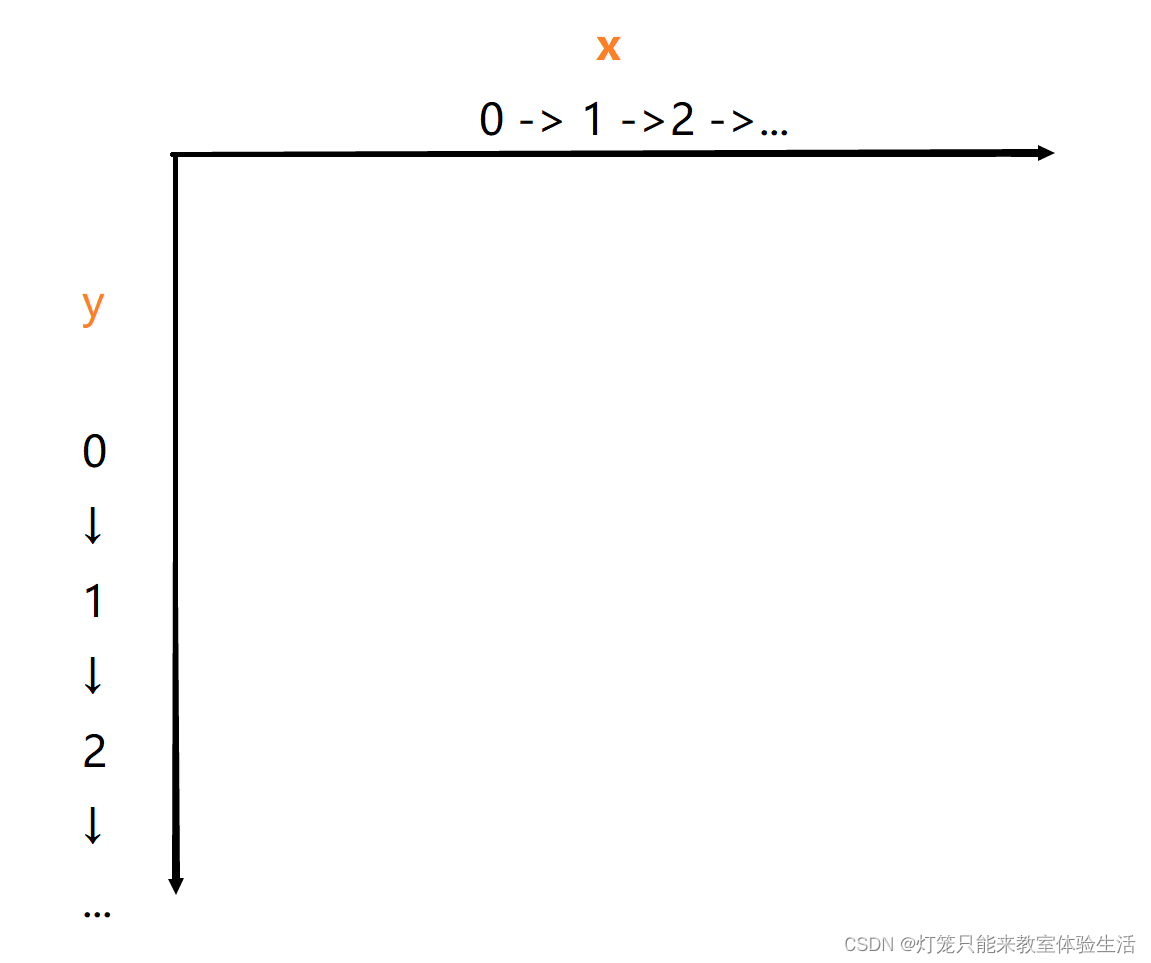
游戏用的是pygame库。
pygame中的坐标轴
init
我使用了collections中的namedtuple作为坐标。游戏中的蛇头、蛇身、食物都会用Point表示。
定义了方向的枚举类,用来表示方向。
Point = namedtuple('Point', 'x, y')
class Direction(Enum):
LEFT = 1
RIGHT = 2
UP = 3
DOWN = 4
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w4U9nrnp-1646835638213)(../Figure/image-20220309175451843.png)]](https://img-blog.csdnimg.cn/adeb4674db9e47568a85c5463ef23a3c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA54Gv56y85Y-q6IO95p2l5pWZ5a6k5L2T6aqM55Sf5rS7,size_20,color_FFFFFF,t_70,g_se,x_16)
def __init__(self, w=640, h=480):
self.W = w # 窗口的宽
self.H = h # 窗口的高
self.direction = Direction.RIGHT # 一开始的方向为右
self.display = pygame.display.set_mode((self.W, self.H)) # 设置游戏窗口大小
self.clock = pygame.time.Clock() # 帮助跟踪时间的对象
pygame.display.set_caption('Snake') # 设置窗口标题
self.reset() # 重置游戏参数
reset
def reset(self):
# 蛇一开始长这样: --@
self.head = Point(x=self.W / 2, y=self.H / 2) # 初始化蛇头位置,位于正中央
self.snake = [ # 蛇身,包括头部
self.head,
Point(x=self.head.x - BLOCK_SIZE, y=self.head.y),
Point(x=2 * self.head.x - BLOCK_SIZE, y=self.head.y),
]
self.food = None # 食物
self._place_food() # 生成食物的坐标
self.frame_iteration = 0 # 定义游戏的持续帧
self.score = 0 # 游戏的分数,吃到苹果会加分
_place_food
x = random.randint(0, (self.W - BLOCK_SIZE) // BLOCK_SIZE) * BLOCK_SIZE
y = random.randint(0, (self.H - BLOCK_SIZE) // BLOCK_SIZE) * BLOCK_SIZE
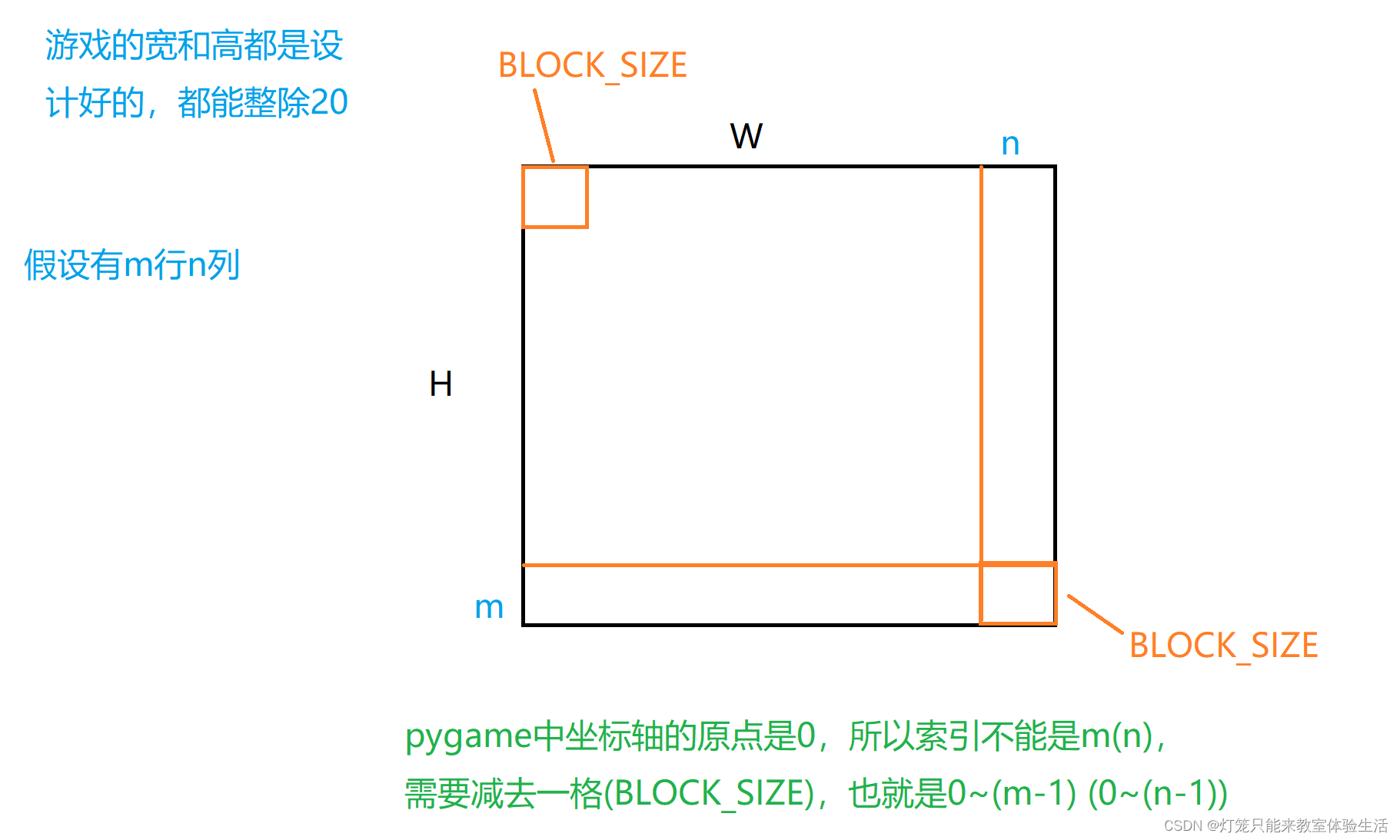
def _place_food(self):
# BLOCK_SIZE 是每个单元格的大小;
# //是整除操作, 4//3 = 1, 4/3 = 1.3333333333333333
x = random.randint(0, (self.W - BLOCK_SIZE) // BLOCK_SIZE) * BLOCK_SIZE # 随机生成x坐标
y = random.randint(0, (self.H - BLOCK_SIZE) // BLOCK_SIZE) * BLOCK_SIZE # 随机生成y坐标
self.food = Point(x, y) # 设置食物的坐标
if Point(x, y) in self.snake: # 如果生成的坐标在蛇的身体里,就再重新生成一次
self._place_food()
is_collision
def is_collision(self, pt=None): # pt是Point的缩写
if pt is None:
pt = self.head
if pt in self.snake[1:]: #切片操作是因为snake[0]是头部,碰撞之一是指头部撞到身体
return True
if pt.x < 0 or pt.x > self.W - BLOCK_SIZE or pt.y < 0 or pt.y > self.H - BLOCK_SIZE: # 撞墙
return True
return False
_update_ui
def _update_ui(self):
self.display.fill(BLACK) # 将背景填充为黑色,其中BLACK = (0, 0, 0),就是一个RGB元组
for pt in self.snake:
# 画矩形,并填充颜色BLUE1,这里画的是蛇头和蛇身
# 如果希望区分蛇头和蛇身的颜色:for pt in self.snake[1:],但要单独定义一个RGB元组来渲染蛇头
pygame.draw.rect(self.display, BLUE1, pygame.Rect(pt.x, pt.y, BLOCK_SIZE, BLOCK_SIZE))
pygame.draw.rect(self.display, BLUE2, pygame.Rect(pt.x + 4, pt.y + 4, 12, 12))
# 绘制食物
pygame.draw.rect(self.display, RED, pygame.Rect(self.food.x, self.food.y, BLOCK_SIZE, BLOCK_SIZE))
# pygame文本,其中FONT是FONT = pygame.font.Font('arial.ttf', 25)
# arial.ttf是字体文件,25是字体大小
text = FONT.render('Score:' + str(self.score), True, WHITE)
self.display.blit(text, [0, 0]) # 将text放在窗口的(0,0)位置(左上角)
pygame.display.flip() # 更新整个待显示的Surface对象到屏幕上
_move
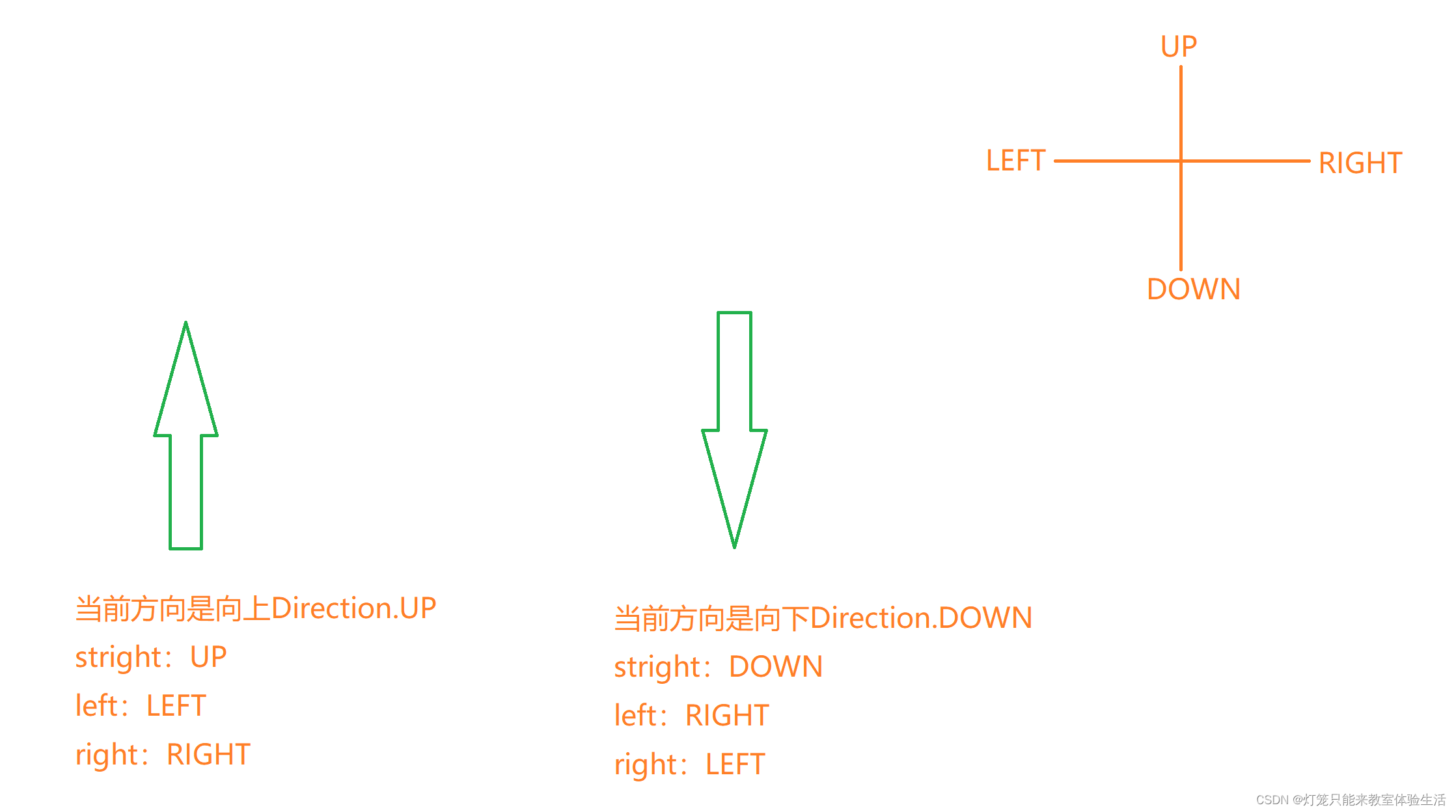
贪吃蛇游戏中,是不允许反向移动的(往左的时候不能立刻往右)。
解决办法有很多,我这里采用的方法是限制移动的方向为[straight:往前,right:往右,left:往左]
核心思想就是相对当前的方向,按照:
- 当前方向的原方向就是straight
- 当前方向的左边就是left
- 当前方向的右边就是right
def _move(self, action):
# action = [straight, right, left]
clock_wise = [Direction.UP, Direction.RIGHT,
Direction.DOWN, Direction.LEFT] # clock_wise:顺时针方向↑→↓←
# 定位到当前方向在clock_wise中的索引
idx = clock_wise.index(self.direction)
if np.array_equal(action, [1, 0, 0]): # action是stright
new_direction = clock_wise[idx] # 当前方向是往前,操作也是往前,那么方向是不会变的。
elif np.array_equal(action, [0, 1, 0]): # action是right
new_direction = clock_wise[(idx + 1) % 4] # 当前的方向是往右,对于的"操作右"就是往下
elif np.array_equal(action, [0, 0, 1]): # action是left
new_direction = clock_wise[(idx - 1) % 4]
self.direction = new_direction
x = self.head.x
y = self.head.y
# 根据方向更新坐标
if self.direction == Direction.RIGHT:
x += BLOCK_SIZE
elif self.direction == Direction.LEFT:
x -= BLOCK_SIZE
elif self.direction == Direction.UP:
y -= BLOCK_SIZE
elif self.direction == Direction.DOWN:
y += BLOCK_SIZE
self.head = Point(x, y)
agent.py
init
def __init__(self):
self.model = Linear_QNet(11, 256, 3)
self.gama = 0.9
self.epsilon = 0
self.n_games = 0 # 游戏的总局数
self.memory = deque(maxlen=MEMORY_SIZE) # 经验池的大小
self.trainer = QTrainer(self.model, LR, self.gama) # 训练过程封装在类中了
get_action
argmax:返回tensor中最大值的索引
>>> import torch
>>> x = torch.randn(5) # 获取随机的5个值组成的tensor
>>> x
tensor([0.6875, 0.2979, 0.3359, 0.0452, 0.7232])
>>> max_idx = torch.argmax(x)
>>> max_idx
tensor(4)
>>> max_idx.item() # 将tensor转为python的普通类型
4
>>> x[4]
tensor(0.7232)
def get_action(self, state):
self.epsilon = 80 - self.n_games
final_move = [0, 0, 0]
# epsilon会越来越小,那么采取随机动作的概率也会逐渐减小到0
# move是一个1x3的列表,对于3种动作
if random.randint(0, 200) < self.epsilon:
move = random.randint(0, 2)
final_move[move] = 1
else:
state0 = torch.tensor(state, dtype=torch.float)
prediction = self.model(state0)
# 网络的输出是三种结果对于的价值期望,用argmax选出最高的那一个
move = torch.argmax(prediction).item()
final_move[move] = 1
return final_move
get_state
这里我的状态是一个1x11的数组:
1.三个方向上是否有危险(如果按该方向走一步是否有危险)
2.当前的方向,如果是向上则是[1, 0, 0, 0],向下则是[0, 1, 0, 0];当然你定义的不一样也没有关系,反正只有一个方向是1。
3.食物的位置
def get_state(self, game):
head = game.snake[0]
pt_left = Point(head.x - BLOCK_SIZE, head.y)
pt_right = Point(head.x + BLOCK_SIZE, head.y)
pt_up = Point(head.x, head.y - BLOCK_SIZE)
pt_down = Point(head.x, head.y + BLOCK_SIZE)
dir_left = game.direction == Direction.LEFT
dir_right = game.direction == Direction.RIGHT
dir_up = game.direction == Direction.UP
dir_down = game.direction == Direction.DOWN
state = [
# danger straight
(dir_up and game.is_collision(pt_up)) or
(dir_down and game.is_collision(pt_down)) or
(dir_left and game.is_collision(pt_left)) or
(dir_right and game.is_collision(pt_right)),
# danger left
(dir_up and game.is_collision(pt_left)) or
(dir_down and game.is_collision(pt_right)) or
(dir_left and game.is_collision(pt_down)) or
(dir_right and game.is_collision(pt_up)),
# danger right
(dir_up and game.is_collision(pt_right)) or
(dir_down and game.is_collision(pt_left)) or
(dir_left and game.is_collision(pt_up)) or
(dir_right and game.is_collision(pt_down)),
# move direction
dir_up,
dir_down,
dir_left,
dir_right,
# food location
game.food.x < head.x, # food in left
game.food.x > head.x, # food in right
game.food.y < head.y, # food in up
game.food.y > head.y, # food in down
]
return np.array(state, dtype=int)
remember
保存记录
def remember(self, state, action, reward, next_state, is_done):
self.memory.append((state, action, reward, next_state, is_done))
train_short_memory
拿一组训练数据训练。
def train_short_memory(self, state, action, reward, next_state, is_done):
self.trainer.train_step(state, action, reward, next_state, is_done)
train_long_memory
zip
>>>x = [[1,2,3], [4,5,6]]
>>>x1 = zip(*x)
>>>x1
<zip at 0x255cebb5b40>
>>>for i in x1:
print(i)
(1, 4)
(2, 5)
(3, 6)
def train_long_memory(self):
if len(self.memory) > BATCH_SIZE: # 如果当前经验池中的数据够,就随机采用
mini_sample = random.sample(self.memory, BATCH_SIZE)
else:
mini_sample = self.memory # 数据量不够,直接全部拿过来
states, actions, rewards, next_states, is_dones = zip(*mini_sample)
self.trainer.train_step(states, actions, rewards, next_states, is_dones)
model.py
Linear_QNet
模型用的是很普通的线性层。
init
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size)
)
forward
def forward(self, x):
return self.net(x)
save_model
def save_model(self, file_name='model.pth'):
model_folder_path = './model'
if not os.path.exists(model_folder_path):
os.mkdir(model_folder_path)
file_name = os.path.join(model_folder_path, file_name)
torch.save(self.state_dict(), file_name)
QTrainer
init
def __init__(self, model, lr, gama):
self.model = model
self.lr = lr
self.gama = gama
self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr)
self.creterion = nn.MSELoss()
train_step
def train_step(self, state, action, reward, next_state, is_done):
# 参数都是np.array,转换成tensor
state = torch.tensor(state, dtype=torch.float)
action = torch.tensor(action, dtype=torch.float)
reward = torch.tensor(reward, dtype=torch.long)
next_state = torch.tensor(next_state, dtype=torch.float)
# 如果是训练一组数据,shape是n,则要将tensor的shape增加一个维度
# 多组数据不需要,因为shape是 1xn的
if len(state.shape) == 1:
is_done = (is_done,)
state = torch.unsqueeze(state, 0)
action = torch.unsqueeze(action, 0)
reward = torch.unsqueeze(reward, 0)
next_state = torch.unsqueeze(next_state, 0)
pred = self.model(state)
target = pred.clone()
for idx in range(len(is_done)):
Q_new = reward[idx]
if not is_done:
# gama:模型对未来的奖励的重视程度,一般gama=0.9
Q_new = Q_new + self.gama * torch.max(self.model(next_state[idx]))
# torch.argmax(action).item() 更新价值期望
target[idx][torch.argmax(action).item()] = Q_new
self.optimizer.zero_grad()
loss = self.creterion(target, pred)
loss.backward()
self.optimizer.step()
train()
这个函数可以单独放在一个文件中,不过我为了方便,放在了agent.py。
def train():
# 用来记录score,平均score,用于画图
plot_scores = []
plot_mean_scores = []
total_score = 0
record = 0 # 最好的记录
agent = Agent()
game = SnakeGameAI()
while True:
state_old = agent.get_state(game)
final_move = agent.get_action(state_old)
reward, is_done, score = game.play_step(final_move)
state_next = agent.get_state(game)
agent.train_short_memory(state_old, final_move, reward, state_next, is_done)
agent.remember(state_old, final_move, reward, state_next, is_done)
if is_done:
agent.n_games += 1
game.reset()
agent.train_long_memory()
# 如果分数比最好的记录还要好,那就保存一下模型
if score > record:
record = score
agent.model.save_model()
print('Game', agent.n_games, 'Score', score, 'Record:', record)
total_score += score
mean_scores = total_score / agent.n_games
plot_mean_scores.append(mean_scores)
if __name__ == '__main__':
train()
代码
agent.py
from game import BLOCK_SIZE, Direction, Point, SnakeGameAI
import torch
import numpy as np
from model import Linear_QNet, QTrainer
from collections import deque
import random
LR = 0.001
MEMORY_SIZE = 100_1000
BATCH_SIZE = 100
class Agent:
def __init__(self):
self.model = Linear_QNet(11, 256, 3)
self.gama = 0.9
self.epsilon = 0
self.n_games = 0
self.memory = deque(maxlen=MEMORY_SIZE)
self.trainer = QTrainer(self.model, LR, self.gama)
def get_action(self, state):
self.epsilon = 80 - self.n_games
final_move = [0, 0, 0]
if random.randint(0, 200) < self.epsilon:
move = random.randint(0, 2)
final_move[move] = 1
else:
state0 = torch.tensor(state, dtype=torch.float)
prediction = self.model(state0)
move = torch.argmax(prediction).item()
final_move[move] = 1
return final_move
def get_state(self, game):
head = game.snake[0]
pt_left = Point(head.x - BLOCK_SIZE, head.y)
pt_right = Point(head.x + BLOCK_SIZE, head.y)
pt_up = Point(head.x, head.y - BLOCK_SIZE)
pt_down = Point(head.x, head.y + BLOCK_SIZE)
dir_left = game.direction == Direction.LEFT
dir_right = game.direction == Direction.RIGHT
dir_up = game.direction == Direction.UP
dir_down = game.direction == Direction.DOWN
state = [
# danger straight
(dir_up and game.is_collision(pt_up)) or
(dir_down and game.is_collision(pt_down)) or
(dir_left and game.is_collision(pt_left)) or
(dir_right and game.is_collision(pt_right)),
# danger left
(dir_up and game.is_collision(pt_left)) or
(dir_down and game.is_collision(pt_right)) or
(dir_left and game.is_collision(pt_down)) or
(dir_right and game.is_collision(pt_up)),
# danger right
(dir_up and game.is_collision(pt_right)) or
(dir_down and game.is_collision(pt_left)) or
(dir_left and game.is_collision(pt_up)) or
(dir_right and game.is_collision(pt_down)),
# move direction
dir_up,
dir_down,
dir_left,
dir_right,
# food location
game.food.x < head.x, # food in left
game.food.x > head.x, # food in right
game.food.y < head.y, # food in up
game.food.y > head.y, # food in down
]
return np.array(state, dtype=int)
def remember(self, state, action, reward, next_state, is_done):
self.memory.append((state, action, reward, next_state, is_done))
def train_short_memory(self, state, action, reward, next_state, is_done):
self.trainer.train_step(state, action, reward, next_state, is_done)
def train_long_memory(self):
if len(self.memory) > BATCH_SIZE:
mini_sample = random.sample(self.memory, BATCH_SIZE)
else:
mini_sample = self.memory
states, actions, rewards, next_states, is_dones = zip(*mini_sample)
self.trainer.train_step(states, actions, rewards, next_states, is_dones)
def train():
plot_scores = []
plot_mean_scores = []
total_score = 0
record = 0
agent = Agent()
game = SnakeGameAI()
while True:
state_old = agent.get_state(game)
final_move = agent.get_action(state_old)
reward, is_done, score = game.play_step(final_move)
state_next = agent.get_state(game)
agent.train_short_memory(state_old, final_move, reward, state_next, is_done)
agent.remember(state_old, final_move, reward, state_next, is_done)
if is_done:
agent.n_games += 1
game.reset()
agent.train_long_memory()
if score > record:
record = score
agent.model.save_model()
print('Game', agent.n_games, 'Score', score, 'Record:', record)
total_score += score
mean_scores = total_score / agent.n_games
plot_mean_scores.append(mean_scores)
if __name__ == '__main__':
train()
game.py
from re import S
from matplotlib import collections
import pygame
from enum import Enum
import random
from collections import namedtuple, deque
import numpy as np
pygame.init()
BLOCK_SIZE = 20
BLACK = (0, 0, 0)
WHITE = (255, 255, 255)
RED = (200, 0, 0)
BLUE1 = (0, 0, 255)
BLUE2 = (0, 100, 255)
SPEED = 20
FONT = pygame.font.Font('arial.ttf', 25)
Point = namedtuple('Point', 'x, y')
class Direction(Enum):
LEFT = 1
RIGHT = 2
UP = 3
DOWN = 4
class SnakeGameAI:
def __init__(self, w=640, h=480):
self.W = w
self.H = h
self.direction = Direction.RIGHT
self.display = pygame.display.set_mode((self.W, self.H))
self.clock = pygame.time.Clock()
pygame.display.set_caption('Snake')
self.reset()
def reset(self):
# --@
self.head = Point(x=self.W / 2, y=self.H / 2)
self.snake = [
self.head,
Point(x=self.head.x - BLOCK_SIZE, y=self.head.y),
Point(x=2 * self.head.x - BLOCK_SIZE, y=self.head.y),
]
self.food = None
self._place_food()
self.frame_iteration = 0
self.score = 0
def _place_food(self):
x = random.randint(0, (self.W - BLOCK_SIZE) // BLOCK_SIZE) * BLOCK_SIZE
y = random.randint(0, (self.H - BLOCK_SIZE) // BLOCK_SIZE) * BLOCK_SIZE
self.food = Point(x, y)
if Point(x, y) in self.snake:
self._place_food()
def play_step(self, action):
# return -> reward, is_done, score
self.frame_iteration += 1
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
quit()
# 1. move
self._move(action)
self.snake.insert(0, self.head)
# 2.check game is over
is_done = False
reward = 0
if self.is_collision() or self.frame_iteration > 100 * len(self.snake):
is_done = True
reward -= 10
return reward, is_done, self.score
# 3. food is eaten
if self.head == self.food:
self._place_food()
self.score += 1
reward = 10
else:
self.snake.pop()
# 4. update ui
self._update_ui()
self.clock.tick(SPEED)
# 5. return info
return reward, is_done, self.score
def is_collision(self, pt=None):
if pt is None:
pt = self.head
if pt in self.snake[1:]:
return True
if pt.x < 0 or pt.x > self.W - BLOCK_SIZE or pt.y < 0 or pt.y > self.H - BLOCK_SIZE:
return True
return False
def _update_ui(self):
self.display.fill(BLACK)
for pt in self.snake:
pygame.draw.rect(self.display, BLUE1, pygame.Rect(pt.x, pt.y, BLOCK_SIZE, BLOCK_SIZE))
pygame.draw.rect(self.display, BLUE2, pygame.Rect(pt.x + 4, pt.y + 4, 12, 12))
pygame.draw.rect(self.display, RED, pygame.Rect(self.food.x, self.food.y, BLOCK_SIZE, BLOCK_SIZE))
text = FONT.render('Score:' + str(self.score), True, WHITE)
self.display.blit(text, [0, 0])
pygame.display.flip() # 更新整个待显示的Surface对象到屏幕上
def _move(self, action):
# action = [straight, right, left]
clock_wise = [Direction.UP, Direction.RIGHT,
Direction.DOWN, Direction.LEFT]
idx = clock_wise.index(self.direction)
if np.array_equal(action, [1, 0, 0]):
new_direction = clock_wise[idx]
if np.array_equal(action, [0, 1, 0]):
new_direction = clock_wise[(idx + 1) % 4]
if np.array_equal(action, [0, 0, 1]):
new_direction = clock_wise[(idx - 1) % 4]
self.direction = new_direction
x = self.head.x
y = self.head.y
if self.direction == Direction.RIGHT:
x += BLOCK_SIZE
elif self.direction == Direction.LEFT:
x -= BLOCK_SIZE
elif self.direction == Direction.UP:
y -= BLOCK_SIZE
elif self.direction == Direction.DOWN:
y += BLOCK_SIZE
self.head = Point(x, y)
model.py
import torch
import torch.optim as optim
import torch.nn as nn
import os
class Linear_QNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size)
)
def forward(self, x):
return self.net(x)
def save_model(self, file_name='model.pth'):
model_folder_path = './model'
if not os.path.exists(model_folder_path):
os.mkdir(model_folder_path)
file_name = os.path.join(model_folder_path, file_name)
torch.save(self.state_dict(), file_name)
class QTrainer:
def __init__(self, model, lr, gama):
self.model = model
self.lr = lr
self.gama = gama
self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr)
self.creterion = nn.MSELoss()
def train_step(self, state, action, reward, next_state, is_done):
state = torch.tensor(state, dtype=torch.float)
action = torch.tensor(action, dtype=torch.float)
reward = torch.tensor(reward, dtype=torch.long)
next_state = torch.tensor(next_state, dtype=torch.float)
if len(state.shape) == 1:
is_done = (is_done,)
state = torch.unsqueeze(state, 0)
action = torch.unsqueeze(action, 0)
reward = torch.unsqueeze(reward, 0)
next_state = torch.unsqueeze(next_state, 0)
pred = self.model(state)
target = pred.clone()
for idx in range(len(is_done)):
Q_new = reward[idx]
if not is_done:
Q_new = Q_new + self.gama * torch.max(self.model(next_state[idx]))
target[idx][torch.argmax(action).item()] = Q_new
self.optimizer.zero_grad()
loss = self.creterion(target, pred)
loss.backward()
self.optimizer.step()
字体文件
阿里云盘
https://www.aliyundrive.com/s/J8jPL6ibosg
百度云盘
链接:https://pan.baidu.com/s/18t5V8dsh_0fF5FZFtwRrBw
提取码:0i40