猿人学Web端爬虫攻防大赛第十题 与某数ast+jsdom方法
参考文章:
1.猿人学爬虫攻防赛 第10题
2.某数和某5秒-反混淆动态注入调试的一种方案
样品网址:https://match.yuanrenxue.com/match/10
打开首页后直接就有5处混淆,第一处是某数套 jsjiami.com.v6,然后后面4处为obfuscator

首先还原这一段jsjiamiv6的混淆,还原后的结果如下
let yuanrenxue_36 = '';
var yuanrenxue_59 = 968;
for (let yuanrenxue_229 = 0; yuanrenxue_229 < $_ts["dfe1683"]["length"]; yuanrenxue_229++) {
yuanrenxue_36 += String["fromCharCode"]($_ts["dfe1683"][yuanrenxue_229]["charCodeAt"]() - yuanrenxue_229 % yuanrenxue_59 - 50);
}
yuanrenxue_18 = atob(yuanrenxue_36);
yuanrenxue_31(78, yuanrenxue_18);
可以大概看出其中的逻辑主要是对$_ts[“dfe1683”]进行解密,接着还原rs的混淆
*******省略很多代码*******
case 29:
yuanrenxue_48.yuanrenxue_110 = new Date().getTime();
var yuanrenxue_35 = yuanrenxue_48["dfe1675"];
yuanrenxue_48["dfe1675"] = yuanrenxue_40;
var yuanrenxue_91 = yuanrenxue_48.yuanrenxue_yuanrenxue_126;
var yuanrenxue_13 = yuanrenxue_31(8);
var yuanrenxue_21 = yuanrenxue_31(8);
var yuanrenxue_15 = yuanrenxue_48.aebi = [];
var yuanrenxue_88 = yuanrenxue_31(71);
var yuanrenxue_65 = yuanrenxue_35.length;
var yuanrenxue_1 = 0;
var yuanrenxue_89 = yuanrenxue_12();
var yuanrenxue_54 = yuanrenxue_12();
var yuanrenxue_67 = yuanrenxue_12();
var yuanrenxue_72 = yuanrenxue_12();
var yuanrenxue_105 = yuanrenxue_12();
yuanrenxue_14 = yuanrenxue_12();
var yuanrenxue_28 = yuanrenxue_12();
if (yuanrenxue_14 > 0) {
yuanrenxue_96 = yuanrenxue_35.substr(yuanrenxue_1, yuanrenxue_28).split(String.fromCharCode(255));
}
yuanrenxue_1 += yuanrenxue_28;
var yuanrenxue_56 = [];
var yuanrenxue_14 = yuanrenxue_12();
for (yuanrenxue_24 = 0; yuanrenxue_24 < yuanrenxue_14; yuanrenxue_24++) {
yuanrenxue_23(16, yuanrenxue_24, yuanrenxue_56);
}
for (yuanrenxue_24 = 0; yuanrenxue_24 < yuanrenxue_14; yuanrenxue_24++) {
yuanrenxue_56.push("}");
}
yuanrenxue_56.push(")();");
var yuanrenxue_18 = yuanrenxue_56.join('');
yuanrenxue_48.yuanrenxue_110 -= yuanrenxue_31(8);
yuanrenxue_21 = yuanrenxue_31(8);
let yuanrenxue_36 = '';
var yuanrenxue_59 = 479;
for (let yuanrenxue_229 = 0x0; yuanrenxue_229 < $_ts["dfe1683"]["length"]; yuanrenxue_229++) {
yuanrenxue_36 += String["fromCharCode"]($_ts["dfe1683"][yuanrenxue_229]["charCodeAt"]() - yuanrenxue_229 % yuanrenxue_59 - 0x32);
}
yuanrenxue_18 = atob(yuanrenxue_36);
yuanrenxue_31(0x4e, yuanrenxue_18);
var yuanrenxue_32 = yuanrenxue_31(8);
if (yuanrenxue_32 - yuanrenxue_13 > 12000) {
yuanrenxue_48.yuanrenxue_74 = 1;
}
return;
*******省略很多代码*******
整个代码比较多,只贴上部分代码,可以看到[“dfe1675”]解密后的代码赋值给了yuanrenxue_18 ,接着[“dfe1683”]解密后的代码也是直接赋值给了yuanrenxue_18 ,相当于覆盖了,所以前面的一部分代码就不需要看了,根本没有执行。
接着后面还有4个ob混淆,但是里面的代码并不重要,只是反调试有点烦人,那么接着看yuanrenxue_18的代码,连续拿到两次yuanrenxue_18的代码,查看变化,发现有三处
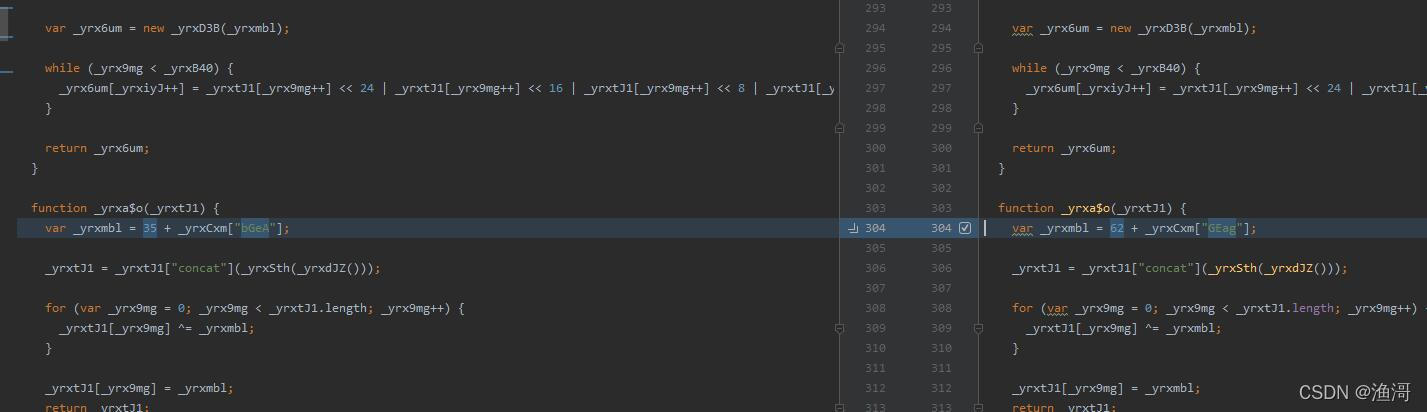


这里都与后面的一个接口 https://match.yuanrenxue.com/api/offset 的返回值息息相关,说明这个值也是非常重要的。到这里还是没有找到加密参数生成的入口,但是请求发出的事情,参数就自动生成了,那么很有可能xhr下的open,send等方法被改写了

这就可以知道,参数是通过_yrxyA$函数生成的,使用ast在这个函数的结尾动态注入一个【console.log(_yrx2LR);】
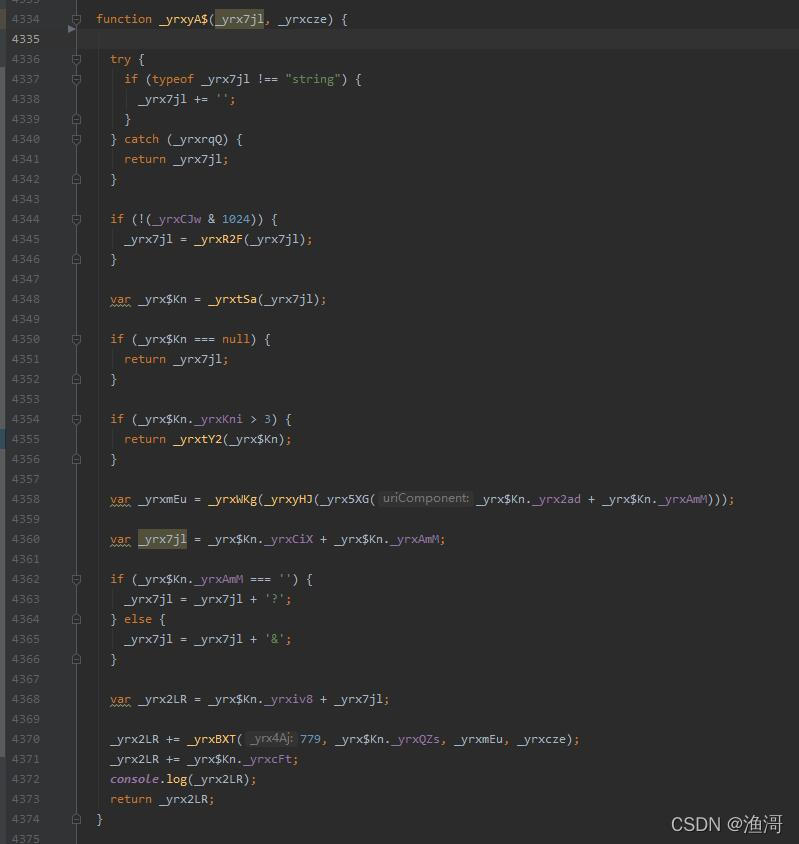
这样当我们调用open方法的时候,就可以获取包含加密参数的最终链接,最后使用jsdom把代码跑起来,需要先安装依赖库
npm install jsdom
import requests_html
import json
import re
import base64
import subprocess
import os
import logging
logging.disable(logging.INFO)
def main():
requests = requests_html.HTMLSession()
headers = {
'User-Agent': 'yuanrenxue.project',
'Referer': 'https://match.yuanrenxue.com/match/10',
'X-Requested-With': 'XMLHttpRequest'
}
base_url = 'https://match.yuanrenxue.com'
top_url = base_url + '/match/10'
response = requests.get(top_url, headers=headers)
script = response.html.find('script')
ts_1_url = base_url + script[0].attrs['src']
ts_2_url = base_url + script[1].attrs['src']
ts_3_url = base_url + '/api/offset'
with open('config.json', 'w', encoding='utf-8') as f:
f.write(json.dumps({
'html': response.content.decode(),
'url': 'https://match.yuanrenxue.com/match/10'
}))
with open('html.html', 'wb') as f:
f.write(response.content)
yuanrenxue_59 = int(re.findall('(?<=var yuanrenxue_59=)\d+', response.content.decode())[0])
response = requests.get(ts_2_url, headers=headers)
dfe1683 = response.content.decode()[17:-1]
yuanrenxue_36 = ''
for yuanrenxue_229 in range(len(dfe1683)):
yuanrenxue_36 += chr(ord(dfe1683[yuanrenxue_229]) - yuanrenxue_229 % yuanrenxue_59 - 50)
with open('eval.js', 'wb') as f:
f.write(base64.b64decode(yuanrenxue_36.encode()))
os.system('node ast_eval')
os.system('node ast_html')
with open('ts.js', 'wb') as f:
response = requests.get(ts_1_url, headers=headers)
f.write(response.content)
with open('offset.js', 'wb') as f:
response = requests.get(ts_3_url, headers=headers)
f.write(response.content)
with open('rs_decrypt.js', 'r', encoding='utf-8') as f:
js = f.read()
print('开始获取链接')
for page in range(1, 6):
with open('get_url.js', 'w', encoding='utf-8') as f:
f.write("const{JSDOM}=require('jsdom');const fs = require('fs');const dom=new JSDOM(fs.readFileSync('html.html').toString('utf-8'),{url:'https://match.yuanrenxue.com/match/10'});window=dom.window;document=window.document;\n")
f.write('if(typeof __dirname!="undefined"){__dirname=undefined}if(typeof __filename!="undefined"){__filename=undefined}if(typeof require!="undefined"){require=undefined}if(typeof exports!="undefined"){exports=undefined}if(typeof module!="undefined"){module=undefined}\n')
f.write("window.eval.call(window, fs.readFileSync('ts.js').toString('utf-8') + fs.readFileSync('offset.js').toString('utf-8'));\n")
f.write("window.$_ts = $_ts;\n")
f.write(js)
f.write('\n\nlet xml = new window.XMLHttpRequest();\n')
f.write("""xml.open('GET', "/api/match/10?page=""" + str(page) + """\", false);\n""")
f.write("process.exit(0);")
command = ['node', 'get_url.js']
nodejs = subprocess.Popen(command, stderr=subprocess.PIPE, stdout=subprocess.PIPE)
url = nodejs.stdout.read().decode().replace('\n', '')
print(url)
response = requests.get(url, headers=headers).json()
print(response)
with open('offset.js', 'rb') as f:
offset = f.read()
with open('offset.js', 'wb') as f:
f.write(offset[:14] + response['k']['k'].split('|')[1].encode())
if __name__ == '__main__':
main()
这里因为每次请求接口都会返回一个新的offset,所以这里每次请求后都需要重新加载

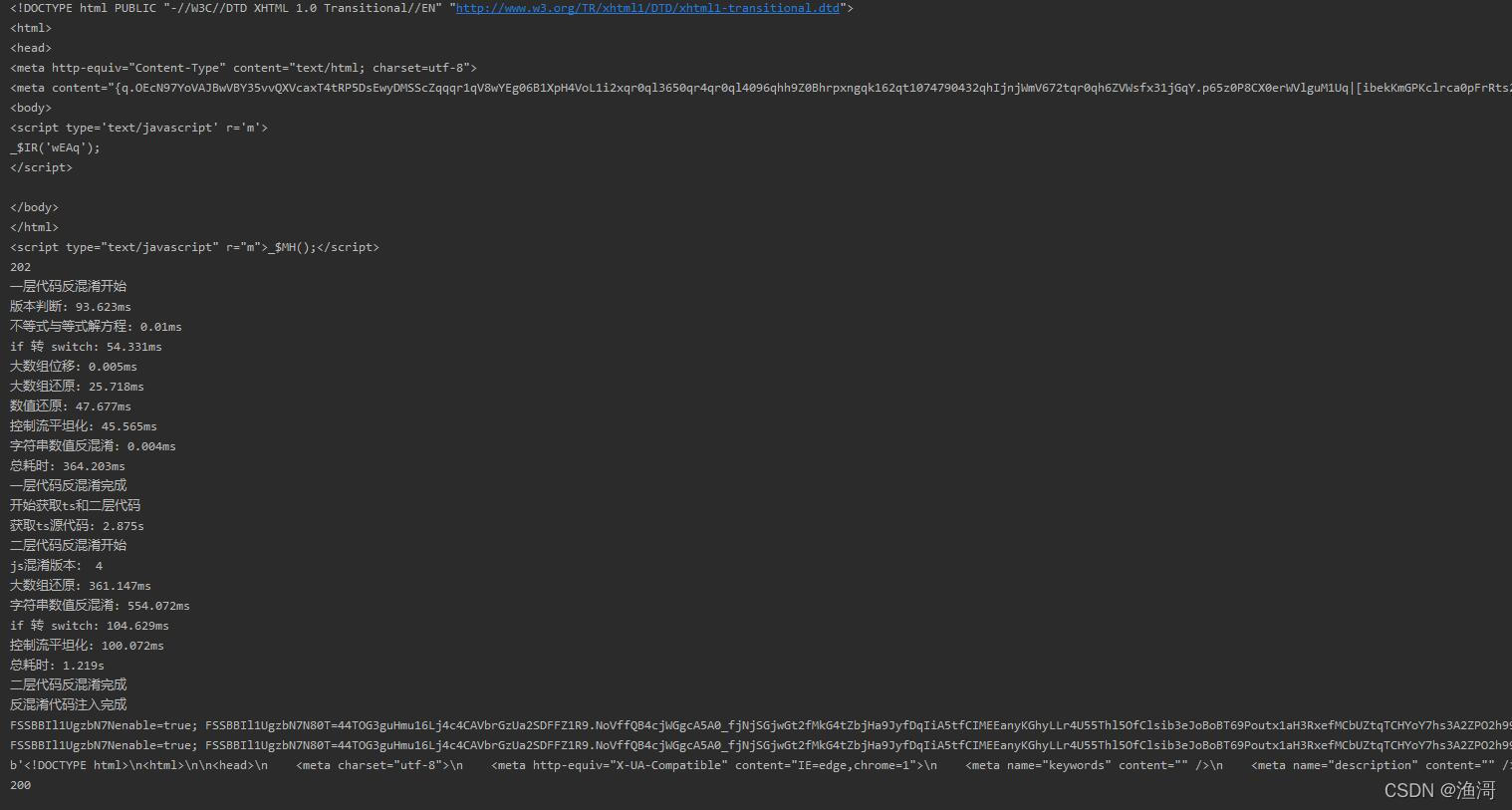
非常好,可以成功请求5页的数据了。当然,这个方法运用在真实某数下也是可以的,例子如下
RS4代混淆
*******省略很多代码*******
case 78:
if (_$JX === undefined || _$JX === "") {
return;
}
if (_$8k.execScript) {
ret = _$8k.execScript(_$JX);
return ret;
}
_$YA = _$8k.eval;
ret = _$YA.call(_$8k, _$JX);
return ret;
*******省略很多代码*******
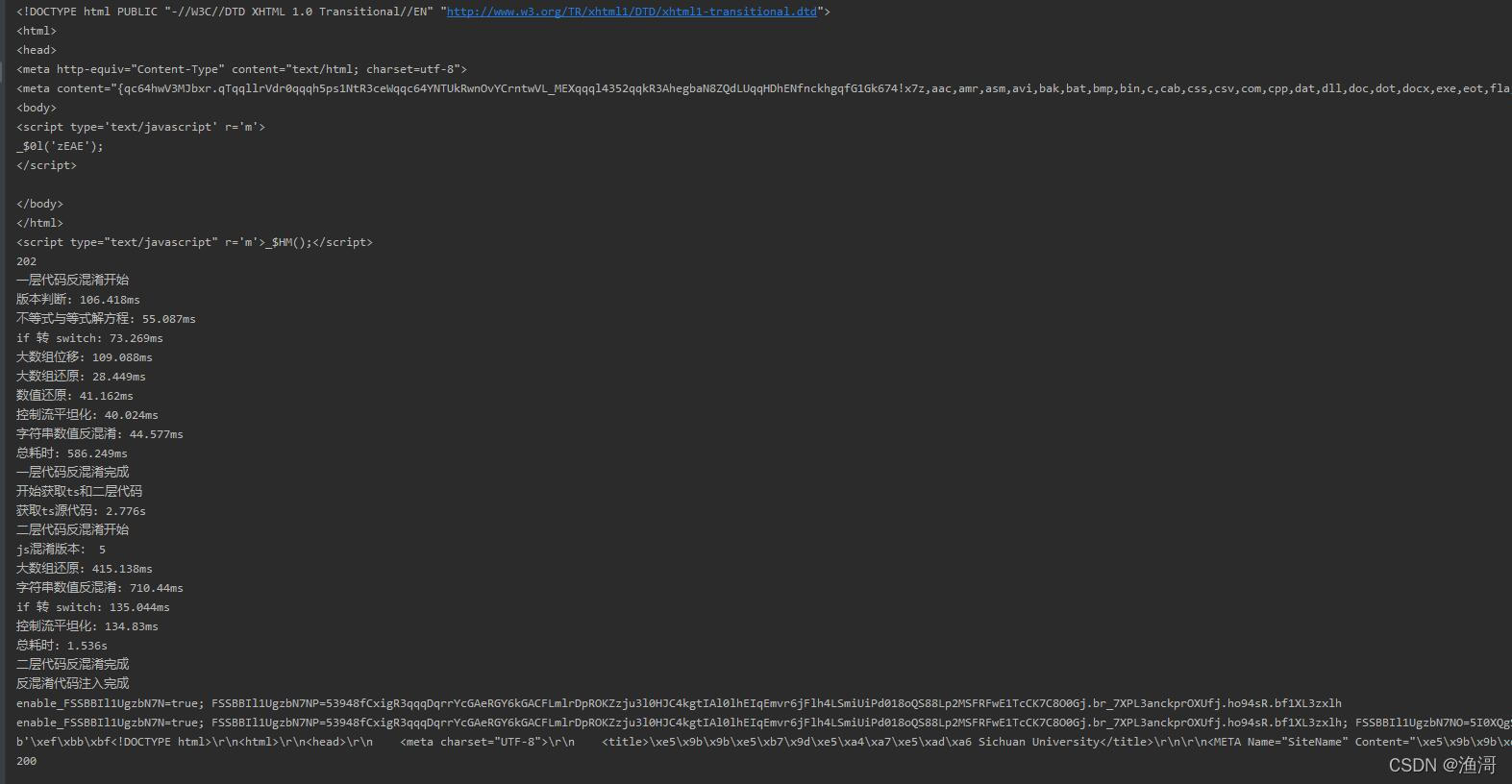
RS5代混淆
*******省略很多代码*******
case 73:
if (_$r1 === undefined || _$r1 === "") {
return;
}
var _$_P;
if (_$Z8["execScript"]) {
_$_P = _$Z8["execScript"](_$r1);
return _$_P;
}
_$RD = _$Z8["eval"];
_$_P = _$RD["call"](_$Z8, _$r1);
return _$_P;
*******省略很多代码*******
RS6代混淆
*******省略很多代码*******
case 101:
_$_r = undefined;
if (_$hi === _$_r || _$hi === "") {
return;
}
_$_r = _$fx;
if (_$_r.execScript) {
_$_n = _$_r.execScript(_$hi);
return _$_n;
}
_$_d = _$_r.eval;
_$_n = _$_d.call(_$_r, _$hi);
return _$_n;
case 41:
_$_n = _$$X(38);
_$_d = _$_z;
_$cq = _$_d.nsd;
_$$7 = _$by;
_$_d.lcd = _$$7;
_$_d.nsd = _$$7;
_$cy = _$$X(114, _$cq);
_$bb = _$$X(0, 711, _$$X(114, _$cq));
_$$d = [];
_$_d.cp = _$$d;
_$$d[1] = _$bb;
_$aJ = _$_d.aebi = [];
_$_d.scj = [{
"0": 0,
"1": 1,
"2": 2,
"3": 3
}, {
"0": 0,
"1": 0,
"2": 0,
"3": 0,
"4": 0
}, {
"0": 0,
"1": -545,
"2": -538,
"3": 174
}, {
"0": 0,
"1": 3,
"2": 3,
"3": 0,
"4": 0,
"5": -241,
"6": -241
}];
_$d8 = "省略代码";
_$g$ = _$d8.length;
_$_t = 0;
_$$d[0] = "省略代码";
_$$d[2] = "省略代码";
_$$d[6] = "";
_$$r = _$_R();
_$$n = _$_R();
_$$b = _$_R();
_$er = _$_R();
_$dp = _$_R();
_$a5 = _$_R();
_$iH = _$_R() * 55295 + _$_R();
_$_d = _$bF;
if (_$a5 > 0) {
_$gj = _$d8.substr(_$_t, _$iH).split(_$_d.fromCharCode(257));
}
_$_t += _$iH;
_$a5 = _$_R();
_$aN = 0;
for (; _$aN < _$a5;) {
_$gj.push(_$$1(51, _$_R() * 55295 + _$_R()));
_$aN++;
}
_$eP = [];
_$_X = '\n\n\n\n\n';
_$a5 = _$_R();
_$aN = 0;
for (; _$aN < _$a5;) {
_$eP.push(_$_X.substr(0, _$cy() % 5));
_$$1(69, _$aN, _$eP);
_$aN++;
}
_$eP.push('}}}}}}}}}}'.substr(_$a5 - 1));
_$$1(54, _$eP);
_$eP.push("})($_ts.scj,$_ts.aebi);");
_$d5 = _$eP.join('');
_$$d[4] = _$$X(38) - _$_n;
_$_f = 0;
for (_$aN = 0; _$aN < _$d5.length; _$aN += 100) {
_$_f += _$d5.charCodeAt(_$aN);
}
_$$d[3] = _$_f;
_$_L = _$$X(38);
_$$X(101, _$d5);
_$$d[5] = _$$X(38) - _$_n;
return;
}
*******省略很多代码*******
更多内容欢迎加入我的星球


