����Ŀ¼
pythonдĿ¼���ƹ���
����һ��python,ע��������ҲҪ����,Ҫ��дencoding = utf-8
��url���������ֵ䱬��
#!/usr/bin/python
def bruster(url)
rep = request.get(url)
rep_code = rep.status_code
if(rep_code !=404):
print "%d %s" % (rep_code,url)
if __name__ == "__main__":
url = 'http://192.168.x.x/'
filenames = open('dic.txt','r').readlines()#dic.txtΪĿ¼�ֵ�,����filenames���б���ʽ����readlines�������ݻ���л���
for filename in filenames:
filename = filename.replace('\n','')#ȥ������
bruster(url+filename)
һ��С������д����,���������������һ��,��Ϊ���ǵ��̵߳�
�����ص�:
���߳�
- �߳�Ҳ������������,�Dz���ϵͳ�ܹ�����������ȵ���С��λ,���������ڽ�����
- ��һ������������,��Ĭ�ϲ���һ�����߳�,��Ϊ�߳��dz���ִ��������С��Ԫ,�����ö��߳�ʱ,���̻߳ᴴ��������߳�
���߳̿�:threading
������һ������,���Ǵ�����ͬʱ��ִ����,���Ƕ�ȡ�ֵ䲻���ظ��Ķ��������Ҫ�õ�python�Ķ�����,�Ƚ��ȳ�ʹ�ֵ�Ŀռ��С
���п�:queue
q = queue.Queue()����һ����Ϊq�Ķ���
q,put(argv)���������һ��Ԫ��
q.empty()�ж϶����Ƿ�Ϊ��
q.get()�Ӷ�����ȡ��һ��Ԫ��
q.qsize()���ض��д�С
����������Ľ�����:
import time
import queue
import threading
def bruster(url)
while not q.empty():
rep = request.get(url+q.get())#ȡ�����������������
rep_code = rep.status_code
if(rep_code !=404):
print "%d %s" % (rep_code,url)
if __name__ == "__main__":
target = 'http://192.168.x.x/'
q = queue.Queue()
start_time = time.time()#�жϳ�������ʱ��,�������߳�����û
filenames = open('./dic.txt','r').readlines()
for filename in filenames:
filename = filename.replace('\n','')
q.put(filename)#���ֵ��ڵ�Ԫ�����ӽ�q����
thread_list=[]#��ʼ���߳�
for i in range(5):#��ʼ������߳�
t= threading.Thread(target=bruster,args=(target,))#��targetָ�����߳����еĺ��������߳�,argesָ������(��bruster�������յIJ���)
thread_list.append(t)#�����߳�
for t in thread_list:
t.start()#�����߳�����
print('main thread end!',threading.current_thread(),name)
print('total time is',time.time()-start_time)
���������������,��Ϊ�����target�����ֵ�·������Ҫ��������ġ����ǽ����ijɽ����ⲿ���ε���ʽ������sqlmap�ĨCdump�������-uָ��urlһ��
���ȵ���sys��:import sys
sys.argv[1]�����ⲿ��һ������,����python 1.py abc,������abc
ͬ��sys.argv[2]``sys.argv[3]
���հ湤��
�����ⲿ����,��һ��Ϊ��ɨurl,�ڶ����ֵ��ı�,�������߳���
import time
import queue
import threading
def bruster(url)
while not q.empty():
rep = request.get(url+q.get())#ȡ�����������������
rep_code = rep.status_code
if(rep_code !=404):
print "%d %s" % (rep_code,url)
if __name__ == "__main__":
#target = 'http://192.168.x.x/'#��Ҫ��,���ɶ��ⲿ����
url = sys.argv[1]
dict_txt = sys.argv[2]
thread_number = sys.argv[3]
q = queue.Queue()
start_time = time.time()#�жϳ�������ʱ��,�������߳�����û
filenames = open('dict_txt','r').readlines()
for filename in filenames:
filename = filename.replace('\n','')
q.put(filename)#���ֵ��ڵ�Ԫ�����ӽ�q����
thread_list=[]#��ʼ���߳�
for i in range(int(thread_number)):#��ʼ������߳�
t= threading.Thread(target=bruster,args=(url,))#��targetָ�����߳����еĺ��������߳�,argesָ������(��bruster�������յIJ���)
thread_list.append(t)#�����߳�
for t in thread_list:
t.start()#�����߳�����
print('main thread end!',threading.current_thread(),name)
print('total time is',time.time()-start_time)
���url���ı�,��Ҫ���¶��ļ�д���б�,ѭ�����μ��,�Ҳ�д��,��,����һ��ֻ��һ��url����,����д���ܶϵ�����,��ΪLinux ctrl CĬ�϶�������,�������߳�ִ�����Լ��������˳���,���̻߳����ִ���Լ�������
����Ҫ��:python������pip��os��queue��requests��time��threading��
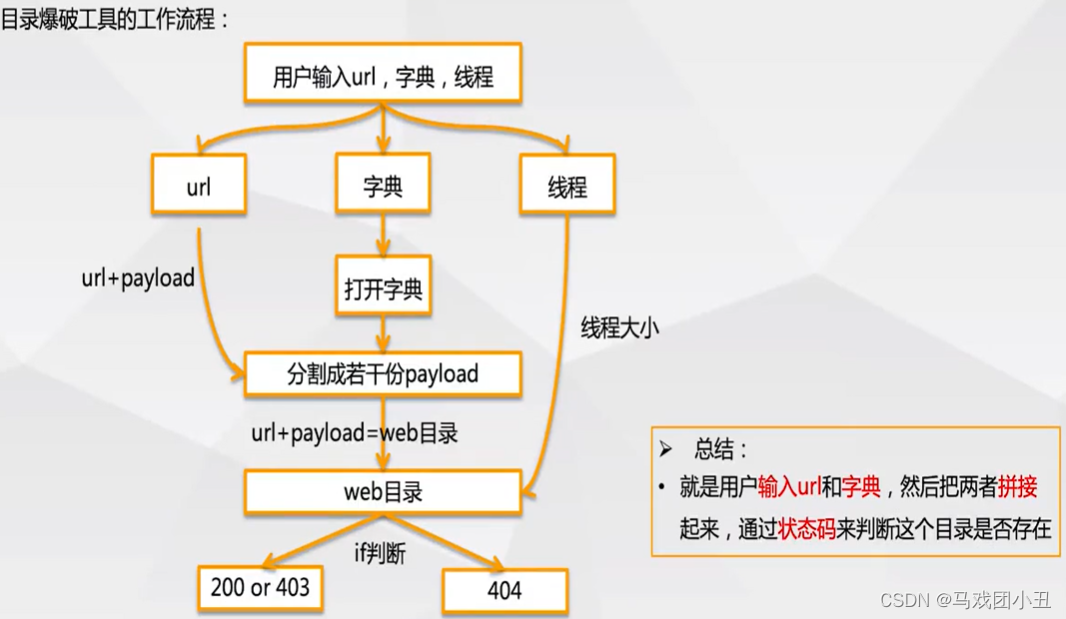
���Կ����ܼ�,��ҿ��Ժ�����Ŀ���,Ŀ¼���ƾ����ڱ�˭���ֵ�ǿ��,����ƽʱҪ�Լ��ռ�һЩ�ֵ䰡