0-效果预览
1-相关说明:
haystack 全文检索框架,可配置各种搜索引擎,在Django内相当于app
whoosh 搜索引擎
2-whoosh下载与优化 中文分词jieba
下载:
pip install whoosh -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
优化:由于whoosh搜索引擎自带的中文分词功能效果较差,所以为whoosh搜索引擎配置jieba库进行分词。(可不操作,但中文效果差)
下载jieba:
pip install jieba -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
配置(虚拟envs\Lib\site-packages\haystack\backends中)
a-添加文件ChineseAnalyzer.py(主要作用,使用jieba进行分词处理)
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def call(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
b-复制文件 whoosh_backend将其重命名为whoosh_cn_backend并修改
from jieba.analyse import ChineseAnalyzer #在顶部添加
#注意先找到这个再修改,而不是直接添加
schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=ChineseAnalyzer(),field_boost=field_class.boost, sortable=True)
3-haystack下载与配置
下载:
pip install django-haystack -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
配置(setting中):
INSTALLED_APPS = [
'django.contrib.admin',
# 其它 app...
'haystack',
]
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'blog.whoosh_cn_backend.WhooshEngine',#配置搜索引擎
#'ENGINE': 'blog.whoosh_backend.WhooshEngine',#若没修改,则使用原生
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),#配置索引存放位置
},
}
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 10 #每页包含多少条
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
4-配置需要建立索引的model字段
应用下建立search_indexes.py文件
from haystack import indexes
from myblog.models import Blog #Blog是需建立索引的数据表名
#类名必须为需要检索的Model_name+Index,
class BlogIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.CharField(document=True, use_template=True)
def get_model(self):
return Blog
def index_queryset(self, using=None):
return self.get_model().objects.all()
#在template/search/indexes/项目名/模型名_text.txt设置数据模板,来构建文档搜索引擎索引
{{object.title}}
{{object.body}}
{{object.author.nickname}}
5-生成索引数据文件
python manage.py rebuild_index
6-设置路由,模板等
方法一:使用haystack自带的函数
path(‘search’, include(‘haystack.urls’)),#博客搜索(固定设置)
虚拟envs\Lib\site-packages\haystack\urls.py查看文件内容如下
from django.urls import path
from haystack.views import SearchView
urlpatterns = [path("", SearchView(), name="haystack_search")]
虚拟envs\Lib\site-packages\haystack\views.py查看SearchView()函数如下(部分)
template = "search/search.html"
(具体内容自己看,包含分页等如果需要在此基础上修改,则使用继承自己编写)
class MySearchView(SearchView)
方法二:自己编写对应函数及模板
path(‘search’, views.blog_search),#博客搜索
def blog_search(request):
from haystack.query import SearchQuerySet, Raw
query = request.GET.get('q')
page_num = request.GET.get('page')
posts = SearchQuerySet().filter(text=Raw(query))
# articles = SearchQuerySet().filter(text=Raw(qParams)).order_by('view_num') # 根据浏览量排序显示
if not page_num:
page = posts[0:10]
post_num = page.__len__()
print(page_num, query)
return render(request,'search/search.html',locals())
else:
page_num = int(page_num)
page = posts[(page_num-1)*10:page_num*10]
print(page_num, query)
return render(request,'blog/blog_search.html',locals())
7-图示与说明
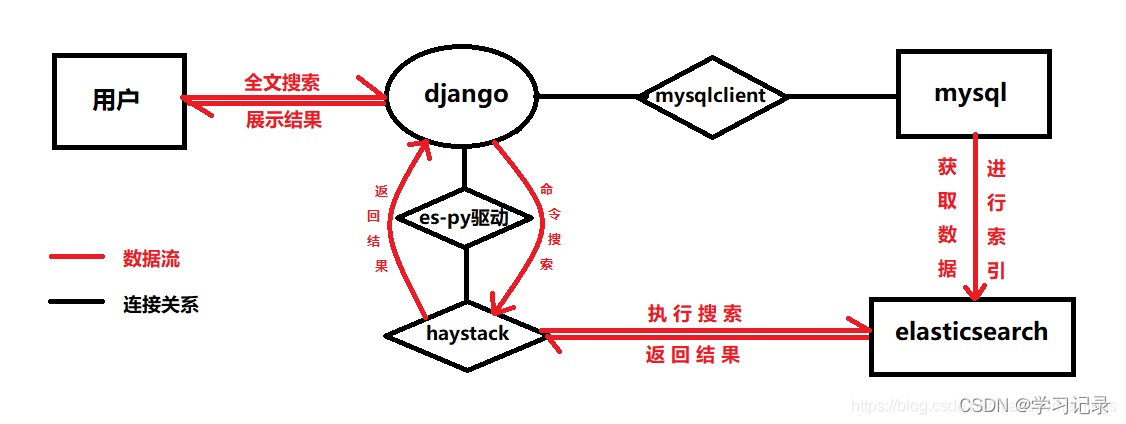
- 全文搜索需要分词和模糊查询, 这些操作在mysql中也可以使用, 但如果遇到数据量大的项目, 效率会很低, 因此,
就需要借助搜索引擎elasticsearch - 要实现查询, 那么我们的django需要连接mysql和elasticsearch: 连接mysql使用的是mysqlclient
连接elasticsearch使用的是django-haystack, 以及python的es驱动 - elasticsearch会去到mysql中获取数据, 然后进行索引, 并储存到它自己那里
- 用户将全文搜索的请求发送至django, 即输入搜索内容
- 然后django就会利用haystack到elasticsearch中查询想要的数据, 即执行搜索
- es查询到后返回给haystack(haystack是属于django项目中的一个从外部引入的app)
- haystack会返回给django框架, 然后django再展示给用户看, 即展示搜索结果
参考链接
https://blog.csdn.net/geerniya/article/details/79254845 配置+高亮
https://blog.csdn.net/geerniya/article/details/79255772 高亮问题修改
https://blog.csdn.net/makesomethings/article/details/100061591 elasticsearch配置相关
https://blog.csdn.net/ac_hell/article/details/52875927 配置,
https://blog.csdn.net/qq_36978602/article/details/81407676 滚动翻页

