����Ŀ¼
1. ���ۻ���
logistic�ع������������Ƕ������,Ҳ�����Ƕ�����,һ�������,���DZȽϳ��õ��Ƕ�����,Ҳ����������,������������ʹ��softmax�������д�����
logistic�ع���һ�ֹ������Իع�(generalized linear model),��������Իع�����кܶ���֮ͬ����
- ��ͬ��
���ǵ�ģ����ʽ��������ͬ,������ w x + b wx + b wx+b,���� w w w�� b b b�Ǵ��������
- ��ͬ��
�������������ǵ��������ͬ��
- �������Իع�ֱ�ӽ� w x + b wx+b wx+b��Ϊ�����,�� y = w x + b y =wx+b y=wx+b��
- logistic�ع���ͨ������ L L L�� w x + b wx+b wx+b��Ӧһ����״̬ p p p, p = L ( w x + b ) p =L(wx+b) p=L(wx+b),Ȼ����� p p p �� 1 ? p 1-p 1?p�Ĵ�С�����������ֵ��
��� L L L��logistic����,����logistic�ع�,��� L L L�Ƕ���ʽ�������Ƕ���ʽ�ع�
��
�����֮,logistic�ع�������Իع���ټ�һ��logistic�����ĵ���,������ʾ:
p
(
Y
=
0
�O
x
)
=
1
1
+
e
w
x
+
b
p(Y=0|x)=\frac{1}{1+e^{wx+b}}
p(Y=0�Ox)=1+ewx+b1?
p
(
Y
=
1
�O
x
)
=
1
?
p
(
Y
=
0
�O
x
)
=
e
w
x
+
b
1
+
e
w
x
+
b
p(Y=1|x)=1- p(Y=0|x)=\frac{e^{wx+b}}{1+e^{wx+b}}
p(Y=1�Ox)=1?p(Y=0�Ox)=1+ewx+bewx+b?
����
w
w
w��Ȩ��,
b
b
b��ƫ�á�
���ڼ���һ���¼������ļ�����ָ���¼������ĸ����벻�����ĸ��ʵı�ֵ,���Ķ�����ʽ����:
l
o
g
i
t
(
p
)
=
log
?
p
1
?
p
=
w
x
+
b
logit(p)=\log\frac{p}{1-p}=wx+b
logit(p)=log1?pp?=wx+b
������Logistic�ع�ģ����,��� Y = 1 Y=1 Y=1�Ķ������������� x x x�����Ժ���,��Ҳ����Logisti�ع����Ƶ�����,���� p > 1 ? p p > 1-p p>1?pʱ,��ʽ�����0,�� p < 1 ? p p < 1-p p<1?pʱ,��ʽ��С��0,Ҳ����˵���Ժ�����ֵԽ�ӽ�������,����ֵ��Խ�ӽ�1;���Ժ�����ֵԽ�ӽ�������,����ֵ��Խ�ӽ�0��
2. ����ʾ��
����ʾ���IJ���:
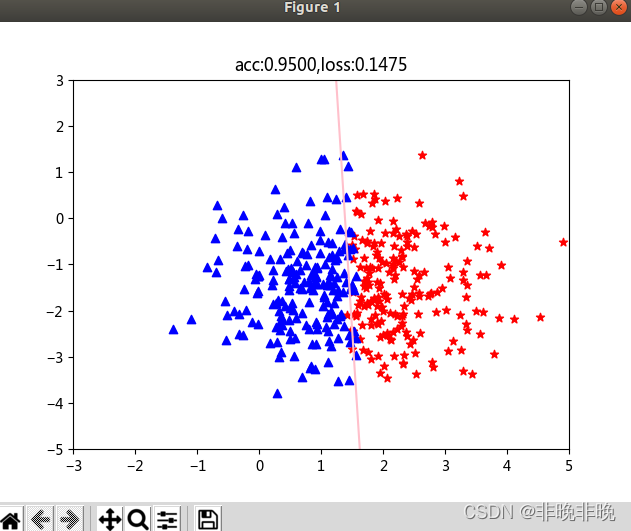
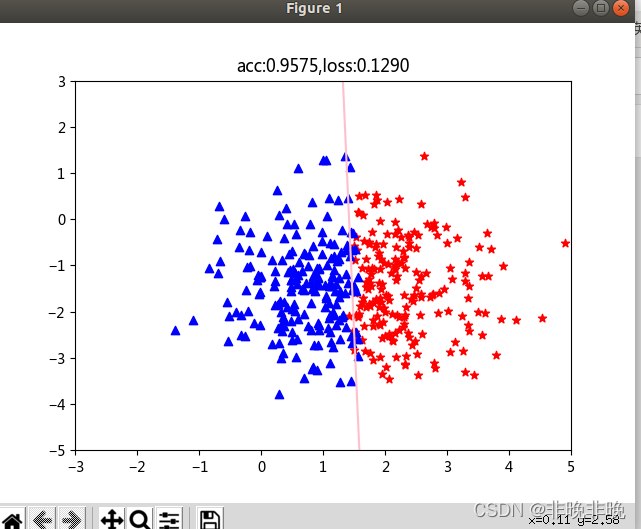
��������:����̬�ֲ����� ( x 1 , x 2 ) (x_1,x_2) (x1?,x2?)�����ݶ�,������ x 1 x_1 x1?Ϊ��,�����ݻ���Ϊpos��neg������,labelΪ��ֵ��������ʾ:ʹ��matplotlib����pos��neg�����ݷֲ�ͼ�Զ���ģ��:ʹ��nn.Linear(2,1)ָ�����������ά��,����������ֵ,������2ά��ʹ��nn.Sigmoid()ָ��ʹ�����ع���ʧ�������Ż�����ѡ��:BCE��ʧ��SGD�Ż�������ʼѵ��:����num_epochs,ÿ10000����ʾһ��ͼ��
��ʾ��ֱ��Ϊ x 1 ? w 0 + x 2 w 1 + b = 0 x_1*w_0 + x_2w_1 + b = 0 x1??w0?+x2?w1?+b=0,��ʵ��������� w x + b = 0 wx+b = 0 wx+b=0�ķֽ��ߡ�
import torch
import matplotlib.pyplot as plt
import numpy as np
#-------------------------------------������--------------------------------------
x1 = torch.randn(400)+1.5 # ����400���������̬�ֲ�������,��ֵΪ��0��,����Ϊ��1��
x2 = torch.randn(400)-1.5
data = zip(x1.data.numpy(),x2.data.numpy()) #תnumpy,���Ԫ��
pos = []
neg = []
def classification(data):
for i in data:
if (i[0] > 1.5+0.1*torch.rand(1).item()*(-1)**torch.randint(1,10,(1,1)).item()): #item��ȡԪ��ֵ,����1.5��Ϊ��������
pos.append(i)
else:
neg.append(i)
classification(data)
#����:pos and neg
inputs = [[i[0],i[1]] for i in pos] #������2,��x1��x2���
inputs.extend([[i[0],i[1]] for i in neg]) #extend ����һ������,�����������һ�� list,���Ұ���� list �е�ÿ��Ԫ�����ӵ�ԭ list ��
inputs = torch.Tensor(inputs) # torch.Tensor ���ɵ����ȸ������͵�����
#��ǩ,��ֵ,1 and 0
label = [1 for i in range(len(pos))]
label.extend(0 for i in range(len(neg)))
label = torch.Tensor(label)
#-------------------------------------������ʾ--------------------------------------
pos_x = [i[0] for i in pos]
pos_y = [i[1] for i in pos]
neg_x = [i[0] for i in neg]
neg_y = [i[1] for i in neg]
plt.scatter(pos_x,pos_y,c = 'r',marker = "*")
plt.scatter(neg_x,neg_y,c = 'b',marker = "^")
plt.show() #��ʾ������
#-------------------------------------�Զ���ģ��--------------------------------------
import torch.nn as nn
class LogisticRegression(nn.Module):
def __init__(self):
super(LogisticRegression, self).__init__() #��ʼ������
self.linear = nn.Linear(2,1) #����2ά,���1ά
self.sigmoid = nn.Sigmoid()
def forward(self,x):
return self.sigmoid(self.linear(x))
#------------------------��ʧ�������Ż�����ѡ��----------------------------
model = LogisticRegression() #ʹ��cpu
criterion = nn.BCELoss() #Binary CrossEntropyLoss,���ڶ�����
optimizer = torch.optim.SGD(model.parameters(),0.01)
#------------------------��ʼѵ��----------------------------
num_epochs = 500000
for i in range(num_epochs):
out = model(inputs)
#print(out.shape)
loss = criterion(out.squeeze(1),label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#-------------------------------------����--------------------------------------
# ��������ȷ��,ge��ʾ���ڵ���
acc = (out.ge(0.5).float().squeeze(1)==label).sum().float()/inputs.size()[0]
if (i % 10000 ==0):
plt.scatter(pos_x, pos_y, c='r', marker="*")
plt.scatter(neg_x, neg_y, c='b', marker="^")
weight = model.linear.weight[0]
#print(weight.shape)
wo = weight[0]
w1 = weight[1]
b = model.linear.bias.data[0]
# ���Ʒֽ���
test_x = torch.linspace(-10,10,500) # 500����
test_y = (-wo*test_x - b) / w1
plt.plot(test_x.data.numpy(),test_y.data.numpy(),c="pink")
plt.title("acc:{:.4f},loss:{:.4f}".format(acc,loss))
plt.ylim(-5,3) #�̶ȷ�Χ
plt.xlim(-3,5)
plt.show()
ԭʼ���ݽ��
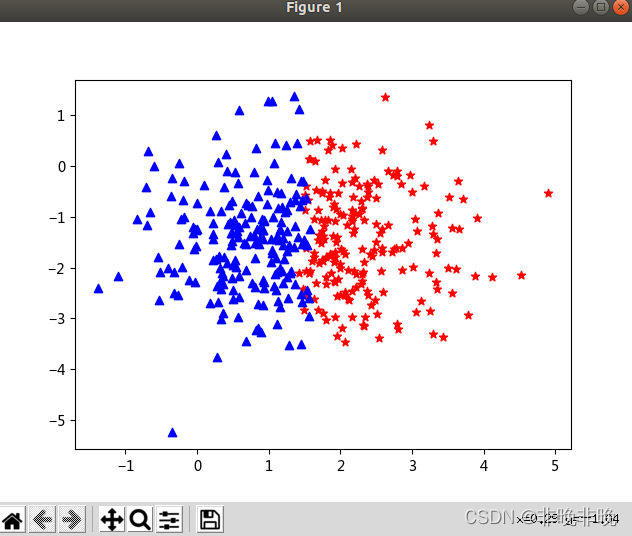
�������: