编辑距离
1.基本思想:将一个字符转化为另外一个字符所需的最少操作次数,可以是替换字符,插入字符,删除字符,可用与计算两个文本的相似度
2.算法的基本原理:对于字符串a[1:i]和字符串b[1:j]来说,用edit[i][j]表示它们间的编辑距离。
如果a[i]和b[j]相同,则edit[i][j]=edit[i-1][j-1]。
如果a[i]和b[j]不相同,则有如下情况:
1)a[1:i]经过多次操作转化为b[1:j-1],然后再在结尾插入字符b[j]即可,edit[i][j]=edit[i][j-1]+1;
ac----acy
2)a[1:i-1]经过多次操作转化为b[1:j],然后再将字符a[i]删除即可,edit[i][j]=edit[i-1][j]+1;
acy-----ac
3)a[1:i-1]经过多次操作转化为b[1:j-1],然后再将字符a[i]替换为b[j]即可,edit[i][j]=edit[i-1][j-1]+1;
acx―acy
在这三种情况中取最小值即可。其中edit[0][j]表示将空串转为b[1:j]的操作次数,为j;edit[i][0]表示将a[1:i]转为空串的操作次数,为i。
第一种方法:核心思想是动态规划
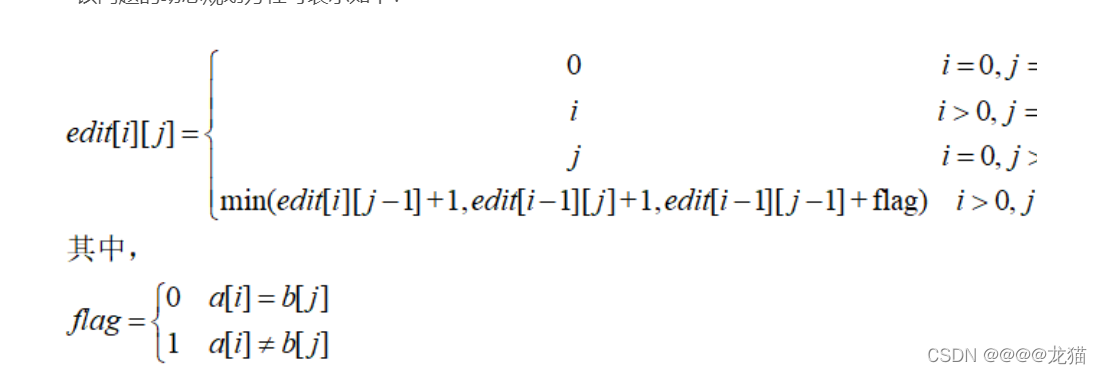
session.txt
绿茶
聚福
蜀香坊
蜀香房
食面
香港
麻辣烫
import numpy
from numpy import matrix
class LevenshteinDistance(object):
def distance(self, a, b):
"""
计算字符串a和b之间的编辑距离
"""
edit = [[0 for j in range(len(b) + 1)] for i in range(len(a) + 1)]
for i in range(len(a)):
edit[i + 1][0] = i + 1
for j in range(len(b)):
edit[0][j + 1] = j + 1
for i in range(len(a) + 1)[1:]:
for j in range(len(b) + 1)[1:]:
flag = b[j - 1] == a[i - 1]
num = 0 if flag else 1
edit[i][j] = min(edit[i - 1][j] + 1, edit[i][j - 1] + 1, edit[i - 1][j - 1] + num)
return edit[-1][-1] # print(edit[len(a)][len(b)])结束索引的位置
def similarity(self, a, b):
"""
计算字符串a和b之间的相似度
"""
m = max(len(a), len(b))
d = self.distance(a, b)
return (m - d) / m
if __name__ == '__main__':
edit = LevenshteinDistance()
list1 = []
result = {}
for line in open("session.txt", "r", encoding="utf-8"):
list1.append(line)
for i in range(0, len(list1)):
for j in range(i+1, len(list1)):
print(list1[i].strip('\n')+" "+list1[j].strip('\n'))
# print(list1[j])
print(edit.distance(list1[i], list1[j]))
print(edit.similarity(list1[i], list1[j]))
# graph = matrix(numpy.identity(len(list1)))
# graph[i][j]=edit.similarity(list1[i], list1[j])
# print(graph)
输出结果:
绿茶 聚福
2
0.3333333333333333
绿茶 蜀香坊
3
0.25
绿茶 蜀香房
3
0.25
绿茶 食面
2
0.3333333333333333
绿茶 香港
2
0.3333333333333333
绿茶 麻辣烫
3
0.25
聚福 蜀香坊
3
0.25
聚福 蜀香房
3
0.25
聚福 食面
2
0.3333333333333333
聚福 香港
2
0.3333333333333333
聚福 麻辣烫
3
0.25
蜀香坊 蜀香房
1
0.75
蜀香坊 食面
3
0.25
蜀香坊 香港
2
0.5
蜀香坊 麻辣烫
3
0.25
蜀香房 食面
3
0.25
蜀香房 香港
2
0.5
蜀香房 麻辣烫
3
0.25
食面 香港
2
0.3333333333333333
食面 麻辣烫
3
0.25
香港 麻辣烫
3
0.25
第二种方法:直接导入第三方库
import Levenshtein # 第三方库实现
def edit_sim(s1, s2):
maxLen = max(len(s1), len(s2))
dis = Levenshtein.distance(s1, s2)
print(dis)
sim = 1 - dis * 1.0 / maxLen
return sim
word1 = '绿茶'
word2 = '聚福'
word_sim = edit_sim( word1, word2 )
print(word_sim)
结果:
2
0.33333333333333337