参考文章
xgboost原理分析以及实践
代码
python代码
"""
@author : shl
@time : 2022-03-29 22:51
@filename : SimpleXGBoost.py
"""
import logging
import math
from typing import List
from six import StringIO
import numpy as np
import pandas as pd
import graphviz
logger = logging.getLogger("xgb logger")
logger.setLevel(logging.INFO)
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s -%(levelname)s - %(module)s: %(lineno)d - %(message)s')
ch.setFormatter(formatter)
logger.addHandler(ch)
pd.set_option("display.max_columns", 200)
pd.set_option("display.max_rows", 20)
pd.set_option("display.width", 2000)
pd.set_option("display.max_colwidth", 2000)
G_FUNC = {}
H_FUNC = {}
def register_g_func(name):
"""
用于注册g函数
"""
def res(func):
if name in G_FUNC:
raise NameError(f"{name}已经注册过, {G_FUNC}")
G_FUNC[name] = func
return res
def register_h_func(name):
"""
用于注册h函数
"""
def res(func):
if name in H_FUNC:
raise NameError(f"{name}已经注册过, {H_FUNC}")
H_FUNC[name] = func
return res
@register_g_func("quadratic")
def g_func(y_predict, y_label):
"""
定义g函数
"""
return 2 * (y_label - y_predict)
@register_h_func("quadratic")
def h_func(y_predict, y_label):
"""
定义h函数
:return:
"""
return np.ones_like(y_predict) * 2
@register_g_func("classifier")
def g_classifier_func(y_predict, y_label):
return y_predict - y_label
@register_h_func("classifier")
def h_classifier_func(y_predict, y_label):
return y_predict * (1-y_predict)
class TreeNode:
"""
树中的每一个节点
"""
def __init__(self, p_lambda=1, gamma=0, max_depth=3, shrink=0.1, depth=0):
self.split_value = None
self.split_name = None
self.gamma = gamma
self.p_lambda = p_lambda
self.left = None
self.right = None
self.left_leaf = 0
self.right_leaf = 0
self.max_depth = max_depth
self.depth = depth
self.shrink = shrink
self.gain_max = float("-inf")
def get_next_node(self, feature_value):
"""
定义一个规则:
小于当前值的,走左节点,否则走右节点
"""
if feature_value < self.split_value or feature_value is None:
return self.left
return self.right
def get_ordered_features(self, df: pd.DataFrame, feature_names):
"""
按照每个feature对样本进行排序
要求df最后一个是label
"""
ordered_feature = {}
for i, column_name in enumerate(feature_names):
logger.info(f"按照{column_name}对样本排序")
ordered_feature[column_name] = sorted(set(df[column_name].tolist()))
logger.info(f"排序结果: \n{ordered_feature}")
return ordered_feature
def predict(self, x: dict):
feature_value = x[self.split_name]
logger.debug(f"x:{x}, split name: {self.split_name}, split value: {self.split_value}")
if feature_value < self.split_value or feature_value is None:
if self.left is None:
logger.debug(f"left leaf: {self.left_leaf}")
return self.left_leaf
else:
return self.left.predict(x)
else:
if self.right is None:
logger.debug(f"right leaf: {self.right_leaf}")
return self.right_leaf
else:
return self.right.predict(x)
def fit(self, df, feature_names):
"""
这里可以并行寻找
"""
logger.info(f"fit:\n {df}")
ordered_features = self.get_ordered_features(df, feature_names)
others_max = None
for name, values in ordered_features.items():
for i, value in enumerate(values):
gain, others = self.fit_get_gain(df, name, value)
logger.info(f"尝试feature: {name}, 第{i}个数值{value}, gain: {gain}")
if gain > self.gain_max:
self.gain_max, others_max = gain, others
self.split_name, self.split_value, g_l, g_r, h_l, h_r, df_left, df_right = others_max
if self.gain_max > 0:
self.left_leaf = self.set_leaf_value(g_l, h_l)
self.right_leaf = self.set_leaf_value(g_r, h_r)
logger.info(f"最大收益: {self.gain_max}, 获取的分裂点feature为 {self.split_name}, value为 {self.split_value}, "
f"left leaf为 {self.left_leaf}, right leaf为 {self.right_leaf}")
logger.info(f"depth: {self.depth}")
if self.depth >= self.max_depth:
logger.info(f"达到最大深度,停止")
return
logger.info("生成左侧节点")
if df_left.shape[0] > 0:
self.left = TreeNode(self.p_lambda, self.gamma, self.max_depth, self.shrink,self.depth+1)
self.left.fit(df_left, feature_names)
if self.left.gain_max <= 0:
logger.info(f"去掉增益为0的节点: {self.left.gain_max}")
self.left = None
logger.info("生成右侧节点")
if df_right.shape[0] > 0:
self.right = TreeNode(self.p_lambda, self.gamma, self.max_depth, self.shrink,self.depth+1)
self.right.fit(df_right, feature_names)
if self.right.gain_max <= 0:
logger.info(f"去掉增益为0的节点: {self.right.gain_max}")
self.right = None
else:
logger.info(f"最大受益:{self.gain_max}, 停止")
return
def export_graphviz(self, node_index_name, string_io: StringIO):
"""
用于绘制树
"""
left_leaf_name = f"left_leaf_{node_index_name}"
right_leaf_name = f"right_leaf_{node_index_name}"
if self.left is None and self.right is None:
string_io.write(f"{left_leaf_name}[label={self.left_leaf}, shape=box] \n {right_leaf_name}[label={self.right_leaf}, shape=box] \n")
string_io.write(f"{node_index_name} -> {left_leaf_name}[label=yes] \n {node_index_name} -> {right_leaf_name}[label=no] \n")
elif self.left is None:
string_io.write(f"{left_leaf_name}[label={self.left_leaf}, shape=box] \n")
string_io.write(f"{node_index_name} -> {left_leaf_name}[label=yes] \n")
elif self.right is None:
string_io.write(f"{right_leaf_name}[label={self.right_leaf}, shape=box] \n")
string_io.write(f"{node_index_name} -> {right_leaf_name}[label=no] \n")
node_next_index_name = node_index_name
if self.left is not None:
node_next_index_name += 1
string_io.write(f"{node_next_index_name}[label=\"{self.left.split_name}<{self.left.split_value}\", shape=circle] \n {node_index_name} -> {node_next_index_name}[label=yes] \n")
node_next_index_name = self.left.export_graphviz(node_next_index_name, string_io)
if self.right is not None:
node_next_index_name += 1
string_io.write(f"{node_next_index_name}[label=\"{self.right.split_name}<{self.right.split_value}\", shape=circle] \n {node_index_name} -> {node_next_index_name}[label=no] \n")
node_next_index_name = self.right.export_graphviz(node_next_index_name, string_io)
return node_next_index_name
def summary(self):
if self.left is None and self.right is None:
logger.info(f"获取的分裂点feature为 {self.split_name}, value为 {self.split_value}, "
f"left leaf为 {self.left_leaf}, right leaf为 {self.right_leaf}")
elif self.left is None:
logger.info(f"获取的分裂点feature为 {self.split_name}, value为 {self.split_value}, "
f"left leaf为 {self.left_leaf}")
elif self.right is None:
logger.info(f"获取的分裂点feature为 {self.split_name}, value为 {self.split_value}, "
f"right leaf为 {self.right_leaf}")
else:
logger.info(f"获取的分裂点feature为 {self.split_name}, value为 {self.split_value}")
if self.left is not None:
self.left.summary()
if self.right is not None:
self.right.summary()
def fit_get_gain(self, df, split_name, split_value):
"""
"""
df_left = df[(df[split_name] < split_value) | (df[split_name] is None)]
g_l = df_left["g"].sum()
h_l = df_left['h'].sum()
logger.debug(f"左节点:\n{df_left}")
logger.debug(f"左节点 g_l: {g_l}, h_l: {h_l}")
df_right = df[df[split_name] >= split_value]
g_r = df_right['g'].sum()
h_r = df_right['h'].sum()
logger.debug(f"右节点:\n{df_right}")
logger.debug(f"右节点 g_r: {g_r}, h_r: {h_r}")
gain = self.get_gain(g_l, g_r, h_l, h_r)
logger.debug(f"获取的增益: {gain}")
return gain, (split_name, split_value, g_l, g_r, h_l, h_r, df_left, df_right)
def get_gain(self, gl, gr, hl, hr):
"""计算受益"""
return gl**2/(hl+self.p_lambda) + gr**2/(hr+self.p_lambda) - (gl+gr)**2/((hl+hr)+self.p_lambda) - self.gamma
def set_leaf_value(self, g, h):
"""计算叶子节点的值"""
return - self.shrink * g / (h + self.p_lambda)
class Tree:
"""
每一轮会生成一棵树
"""
def __init__(self, method="quadratic", max_depth=3, index=0, base_score=0.5, gamma=0, p_lambda=1, shrink=0.1):
self.base_score = base_score
self.method = method
self.depth = 0
self.max_depth = 3
self.index = index
self.J = {}
self.W = []
self.T = 0
self.obj = None
self.gain = 0
self.root: TreeNode = None
self.p_lambda = p_lambda
self.gamma = gamma
self.shrink = shrink
def fit(self, df):
self.root = TreeNode(self.p_lambda, self.gamma, self.max_depth, self.shrink, 1)
self.root.fit(df, ["x1", "x2"])
logger.info("tree summary:")
self.root.summary()
def predict(self, x):
return self.root.predict(x)
class SimpleXGBoostClassifier:
"""
探寻原理
采用贪心算法生成树
摒弃各种技巧及优化加速方法,采用最原始方法去生成树
"""
def __init__(self, max_depth=3, shrink=0.1, tree_max_num=2, gamma=0, p_lambda=1, method="quadratic", base_score=0.5, label_name="y"):
self.max_depth = max_depth
self.shrink = shrink
self.gamma = gamma
self.p_lambda = p_lambda
self.tree_max_num = tree_max_num
self.method = method
self.pre_stop = False
self.trees: List[Tree] = []
self.ordered_feature = {}
self.base_score = base_score
self.label_name = label_name
self.g0_name = "g_0"
self.h0_name = "h_0"
self.sample_index = "index"
self.predict_col = "predict"
self.g = "g"
self.h = "h"
def get_ordered_features(self, df: pd.DataFrame):
"""
按照每个feature对样本进行排序
要求df最后一个是label
"""
logger.info(f"columns_name: {list(df.columns)}")
for i, column_name in enumerate(df.columns[:-1]):
logger.info(f"按照{column_name}对样本排序")
self.ordered_feature[column_name] = sorted(set(df[column_name].tolist()))
logger.info(f"排序结果: \n{self.ordered_feature}")
def generate_next_tree(self, index_num, df, ordered_feature):
"""
生成一颗树
"""
tree = Tree(self.method, self.max_depth, index_num, self.base_score, self.gamma, self.p_lambda, self.shrink)
tree.fit(df)
return tree
def fit(self, df):
"""
训练SimpleXGBoost
"""
self.get_ordered_features(df)
df[self.predict_col] = self.base_score
df[self.g0_name] = df[[self.label_name, self.predict_col]].apply(lambda x: G_FUNC[self.method](x[self.predict_col], x[self.label_name]), axis=1)
df[self.h0_name] = df[[self.label_name, self.predict_col]].apply(lambda x: H_FUNC[self.method](x[self.predict_col], x[self.label_name]), axis=1)
df[self.g] = df[self.g0_name]
df[self.h] = df[self.h0_name]
logger.info(f"获取初始g和h: \n{df}")
for i in range(self.tree_max_num):
if self.pre_stop:
break
logger.info(f"开始生成第{i}棵树")
tree = self.generate_next_tree(i, df, self.ordered_feature)
self.trees.append(tree)
df[self.predict_col] = df[["x1", "x2"]].apply(lambda x: self.predict(x), axis=1)
df['y_hat'] = df.predict.map(lambda x: self.get_y_hat(x))
logger.info(f"生成第{i}课树后,进行预测:\n{df}")
logger.info("*"*50)
df[f"g_{i+1}"] = df[[self.label_name, self.predict_col]].apply(lambda x: G_FUNC[self.method](x[self.predict_col], x[self.label_name]), axis=1)
df[f"h_{i+1}"] = df[[self.label_name, self.predict_col]].apply(lambda x: H_FUNC[self.method](x[self.predict_col], x[self.label_name]), axis=1)
df[self.g] = df[f"g_{i+1}"]
df[self.h] = df[f"h_{i+1}"]
logger.info(f"准备训练下一课树的数据:\n{df}")
def get_y_hat(self, x):
if x >= 0.5:
return 1
else:
return 0
def predict(self, x):
"""
加法模型
"""
result = 0
for tree in self.trees:
result += tree.predict(x)
return self.prob(result)
def prob(self, x):
"""
计算概率
"""
return 1 / (1 + math.pow(math.e, - x))
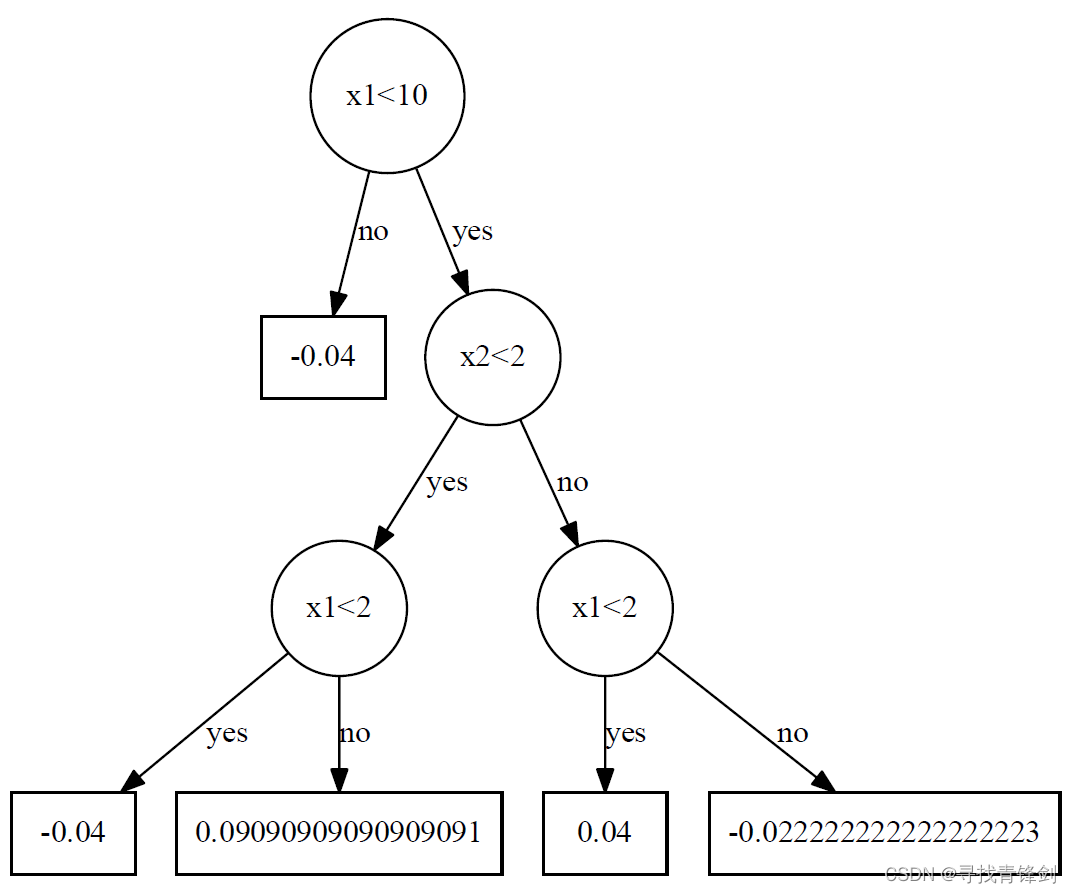
def export_graphviz(self):
"""
在data路径下生成树结构
"""
for i, tree in enumerate(self.trees):
string_io = StringIO()
string_io.write(f"digraph tree_{i} "+"{\n")
string_io.write(f"{0}[label=\"{tree.root.split_name}<{tree.root.split_value}\",shape=circle] \n")
tree.root.export_graphviz(0, string_io)
string_io.write("\n}")
dot_data = string_io.getvalue()
graph = graphviz.Source(dot_data)
graph.render(f'data/tree_{i}', cleanup=True)
def get_data():
"""
获取数据
"""
df = pd.DataFrame({'x1': [1, 2, 3, 1, 2, 6, 7, 6, 7, 6, 8, 9, 10, 8, 9],
'x2': [-5, 5, -2, 2, 0, -5, 5, -2, 2, 0, -5, 5, -2, 2, 0],
'y': [0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1]})
logger.info(f"数据集:\n{df}")
return df
def main():
df = get_data()
simple_xgb = SimpleXGBoostClassifier(method="classifier", tree_max_num=5, max_depth=3, base_score=0.5)
simple_xgb.fit(df)
simple_xgb.export_graphviz()
if __name__ == '__main__':
main()
部分结果
2022-04-02 22:12:30,184 -INFO - SimpleXGBoost: 374 - 开始生成第0棵树
2022-04-02 22:12:30,184 -INFO - SimpleXGBoost: 144 - fit:
x1 x2 y predict g_0 h_0 g h
0 1 -5 0 0.5 0.5 0.25 0.5 0.25
1 2 5 0 0.5 0.5 0.25 0.5 0.25
2 3 -2 1 0.5 -0.5 0.25 -0.5 0.25
3 1 2 1 0.5 -0.5 0.25 -0.5 0.25
4 2 0 1 0.5 -0.5 0.25 -0.5 0.25
5 6 -5 1 0.5 -0.5 0.25 -0.5 0.25
6 7 5 1 0.5 -0.5 0.25 -0.5 0.25
7 6 -2 0 0.5 0.5 0.25 0.5 0.25
8 7 2 0 0.5 0.5 0.25 0.5 0.25
9 6 0 1 0.5 -0.5 0.25 -0.5 0.25
10 8 -5 1 0.5 -0.5 0.25 -0.5 0.25
11 9 5 1 0.5 -0.5 0.25 -0.5 0.25
12 10 -2 0 0.5 0.5 0.25 0.5 0.25
13 8 2 0 0.5 0.5 0.25 0.5 0.25
14 9 0 1 0.5 -0.5 0.25 -0.5 0.25
2022-04-02 22:12:30,184 -INFO - SimpleXGBoost: 119 - 按照x1对样本排序
2022-04-02 22:12:30,184 -INFO - SimpleXGBoost: 119 - 按照x2对样本排序
2022-04-02 22:12:30,184 -INFO - SimpleXGBoost: 121 - 排序结果:
{'x1': [1, 2, 3, 6, 7, 8, 9, 10], 'x2': [-5, -2, 0, 2, 5]}
2022-04-02 22:12:30,184 -INFO - SimpleXGBoost: 151 - 尝试feature: x1, 第0个数值1, gain: 0.0
2022-04-02 22:12:30,200 -INFO - SimpleXGBoost: 151 - 尝试feature: x1, 第1个数值2, gain: 0.055727554179566596
2022-04-02 22:12:30,200 -INFO - SimpleXGBoost: 151 - 尝试feature: x1, 第2个数值3, gain: 0.12631578947368421
2022-04-02 22:12:30,200 -INFO - SimpleXGBoost: 151 - 尝试feature: x1, 第3个数值6, gain: -0.07685881370091896
2022-04-02 22:12:30,215 -INFO - SimpleXGBoost: 151 - 尝试feature: x1, 第4个数值7, gain: -0.049441786283891564
2022-04-02 22:12:30,215 -INFO - SimpleXGBoost: 151 - 尝试feature: x1, 第5个数值8, gain: -0.07685881370091896
2022-04-02 22:12:30,215 -INFO - SimpleXGBoost: 151 - 尝试feature: x1, 第6个数值9, gain: -0.08082706766917291
2022-04-02 22:12:30,231 -INFO - SimpleXGBoost: 151 - 尝试feature: x1, 第7个数值10, gain: 0.6152046783625731
2022-04-02 22:12:30,231 -INFO - SimpleXGBoost: 151 - 尝试feature: x2, 第0个数值-5, gain: 0.0
2022-04-02 22:12:30,231 -INFO - SimpleXGBoost: 151 - 尝试feature: x2, 第1个数值-2, gain: -0.08082706766917291
2022-04-02 22:12:30,246 -INFO - SimpleXGBoost: 151 - 尝试feature: x2, 第2个数值0, gain: 0.21862348178137653
2022-04-02 22:12:30,246 -INFO - SimpleXGBoost: 151 - 尝试feature: x2, 第3个数值2, gain: 0.21862348178137653
2022-04-02 22:12:30,262 -INFO - SimpleXGBoost: 151 - 尝试feature: x2, 第4个数值5, gain: -0.08082706766917291
2022-04-02 22:12:30,262 -INFO - SimpleXGBoost: 161 - 最大收益: 0.6152046783625731, 获取的分裂点feature为 x1, value为 10, left leaf为 0.044444444444444446, right leaf为 -0.04
部分树结构
|