文章目录
Abstract
This week’s learning content is to re-read the principle of GAN’s original paper and pytorch code implementation, to implement generative adversarial network GAN based on MINST, and to have a further understanding of the algorithm process of GAN’s original paper; the second is to solve the problem of database synchronization in the liuyuan project. The three-party synchronization software, installed and activated, has been tested several times, and the synchronization operation according to the conditions has been executed, and it is running well now. The third is the review of the Autoformer model and some code understanding, thinking about the difference and connection between autoformer and informer for long sequence prediction.
本周一是重新对GAN原始论文原理导读与pytorch代码实现,基于MINST 实现生成对抗网络GAN,对GAN原始论文的算法流程有进一步理解;二是关于力源项目数据库同步问题的解决,利用第三方同步软件,安装与激活,并进行了几次测试,执行了按条件定时同步操作,目前运行良好。三是Autoformer模型的回顾与部分代码理解,思考autoformer 与informer 对长序列预测的区别与联系。
一. GAN原始论文原理导读与pytorch代码实现
GAN原始论文:原始论文下载地址
1.1 GAN的简单介绍
首先我们用一句话来概括下原始GAN。原始GAN由两个有机中整体构成――生成器 G G G 和判别器 D D D ,生成器的目的就是将随机输入的高斯噪声映射成图像(“假图”),判别器则是判断输入图像是否来自生成器的概率,即判断输入图像是否为假图的概率。
GAN的训练也与CNN大不相同,CNN是定义好特定的损失函数,然后利用梯度下降及其改进算法进行优化参数,尽可能用局部最优解去逼近全局最优解。但是GAN的训练是个动态的过程,是生成器 G G G 与判别器 D D D 两者之间的相互博弈过程。通俗点讲,GAN的目的就是无中生有,以假乱真。即要使得生成器 G G G 生成的所谓的"假图"骗过判别器 D D D ,那么最优状态就是生成器 G G G 生成的所谓的"假图"在判别器 D D D的判别结果为0.5,不知道到底是真图还是假图。
总的来说:就是通过一个对抗过程来去构造一个生成模型,在对抗过程中需要同时训练两个模型―― G : G: G: 生成模型是对数据分布进行一个建模, D : D: D:判别器模型是用来去判别生成的样本是否来自真实或者预测样本。
1.2 生成对抗网络GAN的定义
本论文原始的使用DNN(多层感知机/全连接层)去做生成器G与判别器D(其实可以用Transformer等),其实最原始的GAN的训练过程可以被视为求解值函数(value function)极大极小值的问题。
原文中提到训练GAN其实就是找到生成器和判别器的最优参数,使得下面的值函数具有极小极大值。下面公式中的这个函数,就是纵横GAN领域的对抗损失函数(Adversarial Loss)。
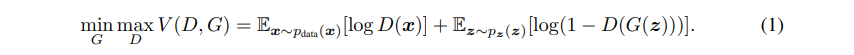
这里的极大值和极小值的意思为:
(1) 找一个最优的判别器D,使其能够更好地判别真实的数据和由生成器生成的数据之间的分布差异;
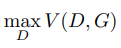
(2) 找到一个最优的生成器,使其生成的数据的特征分布与真实数据的特征分布更接近(分布可以由KL散度来表示),也就是生成的数据与真实数据在高维的空间距离较近,差异较小,让判别器难以区分。综合上面的求解极大值,总体流程可以被理解为求解值函数的极小极大值。
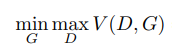

1.3 GAN的算法流程

首先利用定义的目标函数结合梯度上升训练K次判别器,之后结合梯度下降去训练1次生成器。
先训练K步判别器:
从一个先验分布 p g ( z ) p_g(z) pg?(z)(正态分布)中采样m个噪声样本数据,再从训练样本中取m个样本;
下面就是更新判别器的梯度上升算法迭代,连续更新K步:
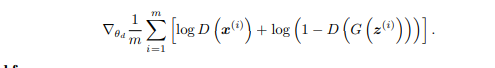
再是更新生成器部分:
同样的从噪声样本(先验分布)中取(之前取过了)
m
m
m个样本,构成一个minbatch ,然后基于梯度下降算法去更新生成器,目标函数或者叫最小化函数是:
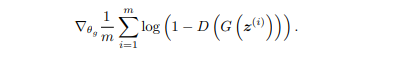
GAN的一个step 过程就是如上所示,上述过程其实较为抽象,后续会根据具体任务来做一个介绍!
GAN相关结论数学证明 ,CSDN上已经有大神给出相关详细推导过程,详细内容参考博客:GAN论文阅读――原始GAN(基本概念及理论推导)
1.4 基于MINST 实现生成对抗网络GAN
原始论文的GAN的生成器模块与判别器模块:采用的是DNN内部结构
分别是G与D的模型:
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 128),
torch.nn.BatchNorm1d(128),
torch.nn.GELU(),
nn.Linear(128, 256),
torch.nn.BatchNorm1d(256),
torch.nn.GELU(),
nn.Linear(256, 512),
torch.nn.BatchNorm1d(512),
torch.nn.GELU(),
nn.Linear(512, 1024),
torch.nn.BatchNorm1d(1024),
torch.nn.GELU(),
nn.Linear(1024, np.prod(image_size, dtype=np.int32)),
# nn.Tanh(),
nn.Sigmoid(),
)
def forward(self, z):
# shape of z: [batchsize, latent_dim]
output = self.model(z)
image = output.reshape(z.shape[0], *image_size)
return image
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(np.prod(image_size, dtype=np.int32), 512),
torch.nn.GELU(),
nn.Linear(512, 256),
torch.nn.GELU(),
nn.Linear(256, 128),
torch.nn.GELU(),
nn.Linear(128, 64),
torch.nn.GELU(),
nn.Linear(64, 32),
torch.nn.GELU(),
nn.Linear(32, 1),
nn.Sigmoid(),
)
def forward(self, image):
# shape of image: [batchsize, 1, 28, 28]
prob = self.model(image.reshape(image.shape[0], -1))
return prob
(1)引入batchnorm可以提高收敛速度,具体做法是在生成器的Linear层后面添加BatchNorm1d,最后一层除外,判别器不要加。
(2)将激活函数ReLU换成GELU效果更好。
下面给出具体的实现GAN的MINST的代码实例与结果展示:
基于pytorch的一个MINST数据集,并直接在线下载,利用Dataset与dataloader加载数据集。并且分别实例化生成器与判别器,分别构建两个adam优化器,与两个g_loss与d_loss的目标优化函数。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Last Modified By : none <none>
""" 基于MNIST 实现对抗生成网络 (GAN) """
import torch
import torchvision
import torch.nn as nn
import numpy as np
image_size = [1, 28, 28]
latent_dim = 96
batch_size = 64
use_gpu = torch.cuda.is_available()
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 128),
torch.nn.BatchNorm1d(128),
torch.nn.ReLU(),
nn.Linear(128, 256),
torch.nn.BatchNorm1d(256),
torch.nn.ReLU(),
nn.Linear(256, 512),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
nn.Linear(512, 1024),
torch.nn.BatchNorm1d(1024),
torch.nn.ReLU(),
nn.Linear(1024, np.prod(image_size, dtype=np.int32)),
# nn.Tanh(),
nn.Sigmoid(),
)
def forward(self, z):
# shape of z: [batchsize, latent_dim]
output = self.model(z)
image = output.reshape(z.shape[0], *image_size)
return image
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(np.prod(image_size, dtype=np.int32), 512),
torch.nn.ReLU(),
nn.Linear(512, 256),
torch.nn.GELU(),
nn.Linear(256, 128),
torch.nn.ReLU(),
nn.Linear(128, 64),
torch.nn.ReLU(),
nn.Linear(64, 32),
torch.nn.ReLU(),
nn.Linear(32, 1),
nn.Sigmoid(),
)
def forward(self, image):
# shape of image: [batchsize, 1, 28, 28]
prob = self.model(image.reshape(image.shape[0], -1))
return prob
# Training
dataset = torchvision.datasets.MNIST("mnist_data", train=True, download=True,
transform=torchvision.transforms.Compose(
[
torchvision.transforms.Resize(28),
torchvision.transforms.ToTensor(),
# 归一化的操作
# torchvision.transforms.Normalize([0.5], [0.5]),
]
)
)
# 构建dataloader,加载数据 dataset
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True)
# 分别实例化生成器与判别器
generator = Generator()
discriminator = Discriminator()
# 分别构建两个adam优化器(GAN模型都是如此套路!)
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0003, betas=(0.4, 0.8), weight_decay=0.0001)
# BCELoss()损失函数,二项的交叉熵函数,定义部分
loss_fn = nn.BCELoss()
# target
labels_one = torch.ones(batch_size, 1)
labels_zero = torch.zeros(batch_size, 1)
if use_gpu:
print("use gpu for training")
generator = generator.cuda()
discriminator = discriminator.cuda()
loss_fn = loss_fn.cuda()
labels_one = labels_one.to("cuda")
labels_zero = labels_zero.to("cuda")
# 开始训练阶段,就是两个for循环!
num_epoch = 200
for epoch in range(num_epoch):
# 训练步骤开始,对dataloader进行 枚举遍历
for i, mini_batch in enumerate(dataloader):
gt_images, _ = mini_batch # mini_batch包含 x和y,label不要,只要真实 gt_images
# z是一个符合正态分布的随机,latent_dim是Z的维度(z就是高斯变量)
z = torch.randn(batch_size, latent_dim)
if use_gpu:
gt_images = gt_images.to("cuda")
z = z.to("cuda")
# 把Z喂入生成器中,得出预测的images照片
pred_images = generator(z)
#对所有梯度置零
g_optimizer.zero_grad()
recons_loss = torch.abs(pred_images-gt_images).mean()
# 对生成器进行优化
# discriminator(pred_images)是判别器对预测图片给出的概率大小,labels_one则是target,对生成器G进行优化,target取1;
g_loss = recons_loss*0.05 + loss_fn(discriminator(pred_images), labels_one)
g_loss.backward()
# 更新G的参数
g_optimizer.step()
# 对判别器梯度置零
d_optimizer.zero_grad()
#判别器的目标函数有两项
real_loss = loss_fn(discriminator(gt_images), labels_one) # 对真实图片预测成 1
fake_loss = loss_fn(discriminator(pred_images.detach()), labels_zero) # 希望判别器对预测生成的图片(假图)分类成0
# 不需要记录G的梯度,所以用pred_images.detach(),将G梯度从中隔离出来,不需要计算生成器的梯度
d_loss = (real_loss + fake_loss)
# 观察real_loss与fake_loss,同时下降同时达到最小值,并且差不多大,说明D已经稳定了
#同理
d_loss.backward()
d_optimizer.step()
if i % 50 == 0:
print(f"step:{len(dataloader)*epoch+i}, recons_loss:{recons_loss.item()}, g_loss:{g_loss.item()}, d_loss:{d_loss.item()}, real_loss:{real_loss.item()}, fake_loss:{fake_loss.item()}")
# 在torchvision中保存照片
if i % 400 == 0:
image = pred_images[:16].data
torchvision.utils.save_image(image, f"image_{len(dataloader)*epoch+i}.png", nrow=4)
(1)直接预测【0,1】之间的像素值即可,不做归一化的transform;或者也可以放大,预测【-1,1】之间,用mean=0.5 std=0.5进行归一化transform都可以。
(2)save_image中的normalize设置成True,目的是将像素值min-max自动归一到【0,1】范围内,如果已经预测了【0,1】之间,则可以不用设置True
(3)判别器的学习率不能太小
(4)Adam的一阶平滑系数和二阶平滑系数 betas 适当调小一点,可以帮助学习,设置一定比例的weight decay
结果展示

生成器生成的图片:
由于没有GPU,只跑了一个epoch的一部分,但也能看出一定的效果!
image_4685.png:

二. 力源项目多台本地设备数据定时同步的改进实现
2.1 预备知识-mysql 数据库语句
1.简单的按照x1条件查询语句:
select * From Table1 where x1 = '是';
2.按照生产日期的查询语句:
SELECT
*
FROM
Table1
WHERE
CreatedDate BETWEEN '2022-04-15 11:48:40
'
AND Now();
3.直接更新字段数值:
UPDATE table_b0225 SET c1 = '否',c2 = '',j1 = '';
4.根据父码撤销出库的语句:
UPDATE Table1 SET c1 = '否',c2= '',j1 = '' where parentcode = 'LYB201882413481908';
5 .将A表中的数据按条件插入到B表中(合并表数据):
insert into B select * from A where CreatedDate BETWEEN '2022-04-15 11:33:18' AND Now();
6 .按表中p字段是否重复, 执行分组查询:
SELECT P,count( 1 )
FROM
Table1
GROUP BY
P
HAVING
count( 1 ) > 1;
7 .由于出现重复数据,我们将表重新导入两个新表数据后,需要保留备份原表中的出库信息等,下面我们就执行,按需要更新的字段内容选择需要更新的部分:
UPDATE Table1 a,Table1_yuanlai0420 b SET a.chuku=b.chuku,a.jxs=b.jxs,a.cky=b.cky
WHERE a.PackCode=b.PackCode;
语句基础知识如上。
2.2 第三方软件SyncNavigator的配置与操作
前提: 在云服务器上开通安全端口5555,随即必须修改默认mysql端口号3306为5555。最重要的是修改连接数据库交互代码,并修改所有后端代码。
难点:
1.使用之前测试过的存储过程,发现无法获得与服务器的授权访问(未开放安全端口);
2. 本地设备是局域网IP(难以固定IP),也较难实现与公网IP的相互授权访问,权限可能不够;
3.按存储过程,需要去创建事件,并设置定时执行任务;
4.同步过程中需要对特定表添加不同的字段,并合并到目标数据库。
操作详细流程与思路记录:
-
下载第三方数据库同步软件:参考官方教程即可完成(不做详细记录);
-
注册激活,具体教程自己参考例子,重新整理了一个详细版本(由于违反CSDN规定,只允许粉丝可见):Sync数据库软件下载与注册流程教程,激活过程有比较多的细节,之前安装花了一点时间,过程一定要细致,按照步骤,注意完整操作!
-
分别在两台本地设备上安装和激活软件,其实也可以在第三台机器上操作,但是由于两台本地是在局域网内,无固定的IP,很难去选择合适IP,(之前听说可以借助内网穿透,但没有接触过),还是选择最保守的方案。
-
安装激活后,就可以分别做连接测试了,分别将各自本地作来源数据库,选择需要同步的数据库名,测试连接成功即可;将云服务器作目标数据库,选择需要同步到的数据库名,连接测试成功即可。
-
关键步骤:选择需要来源数据库需要同步的表,并设置相关的同步参数,比如设置为简单单向同步,或者多向同步模式;允许在目标数据库中创建新表;最关键的是主键的设置,以防止冗余同步,造成数据大量重复!
-
同步内容参数的设置:

下面分别进行设置同步内容:注意必须要选择只追加新增数据!

按照上面的同步流程设置,借助别人写好的命令程序,计划调度我们还能够实现定时同步,按次,日,周,月,可以定点实现,或者自动实时同步。 -
出现了数据库冗余错误,大量重复多余的数据被同步!解决方案:先是备份数据库,清空了被重复同步的表数据,再将需要同步的库表中重新设计表,将packcode设置为主键,唯一区别的标识符,可以区别一行数据。保存后,重新执行同步操作!
三. Autoformer的代码部分理解
3.1 回顾autoformer
参考之前的记录:细读Autoformer01
对长时序的预测模型需求是非常大的,由此也改进了一些Transformer类模型,比如Informer,以及今天的Autoformer模型。之前的Informer,LogTrans,N-BEATS,LSTNet等等模型都对长时序数据预测做了重要的工作。但是对于以self-attention机制为主的模型,二次复杂度在计算程度上制约了模型的预测能力,尽管Informer等用了Sparse的操作,性能得到了提高,但是计算仍然是逐点聚合,稀疏又在一定程度上缺失了信息。
而Autoformer模型更加关注序列,并增加了自相关机制替换self-attention(创新点一),最重要的是将序列分解的模块融入到transformer内(创新点二)。(code:该源码是将其他的SOTA模型写入了模型框架,可以很好的复现)

3.2 细节部分-Series decomposition block
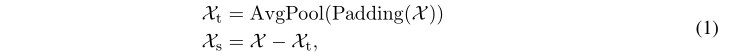

其中padding是为了保证序列长度不变,avgpool是移动平均。获取趋势项后,序列-趋势=季节。
X t X_t Xt?是总体趋势项,即趋势性部分,利用平均池化,再设置一定的kernel大小,就可以一定程度上去掉季节性短期变化带来的影响,Padding操作是为了保证pooling过程中序列长度不变; X s X_s Xs?是原数据减掉趋势性部分,就可以得到序列的季节性部分。
X t X_t Xt?存储的是每个滑动窗口的均值,而 X s X_s Xs?则是保留季节性的平滑序列。
下面是源代码中的SeriesDecomp的实现:
class Model(nn.Module):
def __init__(self, configs):
...
self.decomp = series_decomp(kernel_size)
...
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec,
enc_self_mask=None, dec_self_mask=None, dec_enc_mask=None):
...
seasonal_init, trend_init = self.decomp(x_enc)
...
class series_decomp(nn.Module):
"""
Series decomposition block
"""
def __init__(self, kernel_size):
super(series_decomp, self).__init__()
self.moving_avg = moving_avg(kernel_size, stride=1)
def forward(self, x):
moving_mean = self.moving_avg(x)
res = x - moving_mean
return res, moving_mean
class moving_avg(nn.Module):
"""
Moving average block to highlight the trend of time series
"""
def __init__(self, kernel_size, stride):
super(moving_avg, self).__init__()
self.kernel_size = kernel_size
self.avg = nn.AvgPool1d(kernel_size=kernel_size, stride=stride, padding=0)
def forward(self, x):
# padding on the both ends of time series
front = x[:, 0:1, :].repeat(1, (self.kernel_size - 1) // 2, 1)
end = x[:, -1:, :].repeat(1, (self.kernel_size - 1) // 2, 1)
x = torch.cat([front, x, end], dim=1)
x = self.avg(x.permute(0, 2, 1))
x = x.permute(0, 2, 1)
return x
其中关于 AvgPool1d函数 的理解可参考:pytorch AvgPool1d函数与AvgPool2d函数的应用
简单利用AvgPool1d函数做平均池化,而padding操作并非是使用padding参数,而是对输入序列的前部与后部分别做一次repeat复制之后concat,这样就不用补零。
3.3 Model inputs
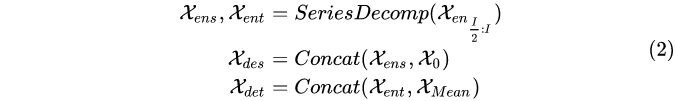
Encoder的输入是 X e n X_{en} Xen?,取样区间为原始序列长度。Decoder的输入由 X d e s X_{des} Xdes? , X d e t X_{det} Xdet?组成,每一个的取样区间都在原始序列的后半部分(取后I/2,原因是为了提高效率),各由两部分组成: X d e s X_{des} Xdes?是由 X e n s X_{ens} Xens? (X后半部分取样做SeriesDecomp的季节性输出)和 X 0 X_{0} X0?(0向量,占位用)组成, X d e t X_{det} Xdet?是由 X e n t X_{ent} Xent?(X后半部分取样做SeriesDecomp的周期趋势性输出)和均值向量组成。
# decoder input
trend_init = torch.cat([trend_init[:, -self.label_len:, :], mean], dim=1)
seasonal_init = torch.cat([seasonal_init[:, -self.label_len:, :], zeros], dim=1)
其中self.label_len是定义的超参。关于cat函数的理解:torch.cat() 函数用法
3.3 encoder
关注季节部分建模的编码器,输出的是过去季节性信息,它将被用做互信息,帮助解码器调整预测结果。只保留平滑的seasonal part, 每一层的处理公式如下:
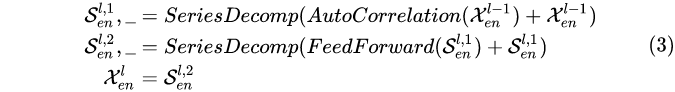
假设我们有 N 个编码器层。 第 l 个编码器层的整体方程总结为:
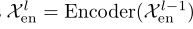
class Model(nn.Module):
def __init__(self, configs):
...
# Encoder
self.encoder = Encoder(
[
EncoderLayer(
AutoCorrelationLayer(
AutoCorrelation(False, configs.factor, attention_dropout=configs.dropout,
output_attention=configs.output_attention),
configs.d_model, configs.n_heads),
configs.d_model,
configs.d_ff, # dimension of FCN
moving_avg=configs.moving_avg,
dropout=configs.dropout,
activation=configs.activation
) for l in range(configs.e_layers)
],
norm_layer=my_Layernorm(configs.d_model)
)
...
3.4 decoder
对于季节项,自相关机制利用序列的周期性质,聚合不同周期中具有相似过程的子序列;对于趋势项,使用权重累积的方式,逐步从预测的隐变量中提取出趋势信息。其中, [ X e n N X_{en}^N XenN?] 是encoder中的潜在变量,第l个decoder layer的方程可以看作 X d e l = D e c o d e r ( X d e l ? 1 ) , X e n N ) X_{de}^l=Decoder(X_{de}^{l-1}),X_{en}^N) Xdel?=Decoder(Xdel?1?),XenN?) 。
class Model(nn.Module):
def __init__(self, configs):
...
# Decoder
self.decoder = Decoder(
[
DecoderLayer(
AutoCorrelationLayer(
AutoCorrelation(True, configs.factor, attention_dropout=configs.dropout,
output_attention=False),
configs.d_model, configs.n_heads),
AutoCorrelationLayer(
AutoCorrelation(False, configs.factor, attention_dropout=configs.dropout,
output_attention=False),
configs.d_model, configs.n_heads),
configs.d_model,
configs.c_out,
configs.d_ff,
moving_avg=configs.moving_avg,
dropout=configs.dropout,
activation=configs.activation,
)
for l in range(configs.d_layers)
],
norm_layer=my_Layernorm(configs.d_model),
projection=nn.Linear(configs.d_model, configs.c_out, bias=True)
)
...
3.5 Auto-Correlation Mechanism
这一块的代码没有看懂,后续研究吧。 加强对autoformer模型代码的解读与复现!
四. C# 百度API的使用
总结
一是关于项目对mysql 数据库同步问题的解决,从最初的利用存储过程,利用主从复制原理,在局域网内实现的主从复制,实时同步。但是它仅仅局限于局域网,而且对IP授权访问与存储日志需要较为繁琐的设置,不利于本地与云服务器mysql 的同步。现在的解决方法是借助第三方强大的同步命令与可视化操作界面,操作简单,管理方便,而且功能十分强大。
二是继续对Autoformer与Informer模型在LSTF问题上的研究学习与代码复现工作。
毕设:已完成搭建项目,论文说正在修改,后续保持联系。

