python����ѧϰ32
Beautiful soup ����
�ߡ�����ѡ����
֮ǰ����ѧϰ�ķ������ǻ���������ѡ���,��ʵ�����Ƿdz��������,��Ϊ��ѡȡij���ض��ڵ��ʱ��pycharm�Ͳ�����ʾ�ˡ�������ʱ�����ǾͿ���ʹ��Beautiful SoupΪ�����ṩ��һЩ��ѯ����,����find_all��find��,Ȼ������Ӧ�IJ����Ϳ��Խ��и�������ѯ�ˡ�
7-1 find_all����
�鿴find_all����ʱ,���Կ�����������API
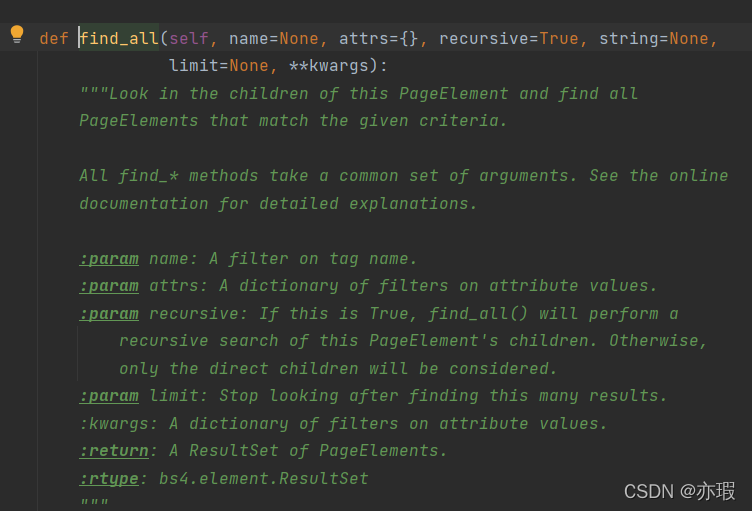
name �ֶ�
���html,��˫��������:
html = """
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">��ҳ</a></li>
<li><a href="/modules/article/bookcase.php">�ҵ����</a></li>
<li><a href="/xuanhuanxiaoshuo/">����С˵</a></li>
<li><a href="/xiuzhenxiaoshuo/">����С˵</a></li>
<li><a href="/dushixiaoshuo/">����С˵</a></li>
<li><a href="/chuanyuexiaoshuo/">��ԽС˵</a></li>
<li><a href="/wangyouxiaoshuo/">����С˵</a></li>
<li><a href="/kehuanxiaoshuo/">�ƻ�С˵</a></li>
<li><a href="/paihangbang/">���а�</a></li>
<li><a href="/wanben/1_1">�걾С˵</a></li>
<li><a href="/xiaoshuodaquan/">ȫ��С˵</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
ʵ������
from bs4 import BeautifulSoup
html = """
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">��ҳ</a></li>
<li><a href="/modules/article/bookcase.php">�ҵ����</a></li>
<li><a href="/xuanhuanxiaoshuo/">����С˵</a></li>
<li><a href="/xiuzhenxiaoshuo/">����С˵</a></li>
<li><a href="/dushixiaoshuo/">����С˵</a></li>
<li><a href="/chuanyuexiaoshuo/">��ԽС˵</a></li>
<li><a href="/wangyouxiaoshuo/">����С˵</a></li>
<li><a href="/kehuanxiaoshuo/">�ƻ�С˵</a></li>
<li><a href="/paihangbang/">���а�</a></li>
<li><a href="/wanben/1_1">�걾С˵</a></li>
<li><a href="/xiaoshuodaquan/">ȫ��С˵</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html, 'lxml')
# ʹ��find_all����,��ѯ��������Ϊul�Ľڵ�
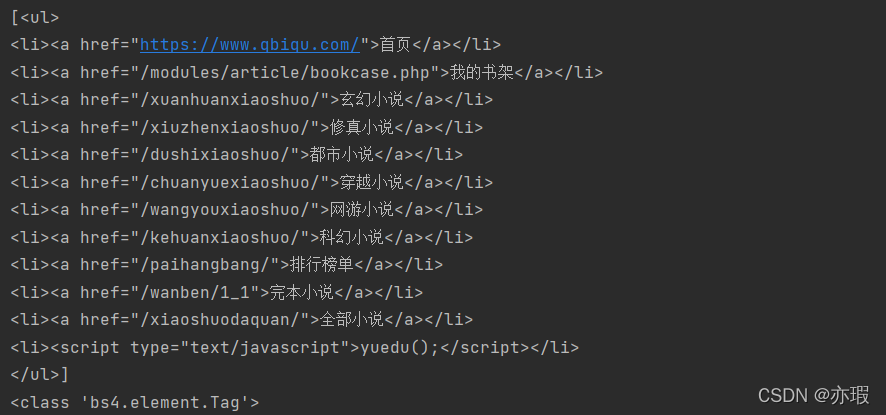
print(soup.find_all(name='ul'))
print(type(soup.find_all(name='ul')[0]))
���н��:��Ȼ,�ı��е�ul�ڵ�ֻ��һ��,���ҷ��صĽ��������һ���б��С�
���Կ����б��е�ÿһ��Ԫ�ص�����ΪTag��,�������ǿ��Խ���Ƕ�ײ�ѯ:
from bs4 import BeautifulSoup
html = """
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">��ҳ</a></li>
<li><a href="/modules/article/bookcase.php">�ҵ����</a></li>
<li><a href="/xuanhuanxiaoshuo/">����С˵</a></li>
<li><a href="/xiuzhenxiaoshuo/">����С˵</a></li>
<li><a href="/dushixiaoshuo/">����С˵</a></li>
<li><a href="/chuanyuexiaoshuo/">��ԽС˵</a></li>
<li><a href="/wangyouxiaoshuo/">����С˵</a></li>
<li><a href="/kehuanxiaoshuo/">�ƻ�С˵</a></li>
<li><a href="/paihangbang/">���а�</a></li>
<li><a href="/wanben/1_1">�걾С˵</a></li>
<li><a href="/xiaoshuodaquan/">ȫ��С˵</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html, 'lxml')
ul_list = soup.find_all(name='ul')
# ����Ϊ�˸�������ʹ����ѭ��,��������������б���ֻ��һ��Ԫ��,Ϊ��ʡ�µĻ�����ֱ�ӽ��е���
for item in ul_list:
print(item.find_all(name='li'))
���н��:��ul�ڵ��µ�����li�ڵ�ͱ���ѯ������:

�ȿ�,��ҿ�����ϰһ�������ϵĻ�����Ƕ��������li�ڵ��µ�a�ڵ�,����Ͳ��ٽ���չʾ��(�ɲ���͵����!)
��ȡ�ڵ��ڵ�����:
from bs4 import BeautifulSoup
html = """
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">��ҳ</a></li>
<li><a href="/modules/article/bookcase.php">�ҵ����</a></li>
<li><a href="/xuanhuanxiaoshuo/">����С˵</a></li>
<li><a href="/xiuzhenxiaoshuo/">����С˵</a></li>
<li><a href="/dushixiaoshuo/">����С˵</a></li>
<li><a href="/chuanyuexiaoshuo/">��ԽС˵</a></li>
<li><a href="/wangyouxiaoshuo/">����С˵</a></li>
<li><a href="/kehuanxiaoshuo/">�ƻ�С˵</a></li>
<li><a href="/paihangbang/">���а�</a></li>
<li><a href="/wanben/1_1">�걾С˵</a></li>
<li><a href="/xiaoshuodaquan/">ȫ��С˵</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html, 'lxml')
for item in soup.find_all(name='ul'):
i = item.find_all(name='li')
for thing in i:
print(thing.string)
���н��:�ᵽ���ݵĻ����������뵽string����

attrs �ֶ�
attrs�ֶ����ڽ��а����Բ�ѯ:
# attrs
from bs4 import BeautifulSoup
html = """
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">��ҳ</a></li>
<li><a href="/modules/article/bookcase.php">�ҵ����</a></li>
<li><a href="/xuanhuanxiaoshuo/">����С˵</a></li>
<li><a href="/xiuzhenxiaoshuo/">����С˵</a></li>
<li><a href="/dushixiaoshuo/">����С˵</a></li>
<li><a href="/chuanyuexiaoshuo/">��ԽС˵</a></li>
<li><a href="/wangyouxiaoshuo/">����С˵</a></li>
<li><a href="/kehuanxiaoshuo/">�ƻ�С˵</a></li>
<li><a href="/paihangbang/">���а�</a></li>
<li><a href="/wanben/1_1">�걾С˵</a></li>
<li><a href="/xiaoshuodaquan/">ȫ��С˵</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html, 'lxml')
# ��ʽΪ �ֵ� ���������ơ�:����������ֵ��
# ��Ϊ����class����Ϊdahengfu�Ľڵ�
print(soup.find_all(attrs={'class': 'dahengfu'}))
print(soup.find_all(attrs={'id': 'banner'}))
����:

����һЩ���õ�����,����Ҳ����͵��һ��:
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(id='banner'))
����:

text �ֶ�
text�ֶ�����ƥ��ڵ��ı�,�䴫����ʽ�������ַ���,Ҳ�������������ʽ����:
from bs4 import BeautifulSoup
import re
html = """
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">��ҳ</a></li>
<li><a href="/modules/article/bookcase.php">�ҵ����</a></li>
<li><a href="/xuanhuanxiaoshuo/">����С˵</a></li>
<li><a href="/xiuzhenxiaoshuo/">����С˵</a></li>
<li><a href="/dushixiaoshuo/">����С˵</a></li>
<li><a href="/chuanyuexiaoshuo/">��ԽС˵</a></li>
<li><a href="/wangyouxiaoshuo/">����С˵</a></li>
<li><a href="/kehuanxiaoshuo/">�ƻ�С˵</a></li>
<li><a href="/paihangbang/">���а�</a></li>
<li><a href="/wanben/1_1">�걾С˵</a></li>
<li><a href="/xiaoshuodaquan/">ȫ��С˵</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html, 'lxml')
# �������к���С˵�Ľڵ����ı�
print(soup.find_all(text=re.compile('С˵')))
����:

7-2 find
find����Ҳ���Բ�ѯ����������Ԫ��,����find��find_all����������find�������ص�һ�����ϵĽ��,����������֮ǰѧϰ����ʱfetch��find_all������
# find����
from bs4 import BeautifulSoup
html = """
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">��ҳ</a></li>
<li><a href="/modules/article/bookcase.php">�ҵ����</a></li>
<li><a href="/xuanhuanxiaoshuo/">����С˵</a></li>
<li><a href="/xiuzhenxiaoshuo/">����С˵</a></li>
<li><a href="/dushixiaoshuo/">����С˵</a></li>
<li><a href="/chuanyuexiaoshuo/">��ԽС˵</a></li>
<li><a href="/wangyouxiaoshuo/">����С˵</a></li>
<li><a href="/kehuanxiaoshuo/">�ƻ�С˵</a></li>
<li><a href="/paihangbang/">���а�</a></li>
<li><a href="/wanben/1_1">�걾С˵</a></li>
<li><a href="/xiaoshuodaquan/">ȫ��С˵</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.find(name='li'))
����:

���ս���,δ�����

