前言
之前学的用正则表达式从网页中提取数据应该没有什么问题了。但是,网页的源代码是一种结构化的数据,如果仅仅使用正则表达式,那么这种结构化的优势就没有被很好地利用起来。现在举个例子做一下演绎:有一个人,长得非常特别,身高3米,皮肤是绿色。如果他在你眼前,你必定可以一眼认出他。可是,现在只知道他在地球上,应该如何找到他?到全世界的每个地方都去看一下,直到遇到他为止。这种做法理论上当然没有问题,但却费时费力,而且人生苦短,可能一辈子也碰不到。但如果现在知道了他的地址“中国,南京,江宁区,XX路,XX号,第x层楼”,要找到他就易如反掌了。接下来我们一起学习:
(1)HTML基础结构
(2)使用XPath从HTML源代码中提取有用信息
(3)使用Beautiful Soup4从HTML源代码中提取有用信息
一、HTML基础结构
HTML也就是前面章节提到的网页源代码,是一种结构化的标记语言,HTML可以描述一个网页的结构信息。
HTML与CSS(Cascading Style Sheets,层叠样式表)、JavaScript 一起构成了现代互联网的基石。
先以地名为例,来看HTML代码的结构关系:
<!-- 国家 -->
<中国>
<!-- 省份 -->
<山东>
<!-- 地级市/区 -->
<枣庄></枣庄>
<青岛></青岛>
</山东>
<江苏>
<南京></南京>
<南通></南通>
</江苏>
<北京>
<海淀区>
<!-- 街道 -->
<五道口>
<!-- 店铺 -->
××小吃
</五道口>
</海淀区>
</北京>
</中国>
在这个以地名表示HTML结构的例子中,出现了很多用尖括号括起来的地名,而且这些地名都是成对出现的。有<北京>就有</北京>,有<山东>就有</山东>。在HTML中,这叫作(双)标签。
一个标签可以表示为:
<标签名>
文本
</标签名>
不加斜杠,表示标签开始;加上斜杠,表示标签结束。它们中间的部分,就是标签里面的元素。标签里面可以是另一个标签,也可以是一段文本。标签可以并列,也可以嵌套,例如 <北京> 与 <山东> 就属于并列关系。而 <北京> 与 <海淀区> 就是属于嵌套的关系。
再来看一段真正的 HTML 代码的结构:
<!-- 文档定义 document text-->
<!DOCTYPE html>
<!-- 核心部分-->
<html>
<!-- 头信息 --- 仅title部分实时显示的,其余头部信息可在F12开发者模式下查看-->
<head>
<!-- 声明文档使用的字符编码 -->
<meta charset="utf-8" />
<!-- 定义文档的标题 -->
<title>头部信息title</title>
</head>
<!--主体部分:显示效果、组件等-->
<body>
<!-- 元素包含文档的所有内容,比如文本、超链接、图像、表格、列表等等。 -->
<div class="useful">
<ul>
<li class="info">我需要的信息1</li>
<li class="info">我需要的信息2</li>
<li class="info">我需要的信息3</li>
</ul>
</div>
<div class="useless">
<ul>
<li class="info">垃圾信息1</li>
<li class="info">垃圾信息2</li>
</ul>
</div>
</body>
</html>
对比这一段真实的HTML代码和上面地名的例子,可以看到,在结构上面,它们是完全一样的。只不过在真实的HTML代码里面,每个标签除了标签名以外,还有“属性”。一个标签可以有0个、1个或者多个属性,所以一个真正的HTML标签应该是下面这样的:
<标签名 属性1="属性1的值" 属性2="属性2的值"> 显示在网页上的文本 </标签名>
HTML就是通过这样一种一层套一层的结构来描述一个网页各个部分的相对关系的。这里的<html></html>、<div></div>等都是HTML的标签。如果把HTML最外层的标签<html>当作树根,从树根上面分出了两个树枝<head>和<body>,<body>里面又分出了class分别为useful和useless的两个树枝<div>……正如北京在中国里面,海淀区在北京里面……因此,根据每个树枝独特的标志,一步一步找下去,就可以找到特定的信息。
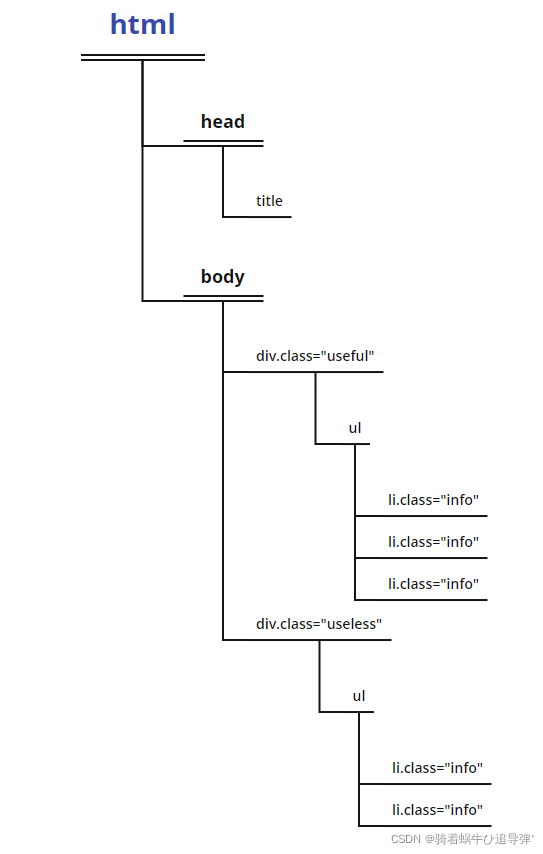
二、XPath
1、XPath 的介绍
XPath(XML Path)是一种查询语言,它能在XML(Extensible Markup Language,可扩展标记语言)和HTML的树状结构中寻找结点。
形象一点来说,XPath 就是一种根据“地址”来“找人”的语言。
需要寻找的内容越复杂,构造正则表达式所需要花费的时间也就越多。而XPath却不一样,熟练使用XPath以后,构造不同的XPath,所需要花费的时间几乎是一样的,所以用XPath从HTML源代码中提取信息可以大大提高效率。
在Python中,为了使用XPath,需要安装一个第三方库:lxml。在pycharm 中导入即可:
2、XPath 语法讲解
2.1 基本语法
使用XPath的代码如下:
import lxml html
selector = lxml.fromstring('网页源代码')
info = selector.xpath('一段XPath语句')
其中的“网页源代码”可以使用requests来获取,“一段XPath语句” 可以按照一定的规则来构造。
核心思想:写XPath就是写地址。
获取文本:
//标签1[@属性1="属性值1"]/标签2[@属性2="属性值2"]/..../text()
获取属性值:
//标签1[@属性1="属性值1"]/标签2[@属性2="属性值2"]/..../@属性n
其中,[@属性="属性值"]不是必需的。它的作用是帮助过滤相同的标签;在不需要过滤相同标签的情况下可以省略。
2.2 省略
标签1可以直接从html这个最外层的标签开始,一层一层往下找,这个时候,XPath语句是这样的:
/html/body/div[@class="useful"]/ul/li/text()
当以html开头的时候,它前面是单斜线。这样写虽然也可以达到目的,但是却多此一举。正如在淘宝买东西时,没有人会把收货地址的形式写为“地球,亚洲,中国,南京,江宁区,××路,××号”一样。地址前面的“地球,亚洲,中国”写了虽然也没错,但却没有必要。谁都知道全世界只有一个南京。而南京必定在中国,中国必定在亚洲,亚洲必定在地球上。所以,写收货地址的时候,直接写南京就可以了,前面的“地球,亚洲,中国”可以省略。XPath也是同样的道理。在XPath里面找到一个标志性的“地标”,然后从这个标志性的“地标”开始往下找就可以了,标志性的“地标”前面的标签都可以省略。
<div class="useful">
<ul>
<li class="info">我需要的信息1</li>
<li class="info">我需要的信息2</li>
<li class="info">我需要的信息3</li>
</ul>
</div>
<ul>标签本身就没有属性,则写XPath的时候,其属性可以省略。
标签有属性,但是如果这个标签的所有属性值都相同,则可以省略属性,例如<li class="info">,所有的<li>标签都有一个class属性,值都为info,所以属性可以省略。
如果要从上述的HTML代码中提取出以下信息,该怎么办?
- 我需要的信息1
- 我需要的信息2
- 我需要的信息3
# 首先格式化一下html字串,转为html
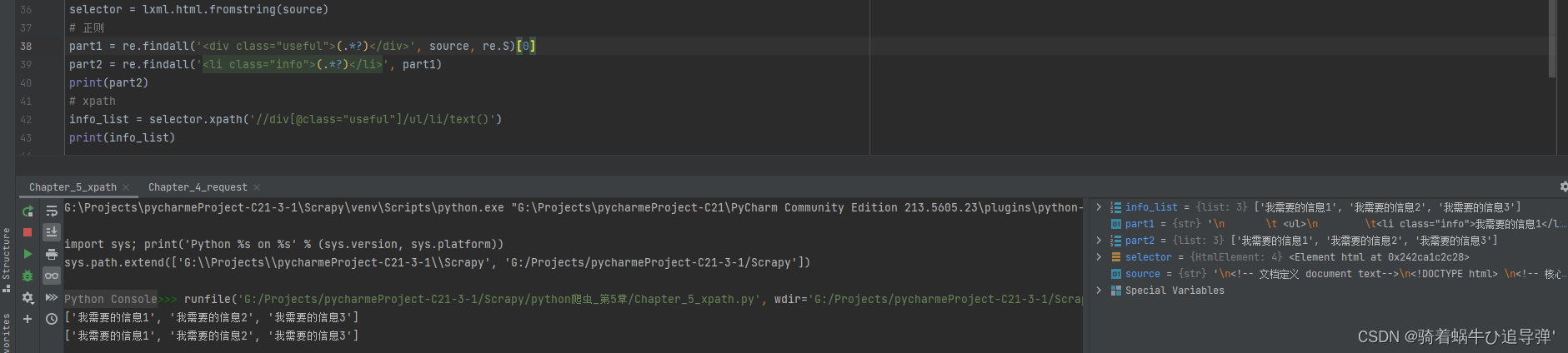
selector = lxml.html.fromstring(source)
# 使用xpath解析
info_list = selector.xpath('//div[@class="useful"]/ul/li/text()')
# 使用正则
# 首先获取 class="useful" 中的内容
part1 = re.findall('<div class="useful">(.*?)</div>', source, re.S)[0]
# 然后在 useful 信息中查询 info 信息
part2 = re.findall('<li class="info">(.*?)</li>', part1)
2.3 特殊写法
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test-1">需要的内容1</div>
<div id="test-2">需要的内容2</div>
<div id="testfault">需要的内容3</div>
<div id="useless">这是我不需要的内容</div>
</body>
</html>
如果我们要获取上述的内容1、2、3的所有内容,常理来说依次获取id="test-1"、id="test-2"、id="testfault" 的内容即可,那样需要编写3条xpath语句,我们可以使用如下方式进行获取:
selector = lxml.html.fromstring(html)
content = selector.xpath('//div[starts-with(@id, "test")]/text()')
for each in content:
print(each)
需要的内容1
需要的内容2
需要的内容3
<body>
<div id="test-1-k">需要的内容1</div>
<div id="test-2-k">需要的内容2</div>
<div id="testfault-k">需要的内容3</div>
<div id="uselessk">这是我不需要的内容</div>
</body>
Xpath:content = selector.xpath('//div[ends-with(@id, "test")]/text()') 可能会有版本问题
<body>
<div id="abc-key-x">需要的内容1</div>
<div id="123-key-000">需要的内容2</div>
<div id="haha-key">需要的内容3</div>
<div id="useless">这是我不需要的内容</div>
</body>
Xpath:content = selector.xpath('//div[starts-with(@id, "test")]/text()')
2.4 对XPath返回的对象执行XPath
XPath也支持先抓大再抓小。还是以4.1节中的HTML代码为例,可以通过下面的代码来获取需要的信息:
//div[@class="useful"]/ul/li/text()
同时,还可以先抓取useful标签,再对这个标签进一步执行XPath,获取里面子标签的文字。
useful = selector.xpath('//div[@class="useful"]') #这里返回一个列表
info_list = useful[0].xpath('ul/li/text()')
print(info_list)
我需要的信息1
我需要的信息2
我需要的信息3
需要注意的是,在对XPath返回的对象再次执行XPath的时候,子XPath开头不需要添加斜线,直接以标签名开始即可。
2.5 不同标签下的文字
html = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test3">
我左青龙,
<span id="tiger">
右白虎,
<ul>上朱雀,
<li>下玄武。</li>
</ul>
老牛在当中,
</span>
龙头在胸口。
</div>
</body>
</html>
'''
期望把“我左青龙,右白虎,上朱雀,下玄武,老牛在当中,龙头在胸口”全部提取下来。如果直接以下面这个XPath语句来进行提取:
selector = lxml.html.fromstring(html)
content_1 = selector.xpath('//div[@id="test3"]/text()')
for each in content_1:
print(each)
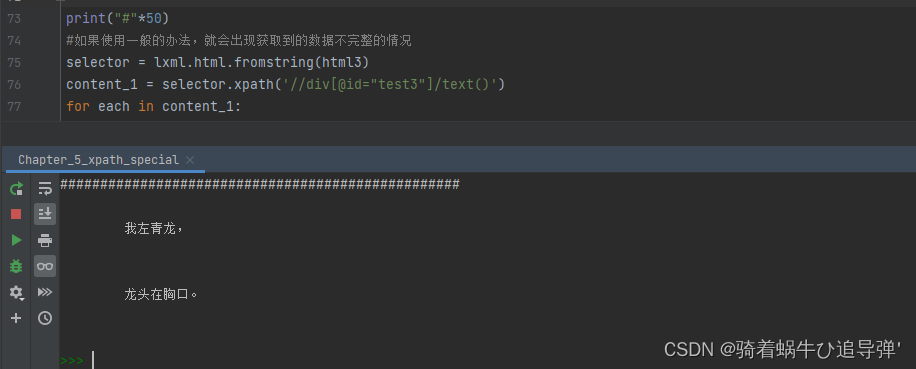
因为只有“我左青龙”和“龙头在胸口”这两句是真正属于这个<div>标签的文字信息,XPath并不会自动把子标签的文字提取出来。在这种情况下,就需要使用string(.)关键字了。首先像先抓大再抓小一样,先获取<div id="test3">这个结点,但是不获取里面的东西。接着对这个结点再使用一次XPath,提取整个结点里面的字符串。
# 使用string(.)就可以把数据获取完整
data = selector.xpath('//div[@id="test3"]')[0]
info = data.xpath('string(.)')
print(info)
我左青龙,
右白虎,
上朱雀,
下玄武。
老牛在当中,
龙头在胸口。
2.5 使用Google Chrome浏览器辅助构造XPath
在构造XPath语句的过程中,需要寻找“标志性”的标签。但是如果遇到混乱的源代码,就不能单纯靠眼睛来看了。
借助Google Chrome浏览器来协助分析网页结构,可以大大提高分析效率。
Google Chrome自带的开发者工具可以将网页源代码转换为树状结构,大大提高网页的可读性。
打开开发者工具后,使鼠标指针在开发者窗口中的HTML代码中移动,可以看到页面上不同的地方会高亮,说明当前鼠标指针指向的这个标签,就对应了网页中高亮的这一部分的代码。除了根据代码找网页位置,还可以根据网页位置找代码。
此时,开发者工具窗口高亮显示的这一行代码,即为这个帖子标题所在的HTML源代码的位置。在上面单击右键,选择“Copy”→“Copy XPath”命令,寻找一个可以输入文字的地方,把结果粘贴下来,可以看到如下的XPath语句:
//*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]

三、Beautiful Soup4
1、Beautiful Soup4的简介
Beautiful Soup4(BS4)是Python的一个第三方库,用来从HTML和XML中提取数据。
Beautiful Soup4在某些方面比XPath易懂,但是不如XPath简洁,而且由于它是使用Python开发的,因此速度比XPath慢。
2、Beautiful Soup4的安装
pycharm环境安装即可,注意:这里的数字“4”不能省略,因为还有一个第三方库叫作beautifulsoup,但是它已经停止开发了:
2、BS4语法讲解
使用Beautiful Soup4提取HTML内容,一般要经过以下两步:
(1)处理源代码生成BeautifulSoup对象。
(2)使用find_all()或者find()来查找内容。
2.1 解析源代码
解析源代码生成BeautifulSoup对象,使用以下代码:
soup = BeautifulSoup(网页源代码,'解析器');
这里的“解析器”,可以使用html.parser:
soup = BeautifulSoup(source,'html.parser');
如果安装了lxml,还可以使用lxml:
soup = BeautifulSoup(source,'lxml');
2.2 查找内容
查找内容的基本流程和使用XPath非常相似。首先要找到包含特殊属性值的标签,并使用这个标签来寻找内容。
<html>
<head>
<title>测试</title>
</head>
<body>
<div class="useful">
<ul>
<li class="info">我需要的信息1</li>
<li class="test">我需要的信息2</li>
<li class="iamstrange">我需要的信息3</li>
</ul>
</div>
<div class="useless">
<ul>
<li class="info">垃圾1</li>
<li class="info">垃圾2</li>
</ul>
</div>
</body>
</html>
假设需要获取“我需要的信息2”,由于这个信息所在<li>标签的class属性的值为“test”,这个值本身就很特殊,因此可以直接通过这个值来进行定位:
from bs4 import BeautifulSoup
import requests
import re
html = requests.get('http://exercise.kingname.info/exercise_bs_1.html').content.decode()
# 生成BeautifulSoup对象
soup = BeautifulSoup(html, 'lxml')
info_2 = soup.find(class_='test')
print(f'使用find方法,返回的对象类型为:{type(info_2)}')
print(info_2.string)
使用find方法,返回的对象类型为:<class 'bs4.element.Tag'>
我需要的信息2
由于HTML中的class属性与Python的class关键字相同,因此为了不产生冲突,BS4规定,如果遇到要查询class的情况,使用“class_”来代替。在第9行的查询HTML代码中,class属性的属性值为“test”的标签,得到find()方法返回的BeautifulSoup Tag对象。在第11行中,直接通过.string属性就可以读出标签中的文字信息。
那如果要获取“我需要的信息1”“我需要的信息2”和“我需要的信息3”,又应该怎么办呢?先抓大再抓小的技巧依然有用:
useful = soup.find(class_='useful')
all_content = useful.find_all('li')
for li in all_content:
print(li.string)
我需要的信息1
我需要的信息2
我需要的信息3
寻找以“我需要”开头的信息:
content = soup.find_all(text=re.compile('我需要'))
for each in content:
print(each.string)
我需要的信息1
我需要的信息2
我需要的信息3
除了获取标签里面的文本外,BS4也可以获取标签里面的属性值。如果想获取某个属性值,可以将BeautifulSoup Tag对象看成字典,将属性名当作Key:
from bs4 import BeautifulSoup
import requests
import re
html = requests.get('http://exercise.kingname.info/exercise_bs_1.html').content.decode()
soup = BeautifulSoup(html, 'lxml')
useful = soup.find(class_='useful')
all_content = useful.find_all('li')
for li in all_content:
print(li['class'])
['info']
['test']
['iamstrange']
四、阶段案例 ― 豆瓣电影排行爬虫
目标网站:https://movie.douban.com/chart
目标内容:豆瓣电影排行榜,有10部榜单电影,信息包括电影名称、上映时间、演员等信息、评分、评论数。
任务要求:使用XPath或者Beautiful Soup4完成。将结果保存为CSV文件。
涉及的知识点:
(1)使用 requests 获取网页源代码。
(2)使用 XPath 或者 Beautiful Soup4。
(3)使用 Python 读/写 CSV 文件。
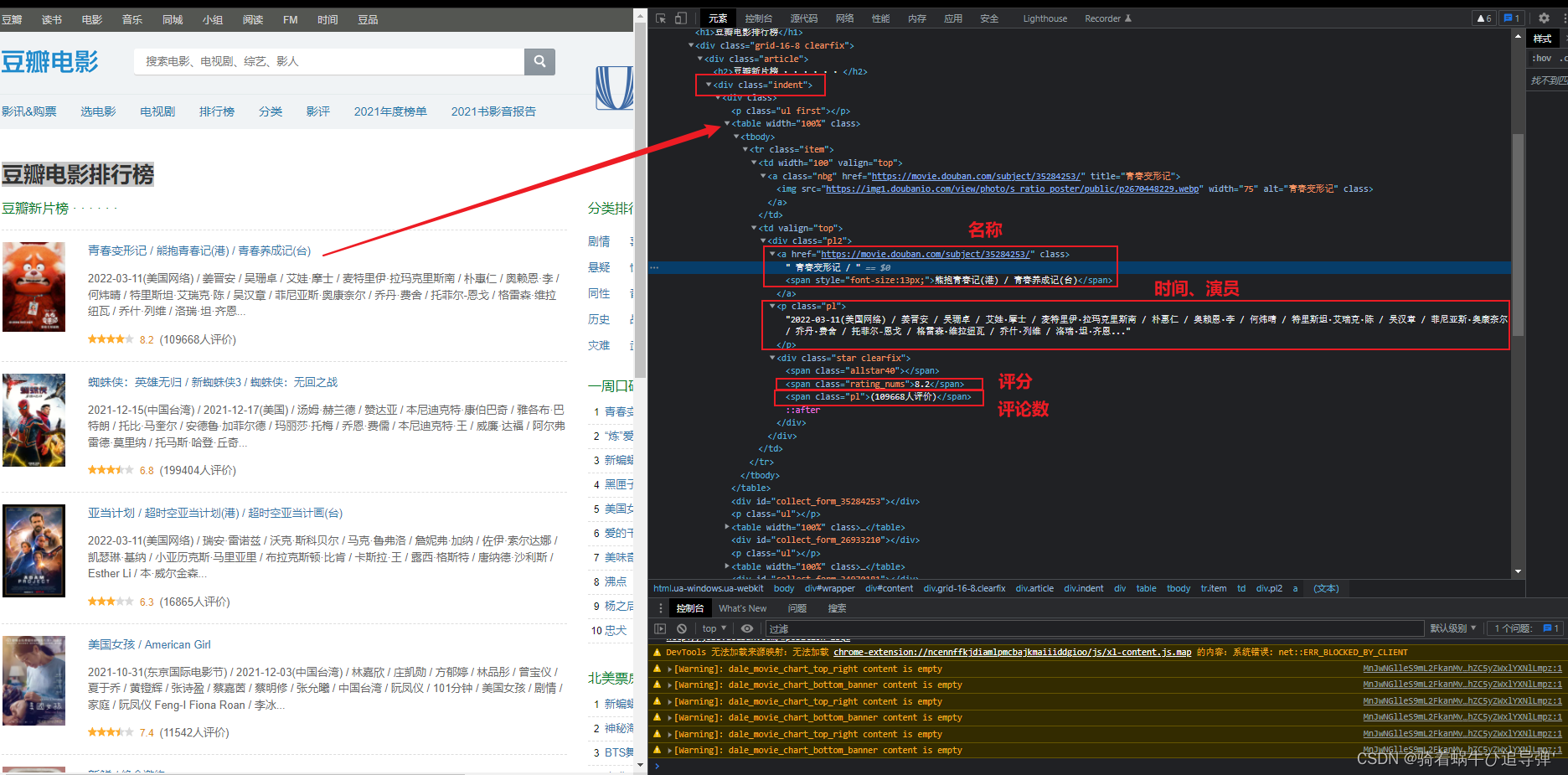
通过分析网页的原码我们可以看出,每部电影的信息全部存储在一个 <div class="indent">...</div> 中的 <table>标签下,所以我们首先要获取当前页面中所有的 <table> 中的网页内容,然后逐个去分析获取数据。
1、获取电影模块信息
import csv
import requests
import lxml.html
# 目标地址
url = "https://movie.douban.com/chart"
# 头部信息
user_agent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36'}
# request请求获取页面内容
html = requests.get(url=url, headers=user_agent).text
# 使用xpath解析
selector = lxml.html.fromstring(html)
# 定位到每个table标签,获取其内容
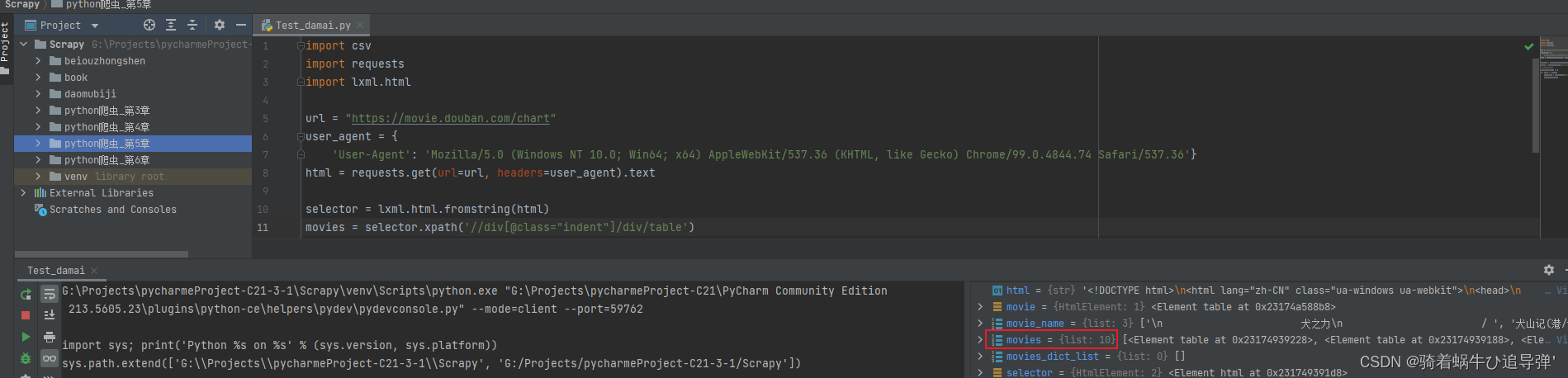
movies = selector.xpath('//div[@class="indent"]/div/table')
定位到每个table标签,获取其内容(10部电影,对应10个HtmlElement对象):
2、获取电影名称
# 遍历每个table标签的内容,获取每部电影的信息
movies_dict_list = []
for movie in movies:
# 获取电影的名称
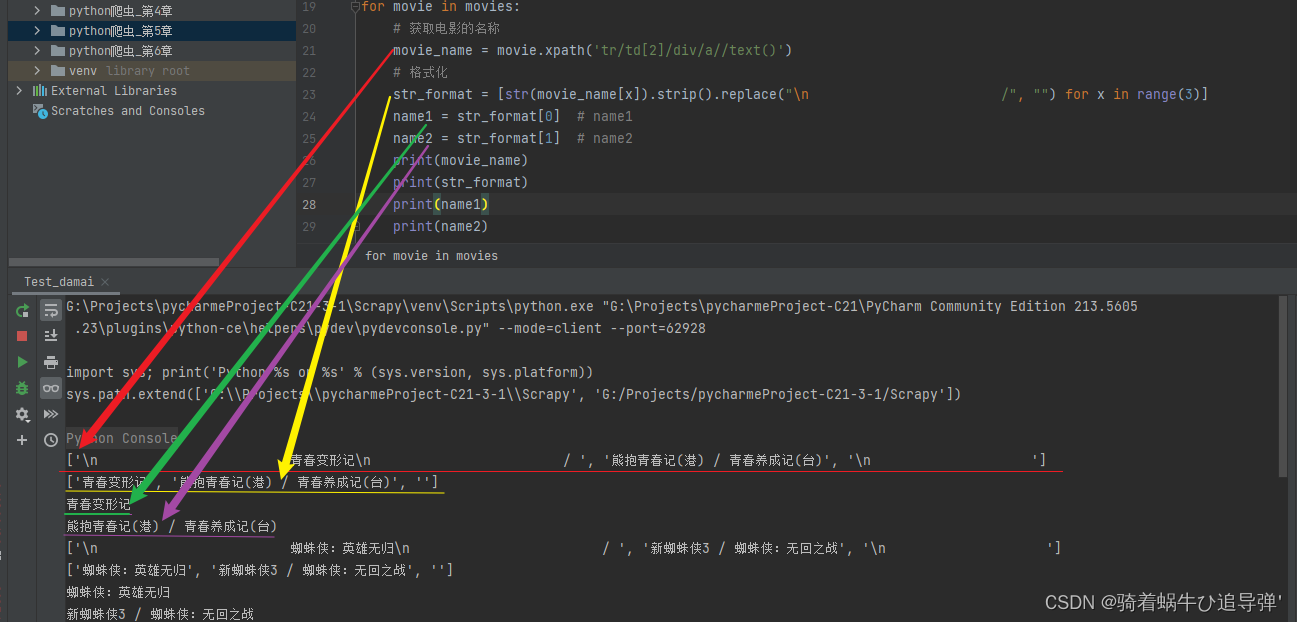
movie_name = movie.xpath('tr/td[2]/div/a//text()')
# 格式化
str_format = [str(movie_name[x]).strip().replace("\n /", "") for x in range(3)]
name1 = str_format[0] # name1
name2 = str_format[1] # name2
print(movie_name)
print(str_format)
print(name1)
print(name2)
遍历每个电影模块的信息,使用xpath定位到 <a> 标签下的所有内容,注意写法:tr/td[2]/div/a//text() ,<a> 标签后面多写一个 / 表示其下所有的内容,包括子标签的。获取标题后我们对其进行格式化,并将其分为name1、name2:
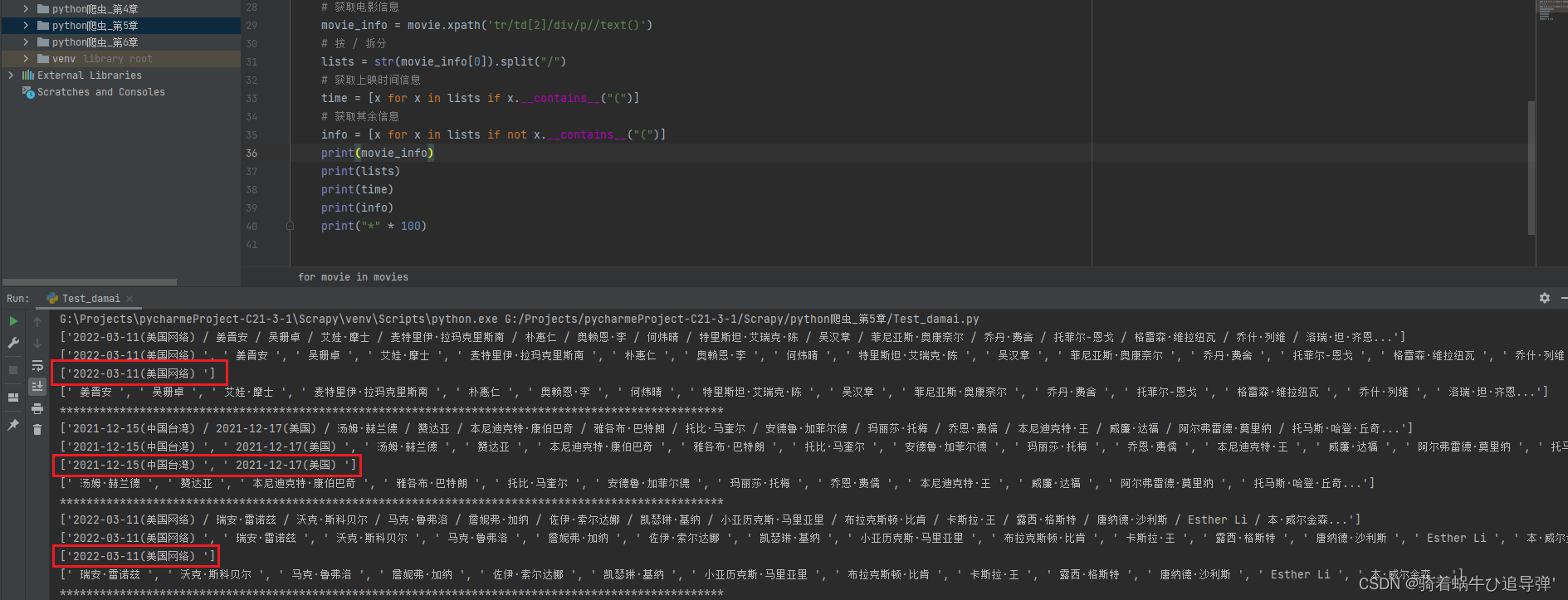
3、获取电影上映时间及其余信息
# 获取电影信息
movie_info = movie.xpath('tr/td[2]/div/p//text()')
# 按 / 拆分
lists = str(movie_actors[0]).split("/")
# 获取上映时间信息
time = [x for x in lists if x.__contains__("(")]
# 获取其余信息
info = [x for x in lists if not x.__contains__("(")]
print(movie_actors)
print(lists)
print(time)
print(info)
print("*" * 100)
通过观察获取的电影信息数据,其中包含了电影的上映时间、演员、分类(有的有,有的没有)等信息,因为上映时间基本全有,所以我们将其拆分为两部分:上映时间、其余电影信息:
返回顶部
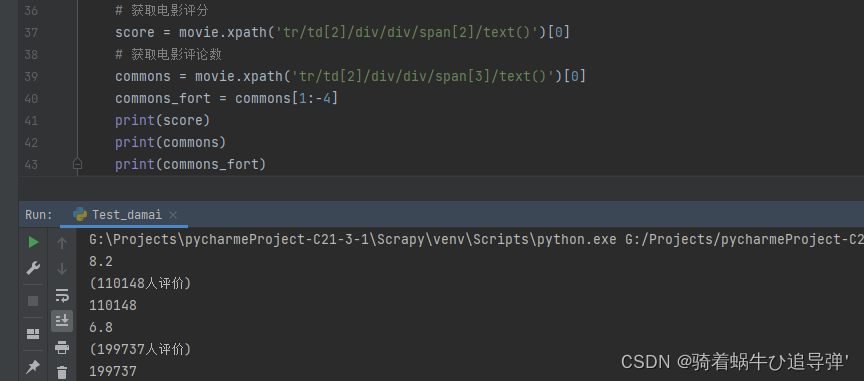
4、获取电影评分、评论数
# 获取电影评分
score = movie.xpath('tr/td[2]/div/div/span[2]/text()')[0]
# 获取电影评论数
commons = movie.xpath('tr/td[2]/div/div/span[3]/text()')[0]
commons_fort = commons[1:-4]
print(score)
print(commons)
print(commons_fort)
通过xpath的定位分别获取电影的评分、评论数信息,再将其进行初步的格式化:
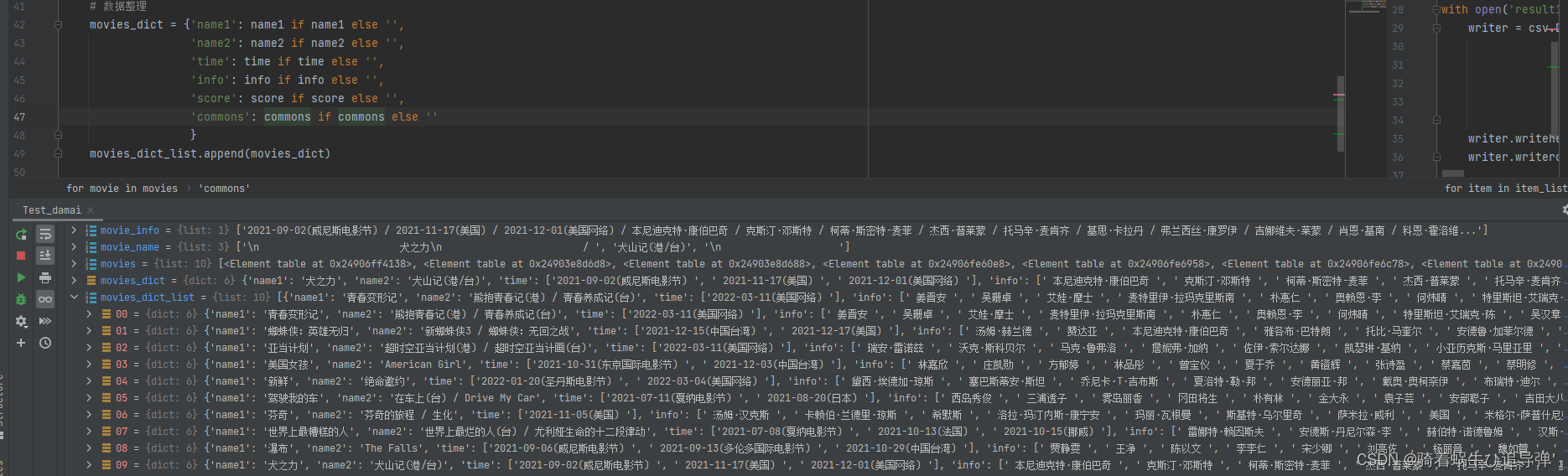
5、获取每部电影的所有信息
# 数据整理
movies_dict = {'name1': name1 if name1 else '',
'name2': name2 if name2 else '',
'time': time if time else '',
'score': score if score else '',
'commons': commons_fortif commons_fortelse '',
'info': info if info else '',
}
movies_dict_list.append(movies_dict)
将每部电影的信息存放在字典中,所有的电影信息存放在一个 movies_dict_list 中聚合:
返回顶部
6、存储爬取数据为 csv
# 存储csv文件
with open('movies.csv', 'w', encoding='utf-8', newline='') as f:
# 配置writer
writer = csv.DictWriter(f, fieldnames=['name1', 'name2', 'time', 'score', 'commons', 'info'])
# 写入头部信息
writer.writeheader()
# 写入数据
writer.writerows(movies_dict_list)
最后将 movies_dict_list 的数据以 csv 文件的形式写出即可:

👉👉👉 完整代码及相关资源下载 !🐌🐌🐌