数据类型
浮点数在使用的时候,存在不确定尾数。因为二进制跟十进制的转化不完全,所以会存在尾巴
所以使用round(x,d) d代表要取多少位。在混合运算时,生成结果为最宽类型
| 类型 | 示例 |
|---|---|
| 十进制 | 0 1 2 |
| 十六进制 | 0X12 0x12 |
| 八进制 | 0O12 0o12 |
| 二进制 | 0b12 0B1 |
| 运算符 | 意义 |
|---|---|
| / | 结果是浮点数 10/3=3.333 |
| // | 整数的除法运算 10//3=3 |
| -y | y的负数 |
| x**y | x的y次方幂,如果y为小数就是开 |
| +- * / % | 加减乘取余 |
ads() # 求绝对值
divmod(x,y) #同时输出商和余
divmod(10,3)=(3,1)
pow(x,y[,z]) # x的y次幂 同时除z,可以使运算结果在范围内 [..]代表参数可以省略
round(x[,d]) #忽略小数 d代表要取多少位 默认为0
max(x,...n) # 求n个数的最大值
min(x,...n) # 求n个数的最小值,
int(x) # 将浮点数或字符串转为 整数
float(x) #将整数或者字符串转换为 浮点数
complex(x) #将数据转为复数
字符串
由一对单引号或一对双引号或一对三引号包裹的文本。三引号也可以用作多行的注释。如果文本含有单引号,就用双引号包裹。含有双引号,就用单引号。或者在内含的引号前面+/.
字符串分为正索引和反向索引。字符串可以索引和切片
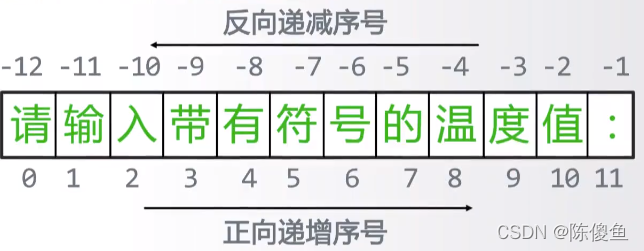
<字符串>[M] TempSrt[-1] # 索引
<字符串>[M:N] TempSrt[1:3] TempStr[0:-1] # 切片 从1开始 但不到3 0- -1相当于把最后一个字符去掉
<字符串>[M:N:k] # M 缺少表从头 N少表到结尾 K代表步长。
“123456”[:3] = "123"
[::-1] 代表对字符串逆序
字符串的格式化

# 填充对齐和宽度 字符串超过对齐长度,则以字符串长度显示。
>>>"{0:=^14}".format("python") = "====PYTHON===="
>>>"{0:*>14}".format("BIT") = "**********BIT"
>>>"{:10}".format("BIT") = "BIT "
# , 精度和类型 ,财务上以千为单位分割; .表示精度
>>> "{0:.2f}".format(12345.6789) = '12,345.68 '
c,整数:将数字转换成其 unicode 对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持 0-255);字符:将字符添加到指定位置
o,将整数转换成八进制表示,并将其格式化到指定位置
x,将整数转换成十六进制表示,并将其格式化到指定位置
d,将整数、浮点数转换成十进制表示,并将其格式化到指定位置
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写 e )
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写 E )
f,将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
F,同上
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是 e;)
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是 E;)
%,当字符串中存在格式化标志时,需要用 %% 表示一个百分号
字符串运算符
x+y
x*y #复制x字符串n次
x in s # 如果x是s的子串。返回ture 否会false
字符串函数
len(x) #得到字符串长度
str(x) # 将任意类型变为字符串类型
str(12.3) = "12.3"
str([1,2]) = "[1,2]"
hex(x)或oct(x) #得到整数的16进制或8进制的小写形式的字符串
hex(425)= "ox1a9"
oct(425)="0o651"
chr(u) 返回unicode对应的字符
ord(x) 返回字符对应的unicode值
字符串方法
str.lower或str.upper() # 将字符串的大小写进行转换
str.split(sep=None) # 返回一个列表 由str根据sep被分割的部分组成 默认采用空格进行分割
”A,B,C“.split(",")结果为['A','B','C']
str.count(sub) # 返回字串在str中出现的次数
str.replace(old,new) # 所有old字串被替换为new
str.center(width[,fillchar]) # 字符串str根据宽度width居中,fillchar可选
"python".center(14,"=") 结果为”====python====“
str.strip(chars) # 从str中去掉在其左侧和右侧chars中列出的字符
str.join(iter) # 在iter变量除最后元素外每个元素增加一个str
",".join = "1,2,3,4,5"
字符串的格式化
// An highlighted block
var foo = 'bar';
组合数据类型
集合类型

>>>A ={'python',123,('python',123)} # 使用{}建立集合
{123,'python',('python',123)}
>>>B = set('pypy123') # 建立空集合 只能使用set
{'1','p','2','3','y'}
>>> C = {'python',123,'python',123}
>{'python',123}
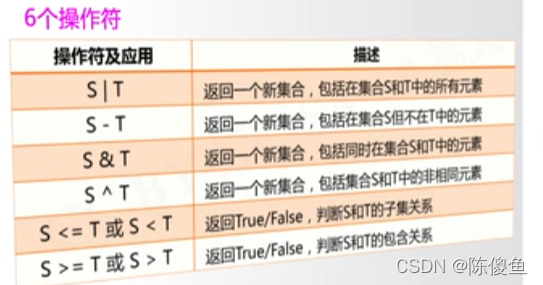
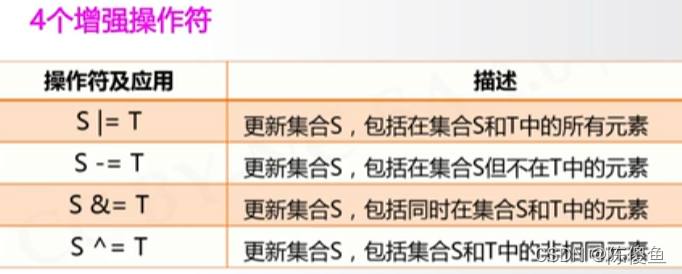
集合操作符


A ={'p',123,'y'}
for item in A:
print(item,end="") # y123p
A={'P','Y',123}
try:
while True:
print(A.pop(),end="")
except:
pass
应用场景
可以判断包含关系和数据去重
ls = ('p','p','y','y',123)
s = set(ls)
{'p','y',123}
lt= list(s)
序列类型
序列是一个基类类型:字符串类型,元组类型,列表类型。
序列包含正向递增序号和反向递增序号。
元组用()和tuple创建,列表用[]和list创建
元组用在元素不改变的场景,用于固定搭配场景。例:函数返回值
可以对数据进行保护
| 序列通用操作符及应用 | 描述 |
|---|---|
| x in s | 如果x是序列s的元素,返回True,否则返回False |
| x not in s | 如果x是序列s的元素,返回False,否则返回True |
| s+t | 连接两个序列s和t |
| s* n 或 n* s | 将序列s复制n次 |
| s[i] | 索引,返回s中的第i个元素,i是序列的序号 |
| s[i:j]或s[i:j:k] | 切片,返回序列s中第i到j以k为步长的元素子序列 |
| 序列通用函数和方法 | 描述 |
|---|---|
| len(s) | 返回序列s的长度 |
| min(s) | 返回s最小值,s元素需要可以比较 |
| max(s) | 返回s最大值,s中元素可比较 |
| s.index(x) or s.index(x,i,j) | 返回元素在列表中的位置 |
| s.count(x) | 返回序列s中出现x的总次数 |
元组类型
一旦创建就不能被修改。
使用()或tuple()创建,元素之间用逗号,分隔
可以使用或者不使用小括号
继承了序列的全部操作。
creature = 'cat','dog','tiger','human'
>>>creature[::-1]
('human','tiger','dog','cat') # 这是一个新的元组
>>>color = (0x001100,'blue',creature)
>>>color[-1][2]
'tiger'
列表类型
是一种序列类型,创建后可以随意修改
使用方括号[]或list()创建,元素间用逗号,分隔
可以使用或不适用方括号
>>> ls =['cat','dog','tiger',1024]
>>> ls
['cat','dog','tiger',1024]
>>> lt=ls # 方括号[]真正创建一个列表,赋值仅传递引用
>>>> lt
['cat','dog','tiger',1024]
| 函数和方法 | 描述 |
|---|---|
| ls[i] = x | 替换列表ls第i元素为x |
| ls[i:j:k] = lt | 用列表lt替换ls切片后所对应的元素子列表 |
| del ls[i] | 删除列表ls中第i元素 |
| del ls[i:j:k] | 删除列表ls中第i到j以k为步长的元素 |
| ls += lt | 更新列表ls,将列表lt元素增加到列表ls中 |
| ls*=n | 更新列表ls,其元素重复n次 |
| ls.append(x) | 在列表ls最后增加一个元素x |
| ls.clear | 删除列表ls中所有元素 |
| ls.copy() | 生成一个新列表,赋值ls中所有元素 |
| ls.insert(i,x) | 在列表ls的第i位置增加元素x |
| ls.pop(i) | 将列表ls中第i位置元素取出,并删除该元素 |
| ls.remove(x) | 将列表ls中出现的第一个元素x删除 |
| ls.reverse() | 将列表ls中的元素反转 |
字典
字典类型是映射的体现。作用就是表达键值对,进而操作它们
键值对:键是数据索引的扩展
字典是键值对的集合,键值对之间无序。
采用{}和dict()创建,键值对之间用冒号 :表示
[] 用来向字典变量中索引或增加元素
通过{}来创建空的字典。集合类型也是用{}的,但是因为字典常用,所以把{}的留给了字典
| 函数或方法 | 解释 |
|---|---|
| del d[k] | 删除字典d中键k对应的数据值 |
| k in d | 判断键k是否在字典d中,如果在返回True,否则False |
| d.keys() | 返回字典d中所有的键信息 可以for in做遍历,但是不能当作列表类型来操作 |
| d.values() | 返回字典d中所有的值信息 可以for in做遍历,但是不能当作列表类型来操作 |
| d.items() | 返回字典d中所有的键值对信息 |
| d.get(k,< default >) | 键K存在,则返回相应值,不存在则返回< default >值 这个函数很重要 |
| d.pop(k,< default >) | 键K存在,则取出相应值,取出之后就是删除原来的,不存在则返回< default >值 |
| d.popitem() | 随机从字典d中取出一个键值对,以元组形式返回 |
| d.clear() | 删除所有的键值对 |
| len(d) | 返回字典d中元素的个数 |
type(x) #返回变量x的类型