scikit-learn中的PCA
使用sklearn中的PCA步骤
初始化pca
官方给出的形参列表

- n_components:>=1时表示想要求得的主成分个数,传入小于1的float类型,表示保留下的主成分的特征保留度
初始化保留前两个主成分
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
保留下95%的特征
pca = PCA(0.95)
进行训练集的拟合
使用PCA.fit()函数进行数据的拟合
pca.fit(X_train)
均值归零化
使用PCA.transform()对数据进行均值归零
X_train_reduction = pca.transform(X_train)
至此,我们就完成了最基础的PCA降维过程,接下来,我们运用到MNIST手写数据集中进行预测
对MNIST手写数据集进行降维并预测
不降维直接预测
首先,我们先加载MNIST手写数据集
import numpy as np
from sklearn.datasets import fetch_openml
mnist = fetch_openml("mnist_784")
由于mnist数据集已经为训练和测试集分好类了,我们直接取前60000个当训练集,其余当测试集就可以了
X_train = np.array(X[:60000], dtype = float)
y_train = np.array(y[:60000], dtype = float)
X_test = np.array(X[60000:], dtype = float)
y_test = np.array(y[60000:], dtype = float)
这里,我们使用kNN方法对数据进行预测
我们先用kNN对所有数据集进行训练和预测
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
%time knn_clf.fit(X_train, y_train)
%time knn_clf.score(X_test, y_test)
运行结果:
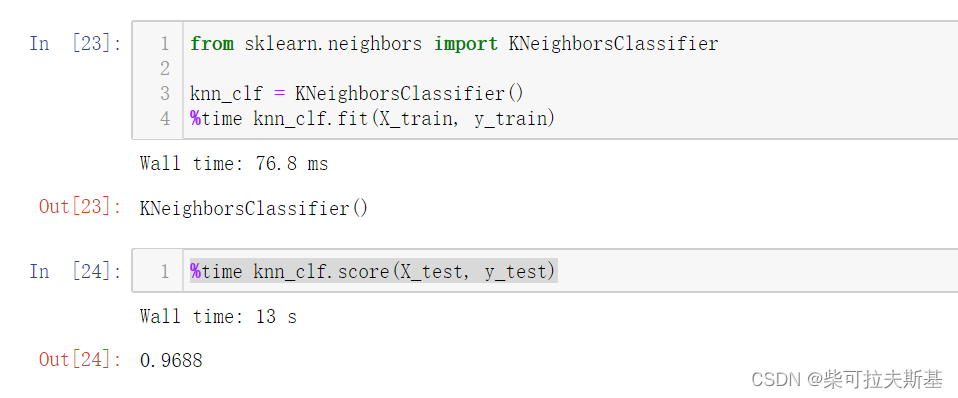
这里最近kNN算法应该是有改进过的,速度优化了很多
接下来,我们通过降维,再通过kNN进行预测
降维后预测
这里,我们选取90%的特征精度,进行降维的过程和上述介绍的过程是一样的
from sklearn.decomposition import PCA
pca = PCA(0.9)
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
我们可以查看一下降维后的X_train的shape

减少了700个特征,可以极大优化我们的计算复杂度
我们再对降维后的数据进行训练和预测:
knn_clf = KNeighborsClassifier()
%time knn_clf.fit(X_train_reduction, y_train)
X_test_reduction = pca.transform(X_test)
%time knn_clf.score(X_test_reduction, y_test)
运行结果:
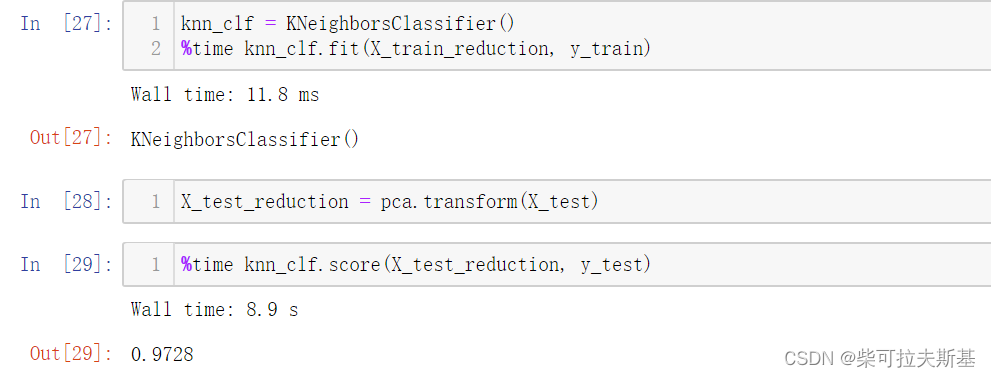
时间确实是有明显的提升的,同时,预测精度还提高了。因为,降维的过程中,我们还可以减少数据的噪声。

