import traceback
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common import exceptions
import time
import xlsxwriter
import os
class ShangHaiRanking:
__SHANGHAIRANKING_ROOT = './shranking'
indicator_list = []
more_indicator_cnt = 0
def __init__(self):
self._driver = webdriver.Chrome()
def __initIndicatorList(self):
self.indicator_list.clear()
butt = self._driver.find_element_by_xpath('//*[@id="content-box"]/div[2]/table/thead/tr/th[6]/div/div[1]/div[1]/input')
self._driver.execute_script('arguments[0].click();', butt)
menu = self._driver.find_element_by_xpath('//*[@id="content-box"]/div[2]/table/thead/tr/th[6]/div/div[1]/div[2]/ul')\
.find_elements_by_css_selector('li')
for m in menu:
self.indicator_list.append(m.text)
self.more_indicator_cnt = len(menu)
#init workbook
def __initWorkBook(self, year):
if not os.path.exists(self.__SHANGHAIRANKING_ROOT):
os.mkdir(self.__SHANGHAIRANKING_ROOT)
if os.path.exists(self.__SHANGHAIRANKING_ROOT):
print('[info]: 文件创建成功')
else:
print('[error]: 文件创建失败')
exit(1)
self.workBook = xlsxwriter.Workbook(f'{self.__SHANGHAIRANKING_ROOT}/shranking_{year}.xlsx')
print('[info]: workbook initialized...')
def __closeWorkBook(self):
self.workBook.close()
print('[info]: workbook closed...')
#init sheet
def __initSheet(self):
if self.workBook == 0 or not isinstance(self.workBook, xlsxwriter.Workbook):
print("[error]: init workbook first")
self.close()
exit(1)
self.sheet = self.workBook.add_worksheet()
#initial the table head
self.sheet.write(0, 0, '排名')
self.sheet.write(0, 1, '学校名称')
self.sheet.write(0, 2, '英文名称')
self.sheet.write(0, 3, '标签')
self.sheet.write(0, 4, '省市')
self.sheet.write(0, 5, '类型')
self.sheet.write(0, 6, '总分')
for i in range(len(self.indicator_list)):
self.sheet.write(0, 7 + i, self.indicator_list[i])
print('[info]: sheet initialized...')
def recording(self, year):
offset = 1
url = f'https://www.shanghairanking.cn/rankings/bcur/{year}11'
self._driver.get(url)
time.sleep(2)
self.__initIndicatorList()
self.__initWorkBook(year)
self.__initSheet()
while True:
table = self._driver.find_element_by_xpath('//*[@id="content-box"]/div[2]/table/tbody')
trs = table.find_elements_by_tag_name('tr')
curline = offset
for tr in trs:
tds = tr.find_elements_by_tag_name('td')
self.sheet.write(curline, 0, tds[0].text)
self.sheet.write(curline, 1, tds[1].find_element_by_class_name('name-cn').text)
self.sheet.write(curline, 2, tds[1].find_element_by_class_name('name-en').text)
try:
tags = tds[1].find_element_by_class_name('tags')
self.sheet.write(curline, 3, tags.text)
except exceptions.NoSuchElementException:
self.sheet.write(curline, 3, '')
self.sheet.write(curline, 4, tds[2].text)
self.sheet.write(curline, 5, tds[3].text)
self.sheet.write(curline, 6, tds[4].text)
curline = curline + 1
for index in range(self.more_indicator_cnt):
curline = offset
butt = self._driver.find_element_by_xpath('//*[@id="content-box"]/div[2]/table/thead/tr/th[6]/div/div[1]/div[1]/input')
self._driver.execute_script('arguments[0].click();', butt)
menu = self._driver.find_element_by_xpath('//*[@id="content-box"]/div[2]/table/thead/tr/th[6]/div/div[1]/div[2]/ul')\
.find_elements_by_css_selector('li')
self._driver.execute_script('arguments[0].click();', menu[index])
time.sleep(0.5)
for tr in trs:
self.sheet.write(curline, 7 + index, tr.find_elements_by_tag_name('td')[-1].text)
curline = curline + 1
offset = curline
try:
self._driver.find_element_by_class_name('ant-pagination-disabled.ant-pagination-next')
print('[processing]: {} finished...'.format(offset - 1))
print(f'[info]: shanghairanking of {year} is finished...')
self.__closeWorkBook()
return
except exceptions.NoSuchElementException:
nextButt = self._driver.find_element_by_class_name('ant-pagination-next')
self._driver.execute_script('arguments[0].click();', nextButt)
print('[processing]: {} finished...'.format(offset - 1))
time.sleep(0.5)
except BaseException as e:
self.__closeWorkBook()
raise(e)
def close(self):
self._driver.close()
if __name__ == '__main__':
shr = ShangHaiRanking()
try:
#爬取2015年-2022年所有数据
for i in range(2015, 2023):
shr.recording(i)
except BaseException as e:
print('[error]: crashed, details are blow')
print(traceback.format_exc(), end='')
finally:
shr.close()
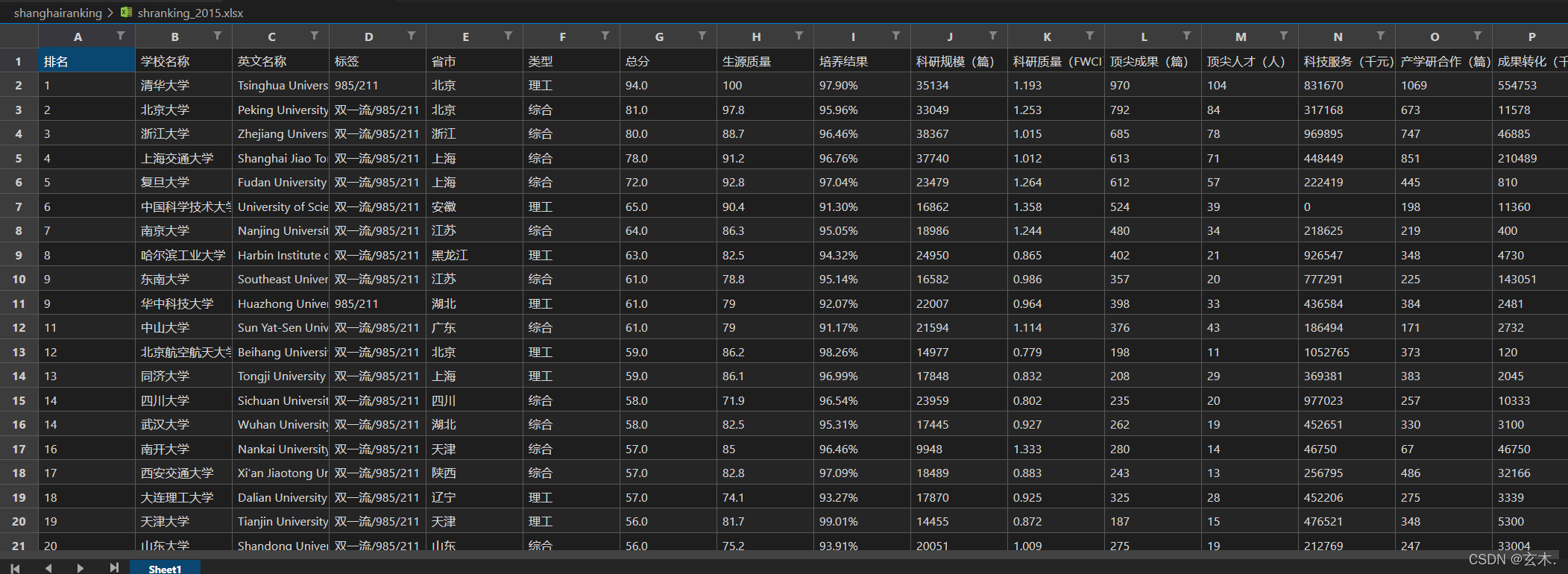
结果如下: