Linux Python����ʵ��PySlowFast��Ƶ����
https://blog.csdn.net/lly1122334/article/details/118162190
1��ժҪ
���������������Ƶʶ���SlowFast���硣���ǵ�ģ�Ͱ���:
(1)һ��slow pathway,�Ե�֡��������,�Բ���ռ�����;
(2)һ��fast pathway,�Ը�֡��������,�Ծ�ϸ��ʱ��ֱ��ʲ����˶���
fast pathway����ͨ������ͨ����������÷dz�����,������ѧϰ���õ�ʱ����Ϣ������Ƶʶ��ģ������Ƶ��������ͼ�ⷽ�涼ȡ���˽Ϻõ�����,���ǵ�slowfast������������кܴ�ĸĽ�������Kinetics,Charades��AVA�Ȼ���ȡ������õ�Ч����
2������
��ʶ��ͼ��I(x, y)ʱ,ϰ�߶ԳƵش��������ռ�ά��x��y����Ȼͼ���ͳ������֤������Щ������,��ͼ�����ͬ��(���з����ǵȿ��ܵ�)��������Ƶ������ʱ�շ���Ŀ����Բ�����ͬ,�������ȿ춯�������ܷ���(��ʵ��,�������������������ijһʱ�̶����ڽ�ֹ״̬),���ǿ��Էֽ�����ṹ���ֱ����ռ���Ϣ��ʱ���¼���
�ռ䷶��������ݻ�����,������ֲ���ı䡰�֡������,һ���˴Ӳ���תΪ�ܲ�,Ҳ���Ǵ��ڡ��ˡ���������,�Է�������(�Լ����ǵ���ɫ�����������յ�)��ʶ�������Ի�����ˢ�¡�����������ִ�еĶ������Ա����������ݸ���ط�չ,�������֡����֡�ҡ�Ρ�������Ծ����������ʹ�ÿ���ˢ��֡(��ʱ��ֱ���)����Ч��ģ����ܿ��ٱ仯���˶���
������������,�����һ����Ƶʶ���˫·��slowfastģ�͡�������������,slow·����Ȼ��Ϊ�˲���ռ�������Ϣ,���ҹ���˼��,��·���Խϵ͵�֡�ٶȺͽ�����ˢ���ٶ����С�fast·��������ٱ仯���˶�,�Կ���ˢ���ٶȺ�ʱ��ֱ������С���������·�����кܸߵ�ʱ������,�����dz���,Լռ�ܼ�������20%���������ڸ�·���н��ٵ�ͨ���ͽ����������������ռ���Ϣ,��Ϊ�ռ���Ϣ������slow·���ṩ��������path���ɺ��������ںϡ�
fast pathway������������,����Ҫʱ��ػ�����(��Ϊ�������������м��ĸ�֡����������,������ʱ��ȷ��)��slow pathway����ʱ�����ʽ���,���ӹ�ע�ռ����塣ͨ���Բ�ͬ��ʱ�����ʴ���ԭʼ��Ƶ,������;������Ƶ��ģ����ӵ���Լ���רҵ֪ʶ(fast����ʱ����Ϣ,slow���տռ���Ϣ)��
����,����һ����������Ƶʶ��ܹ���two-streamģ��,��Ҳ��˫�����,����û��̽����ͬʱ���ٶȵ�DZ��,���������Ƿ����е�һ���ؼ��������,two-stream������������������ͬ�����ɽṹ,�����ǵĿ���·�����ᡣ���ǵķ������������,���,���ǵ�ģ���Ǵ�ԭʼ���ݶ˵��˵�ѧϰ�ġ���ʵ����,���ǹ۲쵽slowfast����Ч�����Ƕ�kinetics��Ϊ������ۺ�����ʵ��֤����slowfast��Ч������Ҫ����,slowfast ���ĸ����ݼ�(kinetics400,kinetics600,AVA,Charades)�϶�ʵ������ߵ�ˮ��
���ǵķ��������ܵ����鳤���Ӿ�ϵͳ������Ĥ��ϸ��������ѧ�о�������,���ܲ��ɷ����������ǴֲںͲ�����ġ���Щ�о��������,����Щϸ����,��Լ80%��Сϸ��(pϸ��),��Լ15-20%�Ǿ�ϸ��(mϸ��)��mϸ���Ĺ���Ƶ�ʺܸ�,�Կ��ٵ�ʱ��仯�з�Ӧ,���Կռ�ϸ�ڻ���ɫ�����С�pϸ���ṩ���õĿռ�ϸ�ں���ɫ,���ϵ͵�ʱ��ֱ���,�Դ̼���Ӧ���������ǵĿ�������¼������������Ƶ�:(i)���ǵ�ģ��������·���ֱ��ڵͺ�ʱ��ֱ����¹���;(ii)���ǵ�Fast·��ּ�ڲ����ٱ仯���˶�,������Ŀռ�ϸ�ڽ���,����mϸ��;(iii)���ǵ�Fast·������������,������mϸ����С����������ϣ����Щ��ϵ����������ļ�����Ӿ�ģ��������Ƶʶ��
�������������ǵķ�����Kinetics-400,Kinetics-600,Charades,AVA���ݼ��ϡ�������Kinetcs�����������ۺ�����ʵ��֤����SlowFast����Ч�ԡ�
�����������������ݼ��϶�ȡ�������µĽ�չ,����������ǰ��ϵͳ�������Ľ��������ǵ��ۺ�����
2����ع���
ʱ���˲���:�������Ա�ʾΪʱ�ն���,��ͨ��ʱ���еĶ����˲�����,��HOG3D��cuboids��3D ConvNets��2Dͼ��ģ����չ��ʱ����,ͬ������ʱ��ά�ȡ�Ҳ����صķ���רע�ڳ����˲�������ʱ����ijػ�,�Լ��������ֽ�Ϊ�����Ķ�ά�ռ��һάʱ���˲�����
����ʱ�չ��˻���ɷ���汾,���ǵĹ�����ͨ��ʹ�����ֲ�ͬ��ʱ���ٶ��������ط���֪ʶ��ģ��
��Ƶʶ��Ĺ���:���ڹ������ֹ�ʱ��������һ��������о���֧����Щ����,������ֱ��ͼ���˶��߽�ֱ��ͼ�켣,�����ѧϰ�ռ�֮ǰ,��Щ�����Ѿ��ڶ���ʶ������ֳ��˾������ܡ�
�����������ı�����,˫���������ù�����Ϊ��һ������ģ̬���÷��������������ྺ������Ļ�����Ȼ��,���ǵ�������һ���ֹ���Ƶı�ʾ,���ڷ������Dz����������,����˫������������������һ��˵���ѧϰ�ġ�
3��slowfast�������
slowfast������Ա�����Ϊ�����ֲ�ͬ֡�������еĵ�����ϵ�ṹ,������ʹ��·���ĸ�������ӳ�������е�Parvo-��Magnocellular��Ӧ�����ȡ����ǵ�ͨ�üܹ���һ��slow pathway��fast pathway,fast pathwayͨ������������slow pathway �ں��γ�slowfast���硣
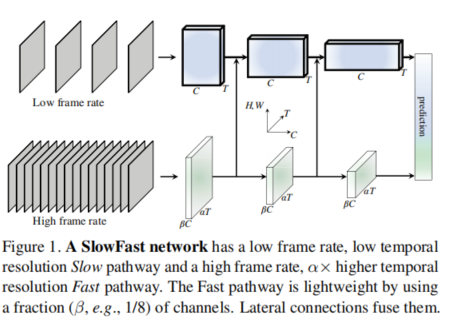 ���Կ���,fast pathway��ʱ��ά�ȷֱ��ʺ�ͨ�����ֱ���slow pathway��a����b����
���Կ���,fast pathway��ʱ��ά�ȷֱ��ʺ�ͨ�����ֱ���slow pathway��a����b����
3.1 slow pathway����
��·���������κξ���ģ�ͽ�һ����Ƶ��Ϊһ��ʱ����������ǵ���·���Ĺؼ�����������֡�ϵĴ�ʱ���Ȧ�,Ҳ����˵,��ֻ������֡�е�һ���������о��Ħӵ�һ������ֵΪ16�����ˢ���ٶ��Ƕ���30֡����Ƶ��Լÿ�����2֡����ʾSlow·��������֡��ΪT, ԭʼ��Ƶ����ΪT �� ������ϵ��
3.2 fast pathway
����·������,Fast·������һ�������������Եľ���ģ�͡�
��֡��: ���ǵ�Ŀ������ʱ��ά������һ�����õı�ʾ�����ǵĿ���·���ڦ� /����Сʱ�����¹���,���Ц� > 1�ǿ��ٺͻ���·��֮���֡���ʱȡ�������;����ͬһ��ԭʼ��Ƶ����������,����Fast;���Ԧ�T֡���в���,���ܶ���Slow;���Ħ����������ǵ�ʵ����,һ������ֵ�Ǧ� = 8��
���Ĵ���slowfast����Ĺؼ�������ȷָ��������·���ڲ�ͬ��ʱ���ٶ��¹���,�Ӷ���������������IJ���ѧϰ����ʵ����������·����
��ʱ��ֱ�������: ���ǵ�Fast·���������и�����ֱ���,������߷ֱ��������ᴩ�����������С������ǵ�ʵ������,����������Fast·����û��ʹ��ʱ���²�����(��û��ʱ���Ҳû��ʱ���Ⱦ���),ֱ������֮ǰ��ȫ�ֳػ��㡣���,���ǵ�����������ʱ��ά���������Ц�T֡,�����ܵر���ʱ�䱣��ȡ�
��ͨ������: ���ǵĿ���·��Ҳ������ģ�͵���������,������ʹ�������ؽϵ͵��ŵ�������ʵ�����õ�ȷ��SlowFastģ�͡���ʹ�������ᡣ
�����֮,���ǵ�Fast pathway��һ��������Slow·���ľ�������,����һ���±��ʵ�(��<1)��ͨ���������ǵ�ʵ����,����ֵ�Ǧ� = 1/8����ע��,������ļ���(����������,��FLOPs)ͨ������ͨ�������Ķ����͡������fast pathway��slow pathway����Ч�ʸ��ߵ�ԭ�������ǵ�ʵ������,Fast pathwayͨ��ռ���ܼ�������20%����Ȥ����,�����һ�����ᵽ��,֤�ݱ����鳤���Ӿ�ϵͳ��15-20%������Ĥϸ����mϸ��(�Կ����˶�����,������ɫ��ռ�ϸ�ڲ�����)��
���ŵ�����Ҳ���Խ���Ϊ�����Ŀռ���������������Ӽ����Ͻ�,Fast pathwayû�жԿռ�ά�Ƚ��������,�������ͨ������,��ռ佨ģ����Ӧ�õ���Slow pathway��ģ�ͽ������,Fast pathway ��������ռ佨ģ������ͬʱ��ǿ��ʱ�佨ģ������һ����������ԡ�
������һ����,���ǻ�̽������Fast pathway�������ռ������IJ�ͬ��ʽ,������������ռ�ֱ��ʺ�ȥ����ɫ��Ϣ���������ǽ�ͨ��ʵ��֤��������,��Щ�汾�������ṩ���õ�ȷ��,��������н��ٿռ�������������Fast pathway������ġ�
3.3 ��������
������pathway����Ϣ���ں�,��������һ��·�������Dz�֪����һ��·��ѧϰ���ı���������ͨ������������ʵ����һ��,���������ѱ������ںϻ��ڹ������������硣��ͼ��Ŀ������,����������һ�����е��ںϲ�ͬ�ռ�ֱ��ʺ�����ļ�����
������[12,35],������ÿһ���ζ�������ͨ·֮�丽��һ���������ӡ�(ͼ1)���ر���ResNets[24],��Щ���ӽ�����pool1��res2��res3��res4֮��������·���в�ͬ��ʱ��ά��,��˺�������ִ��ת����ƥ������(���3.4��)������ʹ�õ�������,��Fast·���������ںϵ�Slow·����(ͼ1)�����Ƕ�˫���ںϽ�����ʵ��,���������ƵĽ����
���,��ÿ��·�������ִ��һ��ȫ��ƽ���ء�Ȼ�������ϲ���������������������Ϊȫ���ӷ�����������롣
3.4 ʵ����
���ǹ���SlowFast���뷨��ͨ�õ�,�������ò�ͬ��backbone(����,[45,47,24])��ʵ��ϸ�ڽ���ʵ�����������С����,���ǽ���������ܹ���ʵ����
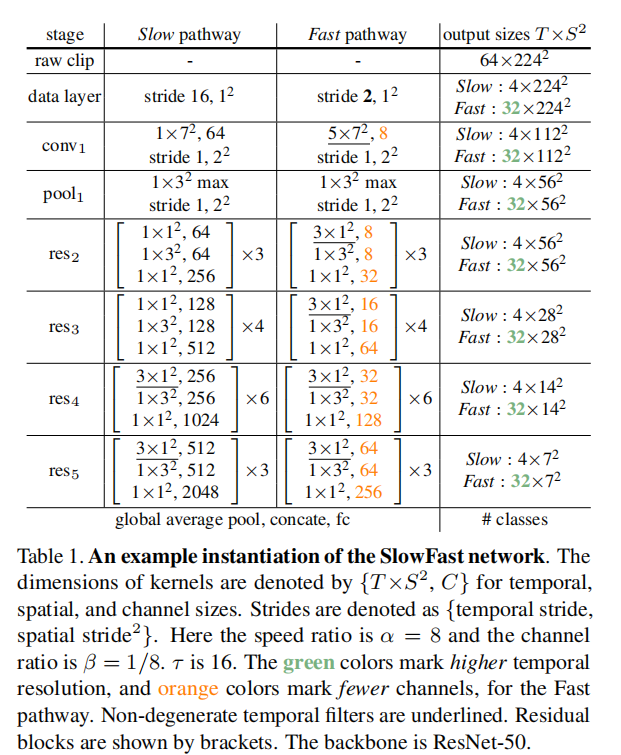
��1��ָ����һ��ʾ��SlowFastģ�͡�������T*S^2��ʾʱ�մ�С,����T��ʱ�䳤��,S�Ƿ��οռ�����ĸ߶ȺͿ��ȡ����潫��ϸ������
Slow-pathway:��1�е�slow-pathway��һ����ʱ��Խ��3D ResNet,��[12]�Ķ���������T = 4֡��Ϊ��������,ϡ��ش�64֡ԭʼ������ʱ���Ȧ� = 16�����������ʵ������,����ѡ��ִ��ʱ���²���,��Ϊ�����벽���ܴ�ʱ���������к��ġ�
����͵�C3D / I3Dģ�Ͳ�ͬ,����ʹ�÷Ǽ�ʱ�����(ʱ��˴�С>1,��1�л���)����res4��res5��;��conv1��res3�������˲��������϶������·���еĶ�ά�����ˡ����������ǵ�ʵ��۲������,�����ڲ���ʹ��ʱ������ή�;��ȡ�������Ϊ,������Ϊ�������ƶ�����ʱ���ȴ�ʱ,���ǿռ�������㹻��(���ں���IJ����),����ʱ��������ڼ���û������ԡ�
�������
TSN
����ָ����CNN����action recgonition�е�����ȱ��
(1)��Ƶ��һ����ʱ��ṹ��,��������CNNֻרע�ھ�̬ͼ����ʱ��ͼ��
(2)���еĹ�����ע��Ƶ��Դ̫��,ʹ������CNN�ܿ��ܻᵼ�¹���ϡ�
�����������������:
(1)��ô�����һ����Ч����Ƶ�������������ʶ��
(2)�����ı�ע��Դ��,����ѵ��CNNģ�͡�
���˼��:
(1)��ѵ��ģ���з���Dense temporal sampling����ڴ����߶����Ƶ�֡,Ϊ����������,�����TSN����,����Ƶ��Ϊ���snippets(Ƭ��),ÿ��ѵ�����Ǵ�ÿ��snippet�������֡,����������л���,�õ����ս����
(2)���ڿ���о��������ѡȡ,����ѡȡ������BNInception����Ϊ��������������������������,̽�������������ǿ���ݵķ�����
һ��cross-modality����ģ̬Ԥѵ��:ͨ�������������ʽ����ǿTSNģ�͵��б�������֮ǰ��ͨ��������ʹ��RGB��Ϊspatial stream����,optical flow��Ϊtemporal stream���롣��������������µ����뷽��:RGB diff��warped optical flow ��������Ϊ��һ��RGBȱ����������Ϣ,��ͨ��������֡�õ���RGB dif���Եõ�������Ϣ��һ���optical flow ��ʱ��۽����˶��ı�����,�����Ƕ���������,�Դ�,���������warped optical flow ��
����regularization tech:batch Normalization������Ч�ش���covariate shiftЭ����ת������,BNͨ����ÿ��batch��mean������variance,������ת���ɱ��ĸ�˹�ֲ����������Լӿ�ѵ��������,��Ҳ���ܻᵼ�¹����,��Ϊ����ѵ�����ݺ���ʵ�������ܻ���ƫ�á�����������Ԥѵ����ʼ��ģ�ͺ�,������һ���������BN���mean��variance ȫ���̶������߽���������Ϊpartial BN��
����data augmentation:����������ͨ��random crop ��horizontal flipping ��������ǿ����,�����ٴλ����������Corner cropping��scale jittering��
Corner cropping��Ϊ�˱����ڲü�ʱ���Ǽ�����ͼ�����������
Scale jittering ���ڲü�ʱ��һ����Χ�����ѡ��ü��ߴ硣
C3
����ϣ���ܹ���Ƴ�һ���ɿ���ģ��,ϣ����ģ�;���ͨ�á���ࡢ��Ч�ͼ���ʵ�ֵ����ԡ�
������Ϊ3D�����Ǿ߱������ص�����ѡ��3D�������Ի����Ƶ��Ŀ��,�����Ͷ�������Ϣ,�������ڶ�������
��ʵ�ڱ���֮ǰ,�Ѿ����������3D�������硣
�������ǰ�˵�3D����,����ص�������3��:
(1)ǰ�������3D����,��ѵ��ʱ��Ҫ����Ƶ���ֶδ���,���ڱ��ĵ�3D�������Խ���������Ƶ��֡��
(2)���ĵ�3D�����������ǰ�˵ĸ�����
(3)��������ε�3D����ʱ,����˴�ͳ��2D����,���õ���һ���������ģ�͡�

I3D
����ָ����ͼ������������,ͨ��ImageNet��ȡ��Ԥѵ��ģ�Ϳ��Ժܺõ�Ӧ�õ����������������;��ô�Ƿ������������һ�����ģ����Ƶ���ݼ�,ͨ�������ݼ�ѵ���õ���ģ����С���ݼ�(HMD51,UCF101��)��ȡ�����õ�Ч��,Ȼ�����߾���һ����Ϊkinetics�Ĵ����ݼ���
���������ܽ��˵�ǰ��������Ƶ����ʶ��ģ��:
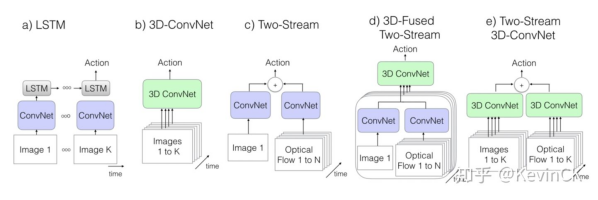
1��2D����+LSTM(�ṹa):2D����ֻ�ܴ�����֡����,������Ƶ������˵,��Ҫ��2D�����Ķ��ŵ�֡�������ں�,�ںϷ���һ����aggregation,һ����LSTM��������ΪLSTM�������Ͻ��Ǹ��õķ�����
2��3D����(�ṹb):3D�������Ƹ��ʺ�����Ƶ����,���и���Ҫ����������2D�и���IJ���,�����ͻ����ѵ��������������һ�����ģ����Ƶ���ݼ��Ckinetics,����3D�������2D��һ�����õ�ѡ��
3��Two-stream����(�ṹc):LSTM�ھ����Ķ����ȡ�߲��(����)�Ķ���(�Ͼ�ʱ�����л�����Ϣ��ʧ),�����ܻ�ȡ�ؼ��ĵͲ�ζ�����������������ʱ,���ڶ�֡��չ,ѵ������Ҳ�dz��ĺ�ʱ��Ϊ���ܹ���Ч�IJ�������Ϣ,˫������˵��һ����Ч�ķ�����
Two-stream����:ʹ������ͨ��ImageNetԤѵ���õľ���(2D)ģ��,һ����RGB���ݴ���,һ����optical flow���ݴ�����
���߸������ϸ���ģ�͵���ȱ��,�����һ������3D������˫��ģ��(Two-stream Inflated 3DConvNets)(�ṹe)
��Ϊ��3D����ģ��,û����2D�������������Ԥѵ�����������߱��������2D��������----Inceptionv1,���������е�2D��Ϊ3D��H��W ��Ӧ�IJ�����ֱ�Ӵ�Inception�л�ȡ,��D������Ҫ�Լ�ѵ����
I3D��ѵ����ʽ����ͨ��Kinetics���ݼ�����Ԥѵ��,��ѵ��HMD51��UCF101����֤Ч��,Ч��������������
�ܽ�
TSN3D����������ǵ�֡ͼƬ����,��Ҫ����Ƶ�ֶ�,C3D��������Ȼ��һ��16֡������,���ǿ���ͨ��ģ��ʵ���Զ���ȡ��RGB������Ϣ���鴦��,����������˫���� �Ļ����Ͻ��нṹ�Ľ���,C3D��˫��˼·�ںϾ������ڵ�I3D������
**Fast pathway:**��1��ʾ�˦� = 8�ͦ� = 1/8��Fast pathway�����ӡ������и��ߵ�ʱ��ֱ���(��ɫ)���͵�ͨ������(��ɫ)��
Fast·����ÿ�������ж��зǼ�ʱ��������������ڹ۲쵽��·����ʱ������������õ�ʱ��ֱ���,�Բ���ϸ���˶�������,Fastͨ�������û��ʱ���²����㡣
Lateral connections:���ǵĺ������Ӵ�fast�ںϵ�slow pathway�����ں�֮ǰ,����Ҫƥ�������Ĵ�С����ʾSlow pathway��������״Ϊ{T, S^2, C}, Fast·����������״Ϊ{��T, S^2, ��C}�������ں�������������������ת��:
(i)time-to-channel:��{��T, S^2,��C}ת��Ϊ{T, S^2, ����C},����ζ�����ǽ����еĦ�֡�����һ��֡��ͨ���С�
(ii)Time-strided-sampling:���Ǽش�ÿһ����֡��ѡȡһ��,����{��T, S^2, ��C}���{T, S^2, ��C}��
(iii)Time-strided convolution:������2��C�����ͨ���ͦ�������511�˽���3D�������������ӵ����ͨ���ۼӻ����ķ�ʽ�ںϵ�slow pathway�С�
4��ʵ��:��������
�������ĸ���Ƶʶ�����ݼ�ʹ�ñ�����Э���������ǵķ��������ڱ��ڽ��ܵĶ�������ʵ��,���ǿ����˹㷺ʹ�õ�Kinetics- 400[30],�����Kinetics- 600[3]��Charades[43]���ڵ�5�ڵĶ������ʵ����,����ʹ�þ�����ս�Ե�AVA���ݼ�[20]��
**Training:**������Kinetics�ϵ�ģ���Ǵ������ʼ��(���㿪ʼ)ѵ����,û��ʹ��ImageNet[7]���κ�Ԥ��ѵ�������ǰ���[19]�е��䷽ʹ��ͬ����SGDѵ������ϸ��Ϣ��μ���¼��
����ʱ��,���Ǵ�ȫ����Ƶ�������ȡһ��Ƭ��(��T *��֡),������·���Ϳ�·���ķֱ���T֡�ͦ�T֡;���ڿռ���,���Ǵ�һ����Ƶ������ü���224 224������,��������ˮƽ��ת,��[256,320]���������ѡȡ�϶̵ıߡ�
Inference:����ͨ��������,��������ʱ����һ�µش�һ����Ƶ��ѡȡ10��Ƭ�Ρ�����ÿ��Ƭ��,���ǽ��϶̵Ŀռ�����ŵ�256����,��ȡ3��256*256��crop���ǿռ�ά��,��Ϊȫ�������ԵĽ���,��ѭ[56]���롣���ǽ�softmax����ƽ������Ԥ�⡣
���DZ���ʵ�ʵ�����ʱ����㡣�������е������ڿռ��ʱ���ϲü����������Բ�ͬ����֮ǰ�Ĺ������,���DZ�����ÿ��ʱ����ͼ��FLOPs��(���пռ�ü���ʱ��Ƭ��)��������ʹ�õ���ͼ����������һ��,�����ǵİ�����,����ʱ��ռ��С��2562(ȡ��ѵ����2242),ÿ����3���ռ�Ƭ��(30����ͼ)ʹ����10��ʱ��Ƭ�Ρ�
Datasets:
kinetics - 400����240kѵ����Ƶ��20k��֤��Ƶ,����400�����ද�����
Kinetics-600ӵ��392k����ѵ��Ƶ��30k��֤��Ƶ,����600��������DZ���top-1��top-5����ȷ��(%)�����DZ���һ�������ġ��ڿռ��вü���Ƭ�εļ���ɱ�(��FLOPsΪ��λ)��
Charadesӵ��9.8k����ѵ��Ƶ��1.8k����֤��Ƶ,����һ�����ǩ�������õ�157�����,ƽ������30��Ļ����������ƽ������(mAP)�������ġ�
4.1 ��Ҫ���
Kinetics-400����2��ʾ��ʹ�ø����������(T*��)�Ǹɵ�SlowFastʵ���������½���ıȽ�:ResNet-50/101 (R50/101)[24]��Nonlocal (NL)[56]��
��֮ǰ���Ƚ���[56]���,���ǵ����ģ���ṩ��2.1%�Ķ������ȡ�ֵ��ע�����,�������еĽ������û�о���ImageNetԤ���������н���õöࡣ�ر���,���ǵ�ģ��(79.8%)��֮ǰ����ģ�͵���ѽ��(73.9%)���Ժ�5.9%�����Ƕ�SlowFast�����ImageNetԤѵ��������ʵ��,����������Ԥѵ���ʹ��㿪ʼ(�����ʼ��)�ı����ϱ�������(0.3%)��
���ǵĽ���Խϵ͵�����ʱ��ɱ�ʵ�֡�����ע�,�������еĹ���(�������Ļ�)��ʱ������ʹ���˷dz��ܼ�����������,����ܵ���������ʱ����100����ͼ����һ�ɱ��ںܴ�̶��ϱ������ˡ����֮��,���ǵķ�������Ҫ�ܶ�ʱ��Ƭ��,��Ϊ��ʱ��ֱ��ʻ����������Ŀ���·��������ÿ��ʱ����ͼ�ijɱ����Ժܵ�(����,36.1 GFLOPs),����Ȼ��ȷ�ġ�
����2�е�SlowFast������(���в�ͬ�����ɺ�������)���Ӧ��Slow-only·�����бȽ�,������Fast·�������ĸĽ���ˮƽ�����256^2�ռ��С�ĵ�������Ƭ�ε�ģ������,�����������ɱ���1/30�����ȡ�
Fig2����,�������еı���,Fast·���ܹ�����Խϵ͵ijɱ����������·�������ܡ���һС�ڽ���Kinetics-400���и���ϸ�ķ�����
Kinetics-600 ������Խ���,���еĽ�������ġ��������ǵ�Ŀ����Ҫ���ڱ�3���ṩ������Ժ�ο�����ע��,Kinetics-600��֤����Kinetics-400ѵ����[3]�ص�,������Dz���Kinetics-400����Ԥѵ���������µ�ActivityNet 2018[15]��ս���л�ʤ�IJ�����Ʒ[21]������79.0%����ѵ�ģ�͡���ģ̬���ȡ����ǵı�����ʾ�����õ�����,��õ�ģ��Ϊ81.8%�������kinetics700[4]��SlowFast�����[11]�С�
Charades[43]��һ�����и����Ļ��Χ�����ݼ�����4��ʾ���������������SlowFast�����Ϊ�˽��й�ƽ�ıȽ�,���ǵĻ�����ֻ��39.0 mAP�����ٰ汾��SlowFast����һ��������3.1 mAP(��42.1),�������NL���¶����0.4 mAP����Ԥ��ѵ������ѧ-600ʱ,���ǵ�mAPҲ�ﵽ��45.2���ܵ���˵,�ڱ�4��,���ǵ�SlowFastģ���Ը��͵ijɱ�,���ȶ��������ʳ�����֮ǰ���������(STRG[57])��
4.2 ����ʵ�� ablatoin experiments
�����ṩ��kinetics-400�������о�,�ȽϾ��Ⱥͼ��㸴���ԡ�
Slow vs slowfast�����ǵĵ�һ��Ŀ����ͨ���ı�Slow pathway�IJ�����(T* ��)��̽��SlowFast�Ļ����ԡ����,�������о��˿�·������·����֡�ʱȦ���ͼ2��ʾ��Slow��SlowFastģ�͵ĸ���ʵ������ȷ���븴���Ե�Ȩ�⡣���Կ���,����·��������һ����֡�������������(��ֱ��),ͬʱ����һ���ļ���ɱ�(ˮƽ��),��SlowFast�ڼ���ɱ�С�����ӵ��������������չ�����б��������,��ʹ��·�������ڸ��ߵ�֡�����ϡ���ɫ��ͷ��ʾ��Fast·�����ӵ���Ӧ��Slow-only�ܹ��ĺô�����ɫ��ͷ��ʾSlowFast�ṩ���ߵľ��Ⱥ��͵ijɱ���