类 Class
定义类
__init()__定义构造函数,与其他面向对象语言不同的是,Python语言中,会明确地把代表自身实例的self作为第一个参数传入- 创建一个实例化对象,
init()方法接收参数 - 使用点号
.来访问对象的属性
class Animal:
def __init__(self,name):
self.name = name
print('动物名称实例化')
def eat(self):
print(self.name + '要吃东西啦!')
def drink(self):
print(self.name + '要喝水啦!')
cat = Animal('miaomiao')
print(cat.name)
cat.eat()
cat.drink()
## 输出
# 动物名称实例化
# miaomiao
# miaomiao要吃东西啦!
# miaomiao要喝水啦!
继承
通过继承创建的新类称为子类或派生类
被继承的类被称为基类、父类或超类
class Person:
def __init__(self,name):
self.name = name
print('调用父类构造函数')
def eat(self):
print('调用父类方法')
class Student(Person): # 定义子类
def __init__(self):
print('调用子类构造方法')
def study(self):
print('调用子类方法')
s = Student()
s.study()
s.eat()
# 调用子类构造方法
# 调用子类方法
# 调用父类方法
JSON序列化与反序列化
JSON序列化
json.dumps用于将Python对象编码成JSON字符串
import json
data = [ {'b':2, 'd':4, 'a':1, 'c':3, 'e':5} ]
# json = json.dumps(data)
# print(json)
json_format = json.dumps(data, sort_keys=True, indent=4, separators=(',',': '))
print(json_format)
JSON反序列化
json.loads用于解码JSON数据。该函数返回Python字段的数据类型
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}'
text = json.loads(jsonData)
print(text)
Pandas库
- Pandas提供高性能易用数据类型和分析工具
- Pandas基于Numpy实现,常与Numpy和matplotlib一同使用
- Pandas中有两大核心数据结构:Series(一维数据,为”键值对形式“。区别于字典,键可以重复)和DataFrame(多特征数据,既有行索引,又有列索引)
Pandas中文网:https://pypandas.cn/
Series
- series是一种类似与一维数组的对象,它由一维数组(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成
- series创建:使用Python数组、Numpy数组、Python字典创建。
- 与字典不同的:Series允许索引重复。
import pandas as pd
import numpy as np
pd.Series([11,12], index=["北京","上海"])
pd.Series(np.arange(3,6))
pd.Series({"北京":11,"上海":12, "深圳":14})
- series字符串表现形式为:索引在左边,值在右边
- 如果没有为数据指定索引,则自动创建一个0到N-1(N为数据的长度)的整数型索引
- 可以通过Series的values和index属性获取其数组表现形式和索引对象
- 与普通Numpy数组相比,可以通过索引的方式选取Series中的单个或一组值
obj = pd.Series([4,7,-5,3])
obj.values # array([ 4, 7, -5, 3], dtype=int64)
obj.index # RangeIndex(start=0, stop=4, step=1)
obj[2] # -5
obj[1] = 8
obj[[0,1,3]]
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n0VV5hdY-1647074628094)(Python%E5%A4%8D%E6%9D%82%E6%93%8D%E4%BD%9C/images/image-20220312163832748.png)]](https://img-blog.csdnimg.cn/d1c24a4b6ddf4cb180e4ee4fdc6ff8f3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Zi_6bKr5piv5p2h5ZK46bG8,size_20,color_FFFFFF,t_70,g_se,x_16)
- 在算术运算中自动对齐不同索引的数据
obj2 = pd.Series({"Ohio":35000,"Oregon":16000,"Texas":71000,"Utah":5000})
obj3 = pd.Series({"California":np.nan,"Ohio":35000,"Oregon":16000,"Texas":71000})
obj2 + obj3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lA0i6LDD-1647074628096)(Python%E5%A4%8D%E6%9D%82%E6%93%8D%E4%BD%9C/images/image-20220312163655127.png)]](https://img-blog.csdnimg.cn/abdf0c144bd147e79e032f9752994579.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Zi_6bKr5piv5p2h5ZK46bG8,size_20,color_FFFFFF,t_70,g_se,x_16)
DataFrame
-
DataFrame是一个表格型的数据结构,它含有一组有序的列。每列可以是不同的值类型(数值、字符串、布尔值等)
-
DataFrame既有行索引也有列索引,它可以被看做有Series组成的字典(共用同一个索引)
-
与其他类似的数据结构相比(例如R语言的
data.frame),DataFrame面向行和面向列的操作基本上是平衡的。 -
构成DataFrame的方法有很多,最常用的一种是直接传入一个由等长列表或Numpy数组组成的字典
-
DataFrame结果会自动加上索引(跟Series一样),且全部会被有序排列。
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],'year':[2000,2001,2002,2001,2002],'pop':[1.5,1.7,3.6,2.4,2.9]}
frame = pd.DataFrame(data)
frame
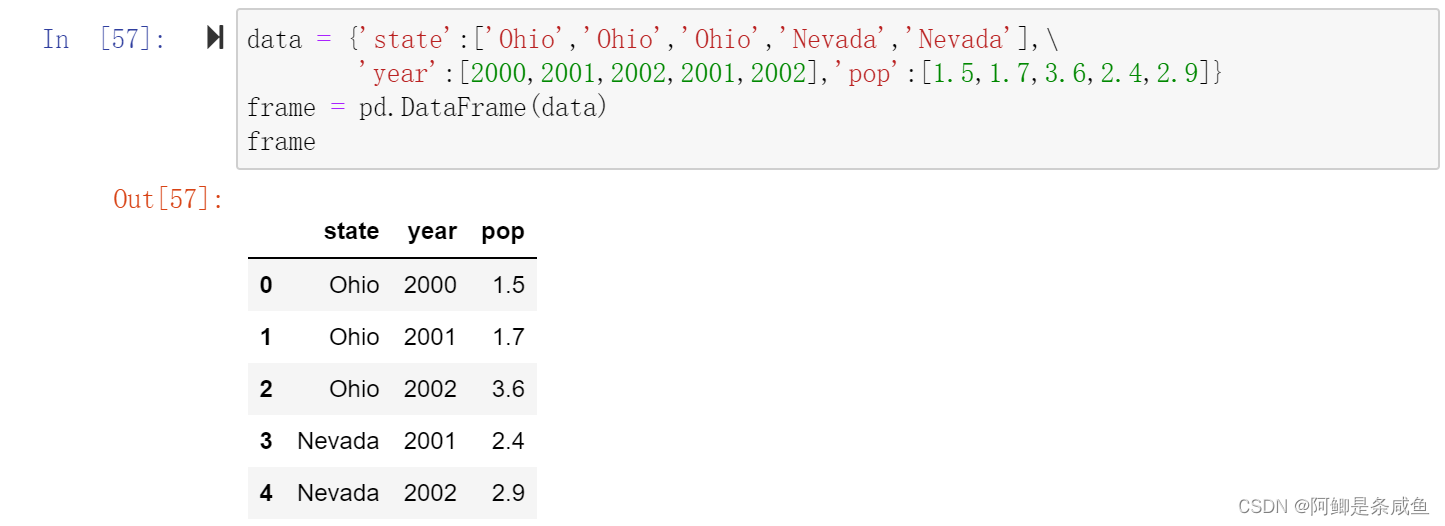
- 如果指定了列顺序,则DataFrame的列就会按照指定顺序进行排列。
pd.DataFrame(data, columns=['year','state','pop'])
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1vzHo3PY-1647074628098)(Python%E5%A4%8D%E6%9D%82%E6%93%8D%E4%BD%9C/images/image-20220312163611531.png)]](https://img-blog.csdnimg.cn/bd3f8a19a991421880b925e975ab3ed7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Zi_6bKr5piv5p2h5ZK46bG8,size_20,color_FFFFFF,t_70,g_se,x_16)
- 跟原Series一样,如果传入的列在数据中找不到,就会产生NAN值
frame2 = pd.DataFrame(data, columns=['year','state','pop','debt'], index=['one','two','three','four','five'])
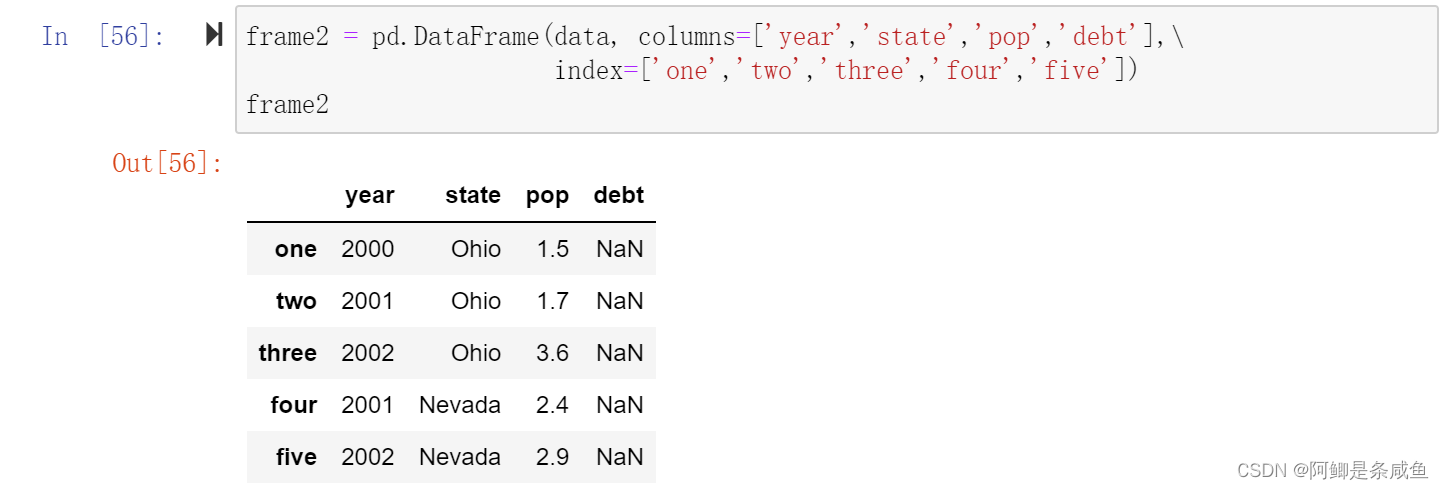
- 列可以通过赋值的方式进行修改。例如,给那个空的“delt”列附上一个标值量或一组值
frame2['debt'] = 16.5
frame2['debt'] = np.arange(5.)
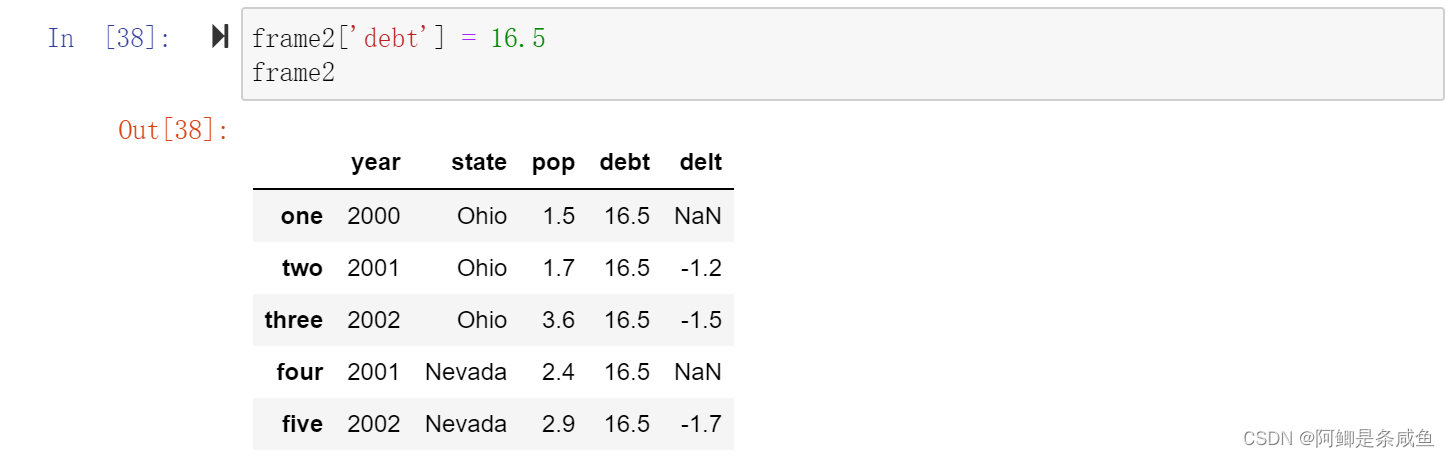
- 将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配
- 如果赋值的是一个Series,就会精确匹配DataFrame的索引,所有空位都将被填上缺失值
val = pd.Series([-1.2,-1.5,-1.7], index=['two','three','five'])
frame2['debt'] = val
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4dItJScX-1647074628101)(Python%E5%A4%8D%E6%9D%82%E6%93%8D%E4%BD%9C/images/image-20220312163424277.png)]](https://img-blog.csdnimg.cn/43b5badef660466ca71cce52fb620d28.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Zi_6bKr5piv5p2h5ZK46bG8,size_20,color_FFFFFF,t_70,g_se,x_16)
- 为不存在的列赋值,会创建一个新列
frame2['eastern'] = frame2.state == 'Ohio'
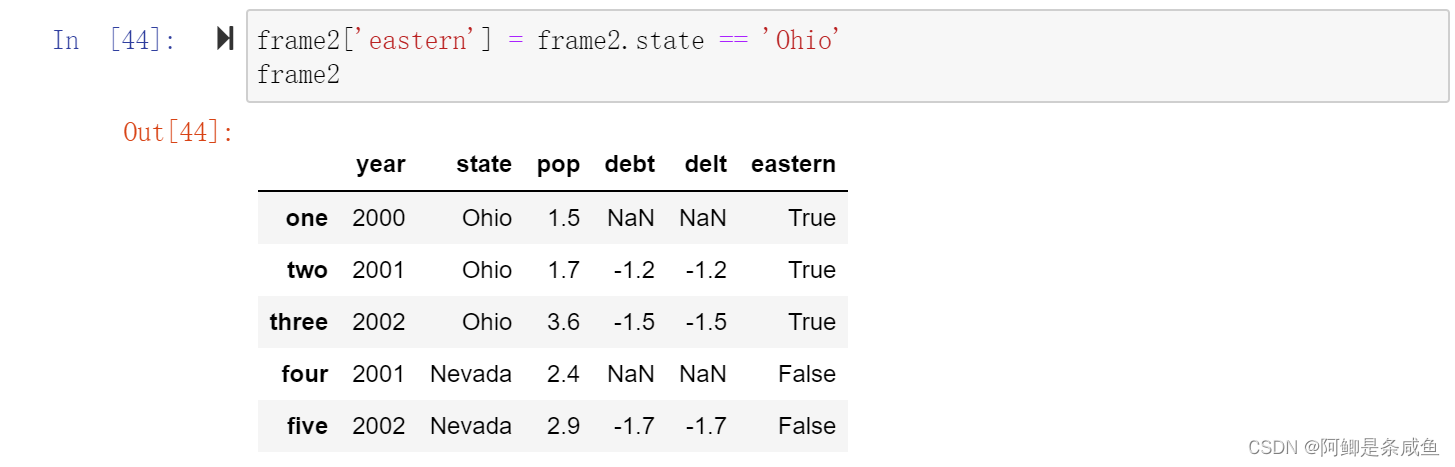
- 关键词del用于删除列
del frame2['eastern']
frame2.columns
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xRMcAiTk-1647074628103)(Python%E5%A4%8D%E6%9D%82%E6%93%8D%E4%BD%9C/images/image-20220312163343465.png)]](https://img-blog.csdnimg.cn/d4d55967d7414f519a9ecd435d0407de.png)
- 将嵌套字典(也就是字典的字典)传给DataFrame,它就会被解释为:外层字典的键作为列,内层键则作为行索引
pop = {'Nevada':{2021:2.4,2002:2.9},'Ohio':{2000:1.5,2001:1.7,2002:3.6}}
frame3 = pd.DataFrame(pop)
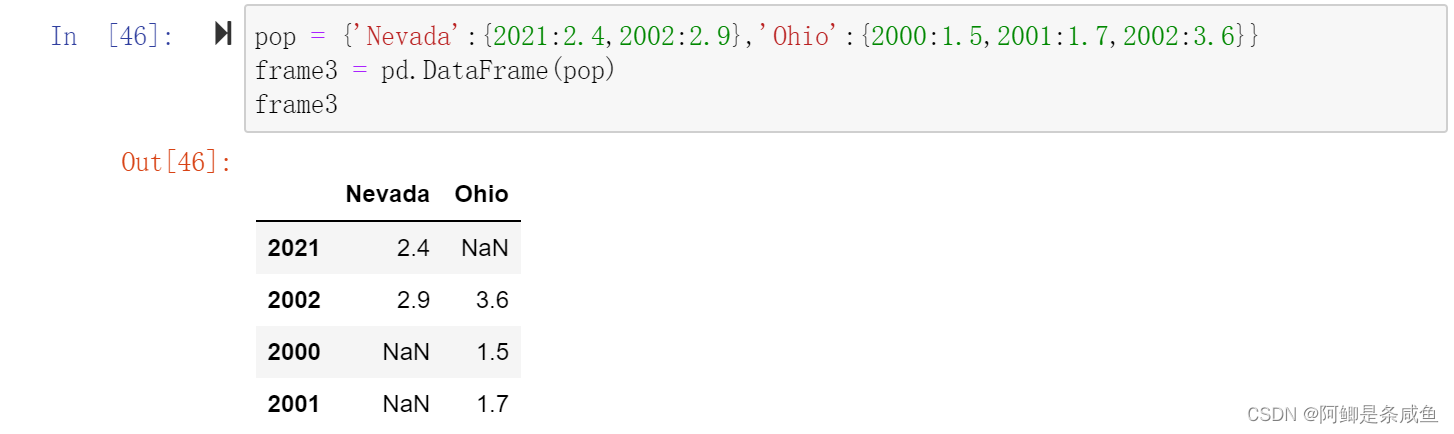
- 也可以对上述结果进行转置
frame3.T
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RAhuRqjs-1647074628105)(Python%E5%A4%8D%E6%9D%82%E6%93%8D%E4%BD%9C/images/image-20220312163239375.png)]](https://img-blog.csdnimg.cn/3bb2e7fe6dda4d4ca890a4e74a9147dd.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Zi_6bKr5piv5p2h5ZK46bG8,size_20,color_FFFFFF,t_70,g_se,x_16)
- 如果设置了DataFrame的index和columns的name属性,则这些信息也会被显示出来。
frame3.index.name = 'year'
frame3.columns.name = 'state'
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lBMCyIxN-1647074628106)(Python%E5%A4%8D%E6%9D%82%E6%93%8D%E4%BD%9C/images/image-20220312163224297.png)]](https://img-blog.csdnimg.cn/be1c614ea1be43188cd2bffabbcb75bf.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Zi_6bKr5piv5p2h5ZK46bG8,size_20,color_FFFFFF,t_70,g_se,x_16)
- 跟Series一样,values属性也会以二维数组ndarray的形式返回DataFrame中的数据
frame3.values
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3pJ24oh5-1647074628107)(Python%E5%A4%8D%E6%9D%82%E6%93%8D%E4%BD%9C/images/image-20220312163203045.png)]](https://img-blog.csdnimg.cn/6e891fae1c2c4e498b54beb7f8b858ea.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Zi_6bKr5piv5p2h5ZK46bG8,size_20,color_FFFFFF,t_70,g_se,x_16)
-
如果DataFrame各列的数据类型不同,则数组类型就会选用能兼容所有列的数据类型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DRJJBzox-1647074628109)(Python%E5%A4%8D%E6%9D%82%E6%93%8D%E4%BD%9C/images/image-20220312163114522.png)]](https://img-blog.csdnimg.cn/3032a7837d254cd8b96c2abde5c2adae.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Zi_6bKr5piv5p2h5ZK46bG8,size_20,color_FFFFFF,t_70,g_se,x_16)
-
Pandas的索引对象负责管理轴标签和其他元数据(比如轴名称)
-
构建DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index
-
Index对象时不可修改的
obj = pd.Series(range(3), index=['a','b','c'])
index = obj.index
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v1h7Ofoh-1647074628109)(Python%E5%A4%8D%E6%9D%82%E6%93%8D%E4%BD%9C/images/image-20220312163002948.png)]](https://img-blog.csdnimg.cn/ea7f6ad551434b0e95cef7c33c1ebc65.png)
- Pandas的每一个索引都有一些方法和属性,它们可用于设置逻辑并回答有关该索引包含的数据的常见问题。
| 方法 | 说明 |
|---|---|
| append | 连接另一个Index对象,产生一个新的Index |
| diff | 计算差集,并得到一个Index |
| intersection | 计算交集 |
| union | 计算并集 |
| isin | 计算一个指示各值是否都包含在参数集合中的布尔型数组 |
| delete | 删除索引处的元素,并得到新的Index |
| drop | 删除 |
| insert | 将元素插入到索引处,并得到新的Index |
| is_monotonic | 当各元素均大于等于前一个元素时,返回True |
| is_unique | 当Index没有重复值时,返回True |
| unique | 计算Index中唯一值的数组 |
| insert | 将元素插入到索引处,并得到新的Index |
| is_monotonic | 当各元素均大于等于前一个元素时,返回True |
| is_unique | 当Index没有重复值时,返回True |
| unique | 计算Index中唯一值的数组 |