创建函数
def语句
- 标题行由 def 关键字、函数的名字,以及参数的集合(如果有的话)组成
- def 子句的剩余部分包括了一个虽然可选但是强烈推荐的文档字串,和必需的函数体
前向引用
- 函数不允许在函数未声明之前,对其进行引用或者调用
def foo(): # 定义函数foo(),先调用bar()函数,报错,下面定义以后,报错取消
print('in foo')
bar()
def bar(): # 定义函数bar()
print('in bar')
foo() # 函数foo()已经被定义,可以直接调用注意
- 定义函数时,函数的先后顺序不重要,重要的是?函数在什么位置被调用
调用函数
- 使用一对圆括号() 调用函数,如果没有圆括号,只是对函数的引用
- 任何输入的参数都是必须放置在括号中
>>> def foo(): # 定义函数foo()
... print('in foo')
...
>>> foo # 调用函数时,函数名后必须有小括号,否则返回一个位置对象
>>> foo() # 函数得正确调用方式关键字参数
- 关键字参数的概念仅仅针对函数的调用
- 这种理念是?让调用者通过函数调用中的参数名字来区分参数
- 这种规范允许参数不按顺序
- 位置参数应写在关键字参数前面
>>> def get_age(name, age): #关键字参数的使用,定义函数get_age(name,age), 形参:name和age
... print('%s is %s years old' % (name, age))
...
>>> get_age('tom', 20) #调用函数get_age(name,age),name为‘tom’,age为20
>>> get_age(20, 'tom') #会按照顺序将实参传递给对应得形参,name=20,age='tom'
>>> get_age(age=20, name='tom') #使用关键字进行传参
>>> get_age(age=20, 'tom') #关键字参数【age=20】要写在位置参数【'tom'】的后面
>>> get_age(20, name='tom') #传递实参时,位置参数name在第一个位置,在这里获取了两个name的值
>>> get_age('tom', age=20) #传递实参时,name值为'tom',age值为20,正确练习 1:简单的加减法数学游戏
需求
- 随机生成两个100以内的数字
- 随机选择加法或是减法
- 总是使用大的数字减去小的数字
# 练习 1:简单的加减法数学游戏
# 需求 程序 = 数据结构(存储, []) + 算法(方案)
# 随机生成两个100以内的数字 (1~100) random.randint(1,100)
# 随机选择加法或是减法 random.choice("-+")
# 总是使用大的数字减去小的数字
import random
def exam():
# nums = []
# for i in range(2):
# nums.append(random.randint(1, 100))
nums=[random.randint(1,100) for i in range(2)]#产生两个1~100的随机整数
nums.sort(reverse=True) # 降序排列,保证大数在前小数在后
caozuo = random.choice("+-") # 随机选择+或者-
if caozuo == "+": # answer: 正确答案
answer = nums[0] + nums[1]
else: # caozuo == "-"
answer = nums[0] - nums[1]
# dc: 用户计算的结果
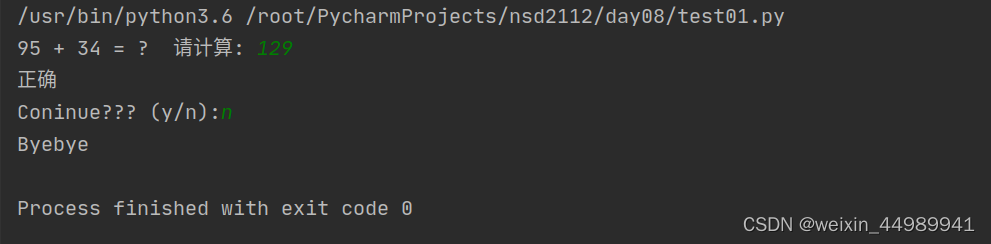
for i in range(3): #循环三次
dc = input("%s %s %s = ? 请计算: " % (nums[0], caozuo, nums[1]))
if int(dc) == answer:
print("正确")
break # 答案正确,直接退出循环
else:
print("错误")
else: #用户三次都算错,非break退出,给出正确答案
print("正确答案是:",answer)
def show_menu():
while True:
exam() # 算数
dc = input("Coninue??? (y/n):")
if dc == "n":
print("Byebye")
break # 退出循环,游戏结束
if __name__ == '__main__':
show_menu()
匿名函数
- python 允许用 lambda 关键字创造匿名函数
- 匿名是因为不需要以标准的 def 方式来声明
- 一个完整的 lambda "语句"代表了一个表达式,这个表达式定义体必须和声明放在同一行
# 使用def定义函数add(x,y)
def add(x, y):
return x + y
if __name__ == '__main__':
print(add(10, 5))
myadd = lambda x, y: x + y # 定义匿名函数,赋值给myadd,x和y作为形参
print(myadd(10, 20))filter() 函数
- filter(func, seq): 调用一个布尔函数 func 来迭代遍历每个序列中的元素;返回一个使 func 返回值为 true 的元素的序列
- 如果布尔函数比较简单,直接使用 lambda 匿名函数就显得非常方便了
filter(func, seq)函数的使用,如果seq序列中的元素,传入函数func后,返回值为True,则保留下来
# 函数式编程: 将函数当成参数,传到另一个函数中
# filter(筛选条件函数, 候选元素列表)
# 对候选者链列表中的元素一个一个的进行筛选条件判断,满足要求的留下
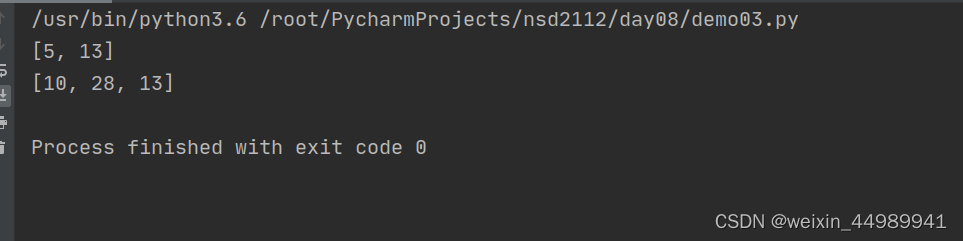
list01 = [10, 5, -6, 28, 13, -10]
dc = filter(lambda x:True if x % 2 == 1 else False, list01)
print(list(dc)) # 留下奇数
dc1 = filter(lambda x: True if x > 5 else False, list01)
print(list(dc1)) # 留下大于5的数
# 传统做法: 定义一个函数,将函数名作为承参数传递
# def yq1(x): # 留下大于5的数
# return True if x > 5 else False
# dc1 = filter(yq1, list01)
map() 函数
- map(func, seq): 调用一个函数func 来迭代遍历每个序列中的元素;返回一个经过func处理过的元素序列
map(func, seq)函数的使用,将seq序列中的元素,传入函数func后,经过处理后全部保留下来
# 函数式编程: 将函数当成参数,传到另一个函数中
# map (加工函数,待加工元素列表)
list02 = [1,2,3,4,5]
dc3 = map(lambda x:x *2 +1, list02)
print("dc3:",list(dc3))
dc4 = map(lambda x: x ** 2 -5,list02)
print("dc4:",list(dc4))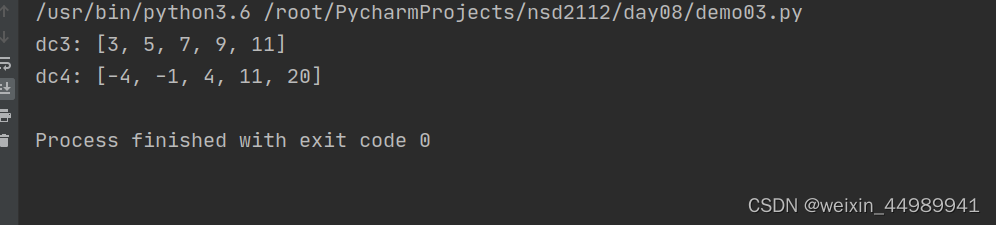
变量作用域
全局变量
- 标识符的作用域是定义为其声明在程序里的可应用范围,也就是变量的可见性
- 在一个模块中最高级别的变量有全局作用域
- 全局变量的一个特征是除非被删除掉,否则他们会存活到脚本运行结束,且对于所有的函数,他们的值都是可以被访问的
全局变量的使用
>>> x = 10 # 定义全局变量x
>>> def func1(): # 定义函数func1(),函数内部可以直接使用变量x
... print(x)
...
>>> func1() #调用函数func1(),结果为10局部变量
- 局部变量只是暂时的存在,仅仅只依赖于定义他们的函数现阶段是否处于活动
- 当一个函数调用出现时,其局部变量就进入声明它们的作用域。在那一刻,一个新的局部变量名为那个对象创建了
- 一旦函数完成,框架被释放,变量将会离开作用域
局部变量只在函数内部起作用
>>> def func2(): #定义函数func2(), 其中的变量a为局部变量,只在函数内部有效
... a = 10
... print(a)
...
>>> def func3(): #定义函数func2(), 其中的变量a为局部变量,只在函数内部有效
... a = 'hello'
... print(a)
...
>>> func2() #调用函数func2(),结果为10
>>> func3() #调用函数func3(), 结果为hello
>>> a #查看a的值,没有被定义,函数内部的a为局部变量,只在该函数内部有效如果局部变量与全局变量有相同的名称,那么函数运行时,局部变量的名称将会把全局变量的名称遮盖住
global 语句
- 因为全局变量的名字能被局部变量给遮盖掉
- 为了明确地引用一个已命名的全局变量,必须使用 global 语句
>>> x = 100 #定义全局变量x
>>> def func6(): #定义函数func6()
... global x #引用全局变量x
... x = 200 #为全局变量x赋值为200
... print(x) #打印变量x的值
...
>>> func6() #调用函数func6()
>>> x# 变量的作用域
# 全局变量: 函数外部定义的变量, 作用于函数内外
# 局部变量: 函数内部定义的变量, 作用于函数内
# 内建模块(builtins.py): python解释器启动自动导入的模块
# 想在函数内部修改全局变量 global: 声明在函数内部使用的是全局变量
d = 100
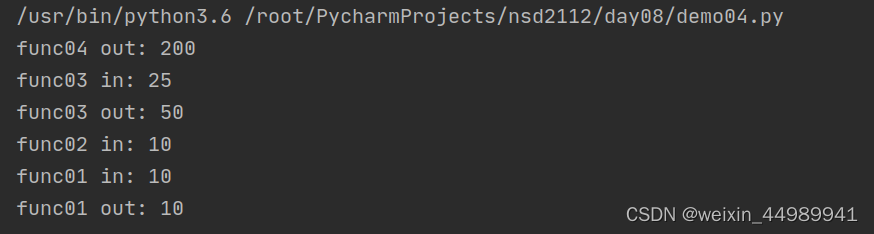
def func04():
global d # 声明在函数内部使用的是 全局变量d
d = 200 # 将全局比偶按量的值从100改到200
func04()
print("func04 out:", d) # 200
# 1.首先在函数的内部去查找
# 2.函数内部没有,然后去全局去查找,看是否定义
# 3.全局也没有,最后会去内建模块中查找
c = 50 # 全局变量
def func03():
c = 25 # 局部变量
print("func03 in:", c) # 就近原则 25
func03() # c = ?
print("func03 out:", c) # c = 50
def func02():
b = 10 # 局部变量
print("func02 in:", b)
func02()
# print("func02 out:", b)
a = 10 # 全局变量
def func01():
print("func01 in:", a) # 10
func01()
print("func01 out:", a) # 10
查找变量或函数的顺序
- 首先在函数的内部去查找
- 函数内部没有,然后去全局去查找,看是否定义
- 全局也没有,最后会去内建函数中查找
# 验证python查找变量或函数的顺序,定义函数func7(),统计字符'abcd'的长度
>>> def func7():
... print(len('abcd'))
...
>>> func7() #调用函数,结果为4,正确
>>> len #全局查看是否有len,没有,不存在
# 先在函数func7()内部查找方法len(),再在全局查找,最后在内建中查找len()
生成器
Python 使用生成器对延迟操作提供了支持。所谓延迟操作,是指在需要的时候才产生结果,而不是立即产生结果。这也是生成器的主要好处。
Python有两种不同的方式提供生成器:
-
生成器函数:
- 常规函数定义,但是,使用 yield 语句而不是 return 语句返回结果
- yield 语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
# 生成器 generator
# 生成器的元素只能获取一遍 惰性加载 节省空间(相比于列表)
gene = (i for i in range(1, 6)) # 1 2 3 4 5
print(gene) # <generator object <genexpr> at 0x7fe38a8ccaf0>
# 生成器数据的获取方式
# 1. 生成器和for连用
for dc in gene:
print(dc)
# 2. 生成器.__next__()
# print(gene.__next__()) # 1
# print(gene.__next__()) # 2
# print(gene.__next__()) # 3
# print(gene.__next__()) # 4
# print(gene.__next__()) # 5
# print(gene.__next__()) # 报错
# list01 = [i for i in range(1, 6)]
# print(list01) # [1, 2, 3, 4, 5], 一次性将列表中的数据全部怼到内存
# >>> sum( [i for i in range(100000000)] )
# 已杀死
# >>> sum( (i for i in range(200000000)) )
# 19999999900000000 ?
?
?
# 生成器 generator
# 2. 生成器函数
# return: 表示函数执行的终止
# yield: 表示函数执行的暂停
# 一个函数内部有了yield关键字,就变成了生成器
def func01():
a = 10
yield a
b = "hello"
yield b
c = [1, 2]
yield c
jg = func01()
print(jg) # <generator object func01 at 0x7f41463efaf0>
print(jg.__next__()) # 10
print(jg.__next__()) # "hello"
print(jg.__next__()) # [1, 2]
# print(jg.__next__()) # 报错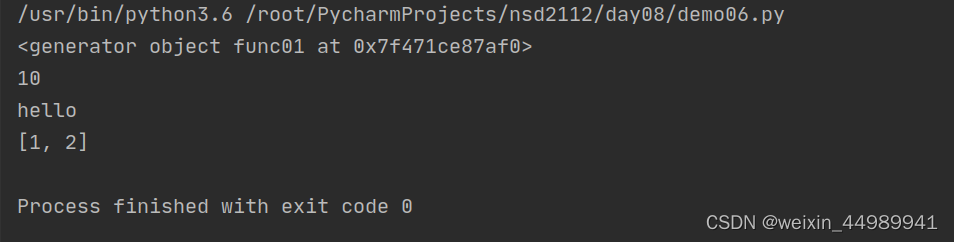
?
生成器表达式:
- 类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
>>> from random import randint
>>> nums = [randint(1, 100) for i in range(10)] #产生10个1~99的随机数
>>> nums
>>> nums2 = (randint(1, 100) for i in range(10)) #() 会产生一个随机数的生成器对象
>>> nums2 #为一个对象,不占用空间,使用时才会产生数据
>>> for i in nums2: #使用for循环遍历nums2中的元素,成功
... print(i)
...
>>> ['192.168.1.%s' %i for i in range(1, 255)] #使用列表解析产生一个254个元素的大列表,占据比较大的内存空间
>>> ips = ('192.168.1.%s' %i for i in range(1, 255)) #() 会产生一个IP地址的生成器对象【包含254个IP地址】
>>> ips #为一个对象,不占用空间,使用时才会产生数据
>>> for ip in ips: #使用for循环可以遍历出ips中的所有元素,成功
... print(ip)- Python不但使用迭代器协议,让for循环变得更加通用。大部分内置函数,也是使用迭代器协议访问对象的。例如, sum函数是Python的内置函数,该函数使用迭代器协议访问对象,而生成器实现了迭代器协议,所以,我们可以直接这样计算一系列值的和:
>>> sum((x ** 2 for x in range(4))
# 而不用多此一举的先构造一个列表:
>>> sum([x ** 2 for x in range(4)]) - 生成器的好处在于延迟操作,需要的时候再使用,所以会节省空间
sum([i for i in range(100000000)])
sum((i for i in range(100000000)))-
注意事项
-
生成器的唯一注意事项就是:生成器只能遍历一次
-
我们直接来看例子,假设文件中保存了每个省份的人口总数,现在,需要求每个省份的人口占全国总人口的比例。显然,我们需要先求出全国的总人口,然后在遍历每个省份的人口,用每个省的人口数除以总人口数,就得到了每个省份的人口占全国人口的比例。
-
自定义生成器函数的过程
- 在函数内部,有很多?yield?返回中间结果;
- 程序向函数取值时,当函数执行到第1个yield时,会暂停函数运行并返回中间结果;
- 当主程序再次调用函数时,函数会从上次暂停的位置继续运行,当遇到第2个yield,会再次暂停运行函数并返回数据;
- 重复以上操作,一直到函数内部的yield全部执行完成为止
-