Selenium�Զ�������
��˵��:���ѧϰ��һ��python����,Ȼ�������漰��������һ�ż���,�Ṧ��ǿ��,��ֻ�Ǹ�����,��ʵ�����Զ��ٶȵĹ���,��������Ļ���ӵ��Զ�,�����ڿ�����
Selenium�Ļ�������
1.ʲô��selenium?
(1)Selenium��һ������WebӦ�ó�����ԵĹ��ߡ�
(2)Selenium ����ֱ���������������,�����������û��ڲ���һ����
(3)֧��ͨ������driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)����
��ʵ�������ɲ��ԡ�
(4)seleniumҲ��֧����������������ġ�
2.Ϊʲôʹ��selenium?
ģ�����������,�Զ�ִ����ҳ�е�js����,ʵ�ֶ�̬����
3.��ΰ�װselenium?
(1)�����ȸ�������������ص�ַ
http://chromedriver.storage.googleapis.com/index.html
(2)�ȸ������ȸ�������汾֮���ӳ���
http://blog.csdn.net/huilan_same/article/details/51896672
(3)�鿴�ȸ�������汾
�ȸ���������Ͻǩ\�\>�����\�\>����
(4)pip install selenium
4.selenium��ʹ�ò���?
(1)����:from selenium import webdriver
(2)�����ȸ��������������:
path = �ȸ�����������ļ�·��
browser = webdriver.Chrome(path)
(3)������ַ
url = Ҫ���ʵ���ַ
browser.get(url)
�������ԡ�
����:��selenium�Զ��ٶ���ҳ,Ȼ���Զ��������dz�,Ȼ��ٶ�һ��,������ײ�,Ȼ������һҳ,Ȼ��,Ȼ��ر��˳���
1.���ȵ���,Ȼ�����������,��һ����ҳ��
#1.����
from selenium import webdriver
#�����صĹȸ�����������Ž���,�������һ���ļ���
path='chromedriver.exe'
#�������������,����ʹ�õ�chrome,��Ȼ��Ҳ֧�����������������,������ѡ��
browser=webdriver.Chrome(path)
#url
url='https://www.baidu.com'
browser.get(url)
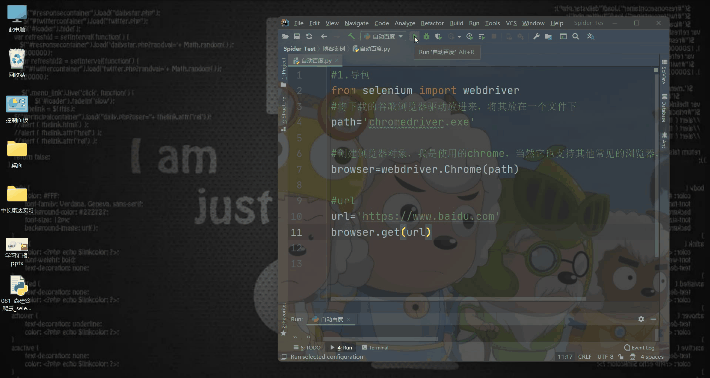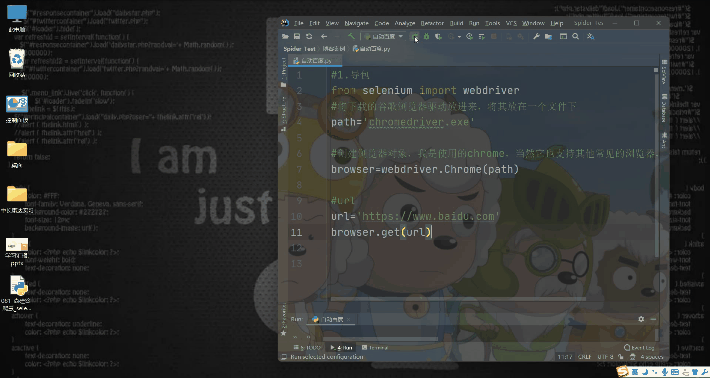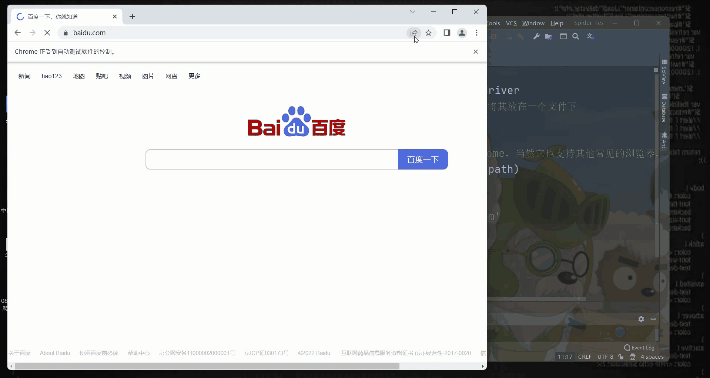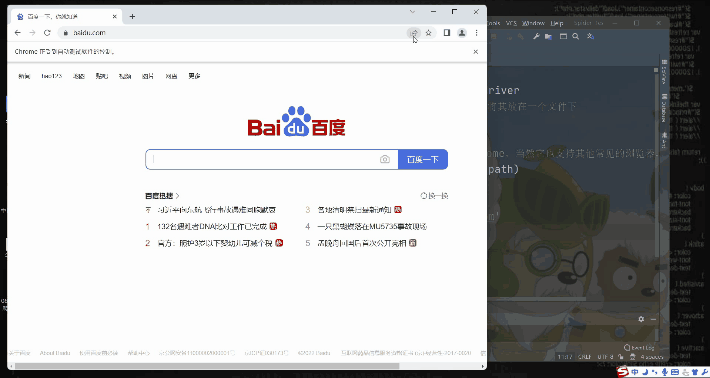
�ٶ���ҳЧ��ͼ:
2.Ȼ����ǻ�ȡ��ҳ������ı����������,���о��ǰٶ�һ�¶���
#ͨ��Դ�뿴���ǵ�id,�Ϳ��Ի�ȡ����������
input = browser.find_element_by_id('kw')
input = browser.find_element_by_id('su')
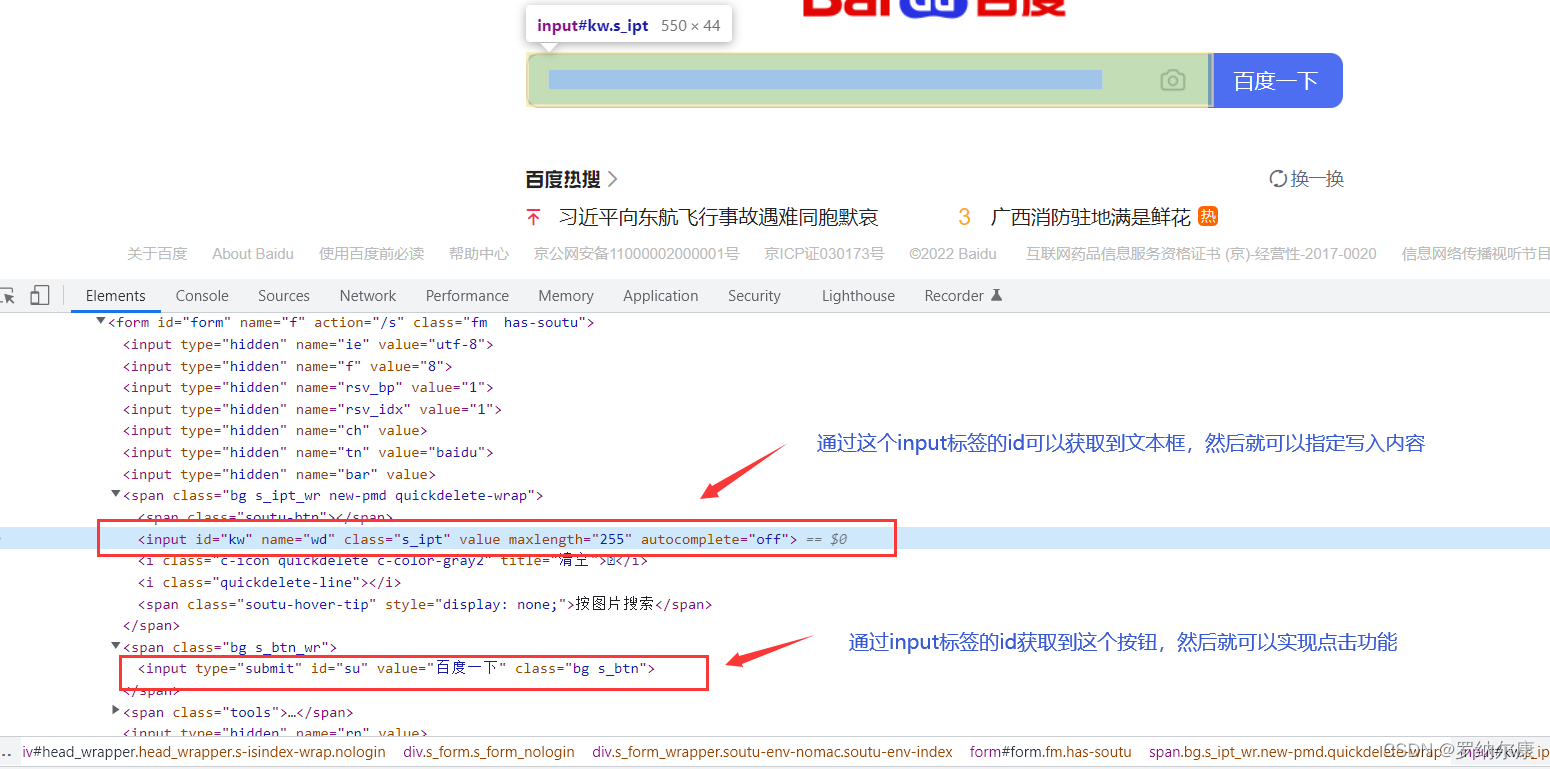
3.д������,ʵ�ֵ��
# ���ı������������dz�
input.send_keys('���dz�')
#ʵ�ֵ���ٶ�һ��
button.click()
4.������һҳ,ʵ�ֻ����ײ�
# �����ײ�,�̶�д��
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)
5.Ȼ��ͬ�ڶ���һ����ԭ��,��ȡ��һҳ�Ķ���,ʵ�ֵ�����ܡ�
# ��ȡ��һҳ�İ�ť
next = browser.find_element_by_xpath('//a[@class="n"]')
# �����һҳ
next.click()
6.�ص���һҳ�ͷ���,���ҹر��˳�
# �ص���һҳ
browser.back()
# ��ȥ
browser.forward()
# �˳�
browser.quit()
��̬ͼƬ:

��β��Թ���,�����Զ��»���ʱ���������֤,������Ҫ��selenium��Ҫ���������ʹ��,��������Chrome handless
Chrome-headless ģʽ, Google ��� Chrome ����� 59�� �����ӵ�һ��ģʽ,�������㲻��UI����������
ʹ�� Chrome �����,��������Ч���� Chrome ��������һ�¡� �Ͳ���Ҫÿ�ζ�����,Ҳ���Խ��иò���,����ѡ�����ʱ���п��յķ�ʽ,����ͼƬ,Ҳ���ӵ�ʡЧ��,�ƹ���¼�Ļ�,����Ҫ�����������һ��ʹ��,ʹ�����Ч,���ܸ�ǿ��
��������:
#1.����
from selenium import webdriver
#�����صĹȸ�����������Ž���,�������һ���ļ���
path='chromedriver.exe'
#�������������,����ʹ�õ�chrome,��Ȼ��Ҳ֧�����������������,������ѡ��
browser=webdriver.Chrome(path)
#url
url='https://www.baidu.com'
browser.get(url)
import time
#��������һ��,���·�Ӧ,����Ա�
time.sleep(1)
# ��ȡ�ı���Ķ���
input = browser.find_element_by_id('kw')
# ���ı������������dz�
input.send_keys('�ܽ���')
time.sleep(1)
#��ȡ�ٶ�һ�¶���
button = browser.find_element_by_id('su')
#ʵ�ֵ���ٶ�һ��
button.click()
# �����ײ�,�̶�д��
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)
time.sleep(1)
# ��ȡ��һҳ�İ�ť
next = browser.find_element_by_xpath('//a[@class="n"]')
# �����һҳ
next.click()
time.sleep(1)
# �ص���һҳ
browser.back()
time.sleep(1)
# ��ȥ
browser.forward()
time.sleep(1)
# �˳�
browser.quit()