前期工作
找bing的每日一图壁纸,观察网页结构
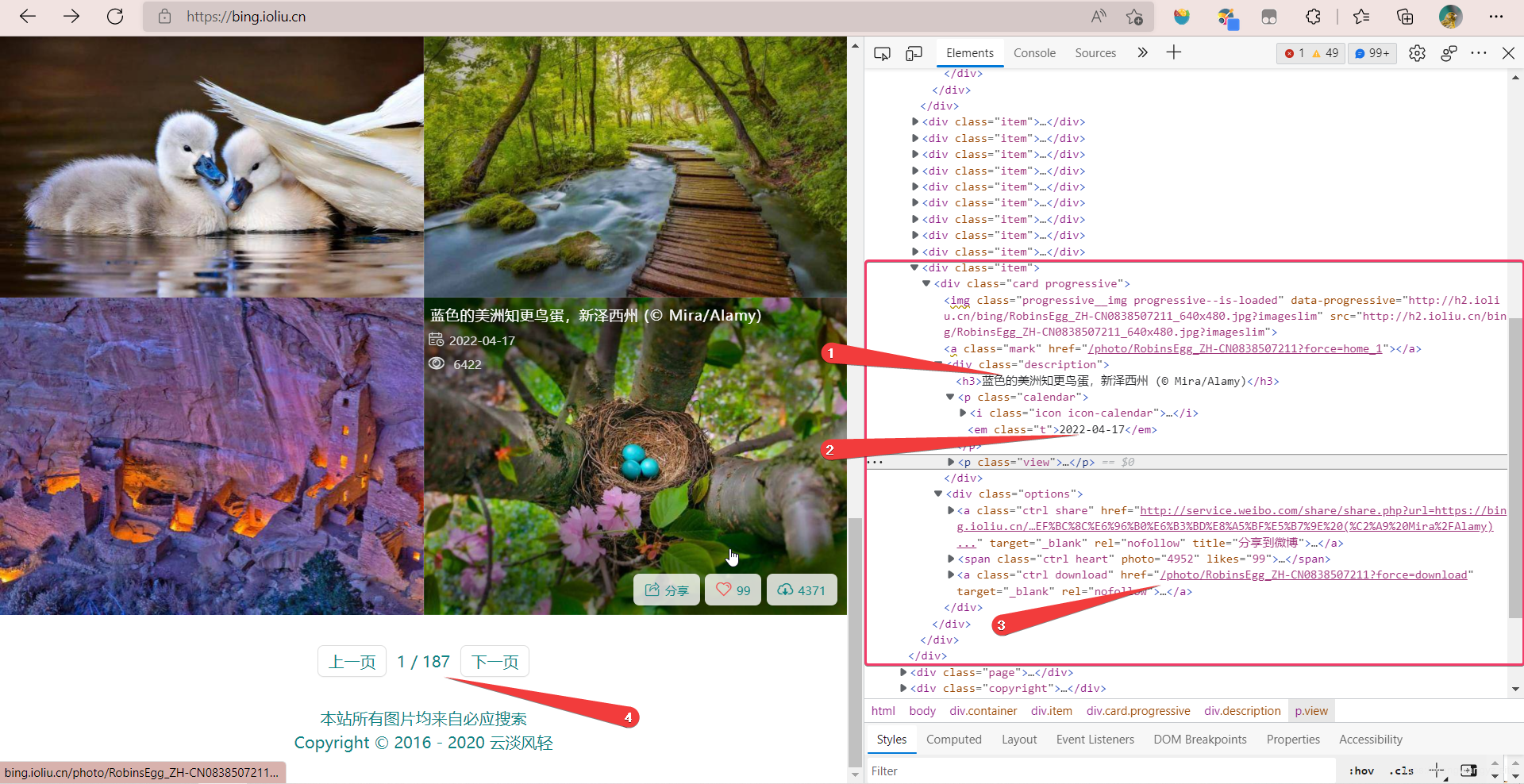
①是图片的描述
②是图片的时间
③是图片的下载地址
④是当前页面page的页数1和总页数187
编写功能函数
捕获不同page网页html信息,用requests库:
# param:页面的相应地址
# return:成功则返回相应DOM文档,失败则返回信息msg
def get_response_text(pageNum):
msg=""
try:
currentSite = mainSite + "/?p=" + str(pageNum)
respose = requests.get(url=currentSite,headers=myheader)
status_code = respose.status_code
if 200 <= status_code < 300:
msg = '请求站点操作成功'
return respose.text
elif status_code == 401:
msg = '请求站点匿名用户访问权限资源时的异常'
elif status_code == 403:
msg = '请求站点无访问权限,请联系管理员授予权限'
elif status_code == 404:
msg = '请求站点请求的资源不存在'
elif status_code == 500:
msg = '请求站点请求资源的系统异常,请稍后重试'
else:
msg = '请求站点未知返回代码'
except requests.exceptions.ConnectionError as e:
print("连接错误,请求站点是否可以访问?是否有网络或网络不稳定?\n请检查网络问题...\n"+e)
time.sleep(10)
except requests.exceptions.InvalidURL as e:
print("非法的URL,请验证URL是否正确或网站是否存在\n"+e)
except requests.exceptions.ReadTimeout:
print("请求站点远程服务器无响应数据")
time.sleep(10)
except:
print("请求站点遇到未知错误...")
time.sleep(10)
finally:
print(msg)
return msg
返回当前page所有的图片信息
#根据不同页面返回图片的信息
def get_PicUrlList(pageNum):
url_list = []
mainText = get_response_text(pageNum)
#正则规则
rule = re.compile(r'class="description"><h3>(.*?) \(?.*?<em class="t">(.*?)</em>.*?class=\"ctrl download\" href=\"(.*?)\" target')
result_groups = re.findall(rule,mainText)
#由网页结构可知:匹配结果i[0]、i[1]、i[2]分别代表图片的描述、图片的时间、图片的下载地址
if result_groups:
for i in result_groups:
img_info={
'description':i[0],
'time':i[1],
'url':mainSite+i[2]
}
url_list.append(img_info)
else:
print("No match!!")
return url_list
下载函数,用shell的wget,下载速度更快更稳定
def downloadPic(img_info):
global success,fail
try:
#利用Shell下载图片
os.system("sudo wget "+img_info['url']+" -q -O /mnt/c/Users/86199/OneDrive/图片/"+img_info['description']+img_info['time']+'.jpg')
success.append(img_info)
print(img_info['description']+img_info['time']+'.png', '保存成功!')
#每隔一分钟下载一张
#time.sleep(60)
except:
fail.append(img_info)
print("something wrong!\n")
增加一个程序退出时执行函数,把下载信息写入
@atexit.register
def write_info():
with open('info.txt','w',encoding='utf-8') as file:
file.write("fail:"+str(fail)+("\n")+ "total:" + str(len(fail))
+"success:"+str(success)+("\n")+ "total:" + str(len(success))
+"current-page:"+str(currentPage))
主运行功能函数
def main_run():
global completeCount,failCount,currentPage, totalPage
for i in range(totalPage):
url_list = get_PicUrlList(currentPage)
for img_info in url_list:
print("正在下载:"+img_info['description']+"\t图片")
downloadPic(img_info)
print('page:' + str(currentPage) + 'complete')
currentPage += 1
with open('info.txt','w',encoding='utf-8') as file:
file.write("fail:"+str(fail)+("\n")+ "total:" + str(len(fail))
+"success:"+str(success)+("\n")+ "total:" + str(len(success))
+"current-page:"+str(currentPage))
总文件main.py
import os
import random
import re
import time
import requests
import atexit
totalPage = 187 #网站的总页数
currentPage = 1 #当前爬取图片的页数
myheader = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.46 '
}
statusCode = 0 #爬取时返回的HTTP状态码
mainSite = "https://bing.ioliu.cn" #要爬的网页
pic_url_list = [] #图片的下载地址
fail=[] #下载失败的url
success=[] #下载成功的url
# param:页面的相应地址
# return:成功直接返回相应DOM文档,失败返回 "什么也没有"
def get_response_text(pageNum):
msg=""
try:
currentSite = mainSite + "/?p=" + str(pageNum)
respose = requests.get(url=currentSite,headers=myheader)
status_code = respose.status_code
if 200 <= status_code < 300:
msg = '请求站点操作成功'
elif status_code == 401:
msg = '请求站点匿名用户访问权限资源时的异常'
elif status_code == 403:
msg = '请求站点无访问权限,请联系管理员授予权限'
elif status_code == 404:
msg = '请求站点请求的资源不存在'
elif status_code == 500:
msg = '请求站点请求资源的系统异常,请稍后重试'
else:
msg = '请求站点未知返回代码'
except requests.exceptions.ConnectionError as e:
print("连接错误,请求站点是否可以访问?是否有网络或网络不稳定?\n请检查网络问题...\n"+e)
time.sleep(10)
except requests.exceptions.InvalidURL as e:
print("非法的URL,请验证URL是否正确或网站是否存在\n"+e)
except requests.exceptions.ReadTimeout:
print("请求站点远程服务器无响应数据")
time.sleep(10)
except:
print("请求站点遇到未知错误...")
time.sleep(10)
finally:
print(msg)
return respose.text
def get_PicUrlList(pageNum):
url_list = []
mainText = get_response_text(pageNum)
rule = re.compile(r'class="description"><h3>(.*?) \(?.*?<em class="t">(.*?)</em>.*?class=\"ctrl download\" href=\"(.*?)\" target')
result_groups = re.findall(rule,mainText)
if result_groups:
for i in result_groups:
img_info={
'description':i[0],
'time':i[1],
'url':mainSite+i[2]
}
url_list.append(img_info)
else:
print("No match!!")
return url_list
def downloadPic(img_info):
global success,fail
try:
#利用Shell下载图片
os.system("sudo wget "+img_info['url']+" -q -O /mnt/c/Users/86199/OneDrive/图片/"+img_info['description']+img_info['time']+'.jpg')
success.append(img_info)
print(img_info['description']+img_info['time']+'.png', '保存成功!')
#每隔一分钟下载一张
# time.sleep(60)
except:
fail.append(img_info)
print("something wrong!\n")
def main_run():
global completeCount,failCount,currentPage, totalPage
for i in range(totalPage):
url_list = get_PicUrlList(currentPage)
for img_info in url_list:
print("正在下载:"+img_info['description']+"\t图片")
downloadPic(img_info)
print('page:' + str(currentPage) + 'complete')
currentPage += 1
with open('info.txt','w',encoding='utf-8') as file:
file.write("fail:"+str(fail)+("\n")+ "total:" + str(len(fail))
+"success:"+str(success)+("\n")+ "total:" + str(len(success))
+"current-page:"+str(currentPage))
@atexit.register
def write_info():
with open('info.txt','w',encoding='utf-8') as file:
file.write("fail:"+str(fail)+("\n")+ "total:" + str(len(fail))
+"success:"+str(success)+("\n")+ "total:" + str(len(success))
+"current-page:"+str(currentPage))
if __name__== "__main__":
main_run()
linux下挂起后台开跑
sudo nohup python3 main.py > run.out 2>&1 &
测试结果
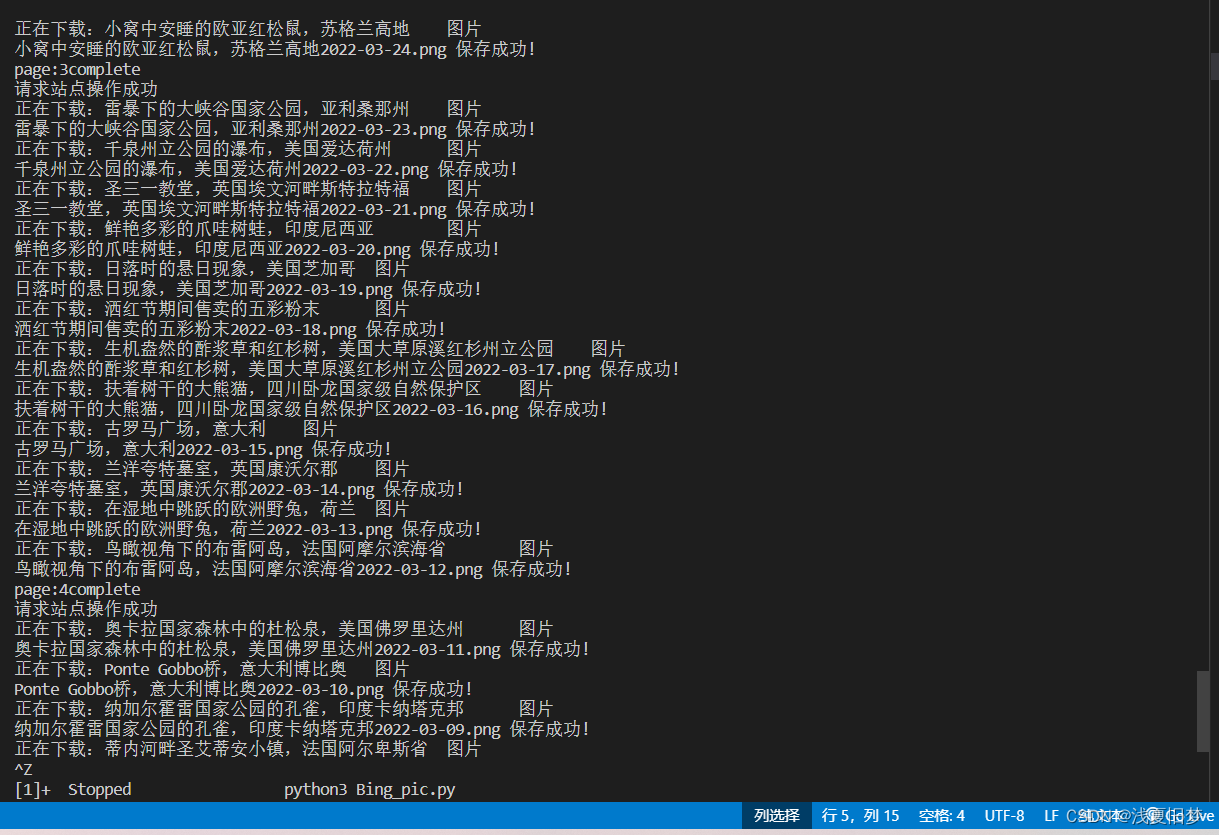
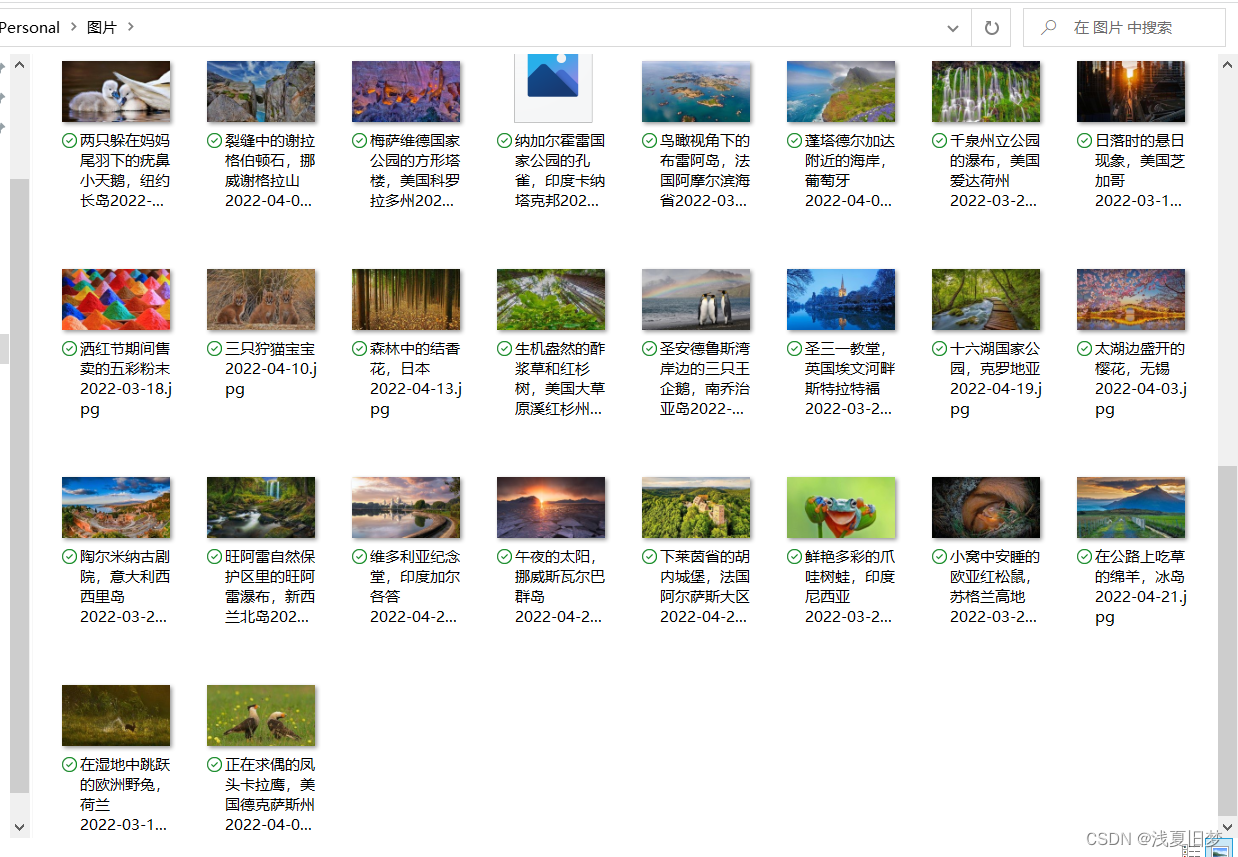
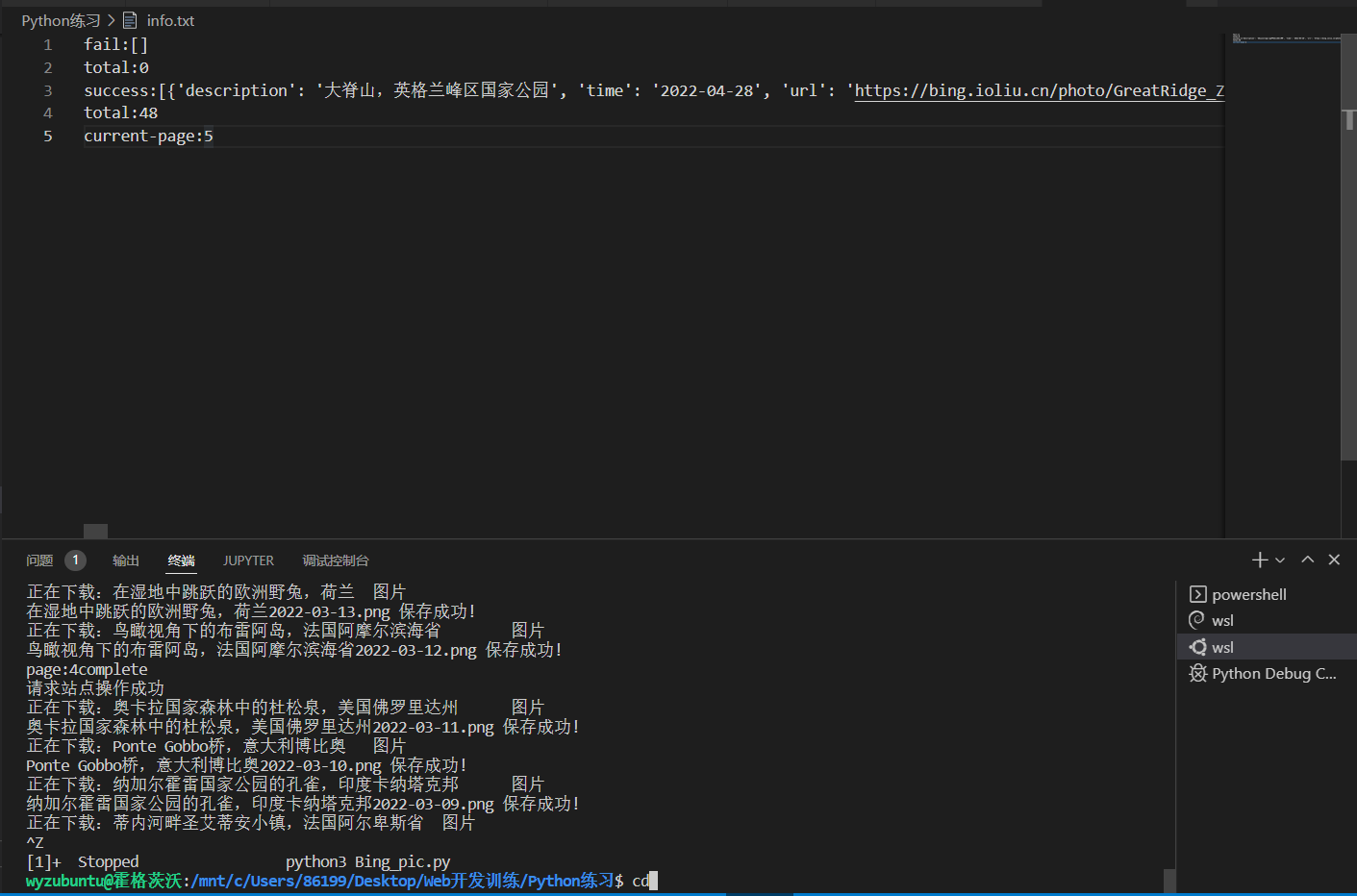
info.txt:
注意事项
在下载图片的那个功能函数里,需要根据自己的主机修改下载目录,
最好每下载一张就歇一会,我不知道网站有没有反爬,一直下载可能会被识别到时候IP被禁了就不好了。
源站有流量限制,本身下载就很慢(估计很多人都拿来爬。。。),如果没看到结果先自己用自己的电脑下载看能不能下
相关教程
atexit ― 退出处理器 ― Python 3.10.4 文档
atexit模块定义了清理函数的注册和反注册函数. 被注册的函数会在解释器正常终止时执行. atexit会按照注册顺序的逆序执行; 如果你注册了 A, B 和 C, 那么在解释器终止时会依序执行 C, B, A.
注意: 通过该模块注册的函数, 在程序被未被 Python 捕获的信号杀死时并不会执行, 在检测到 Python 内部致命错误以及调用了os._exit() 时也不会执行.
用法: wget [选项]... [URL]...
长选项所必须的参数在使用短选项时也是必须的。
启动:
-V, --version 显示 Wget 的版本信息并退出。
-h, --help 打印此帮助。
-b, --background 启动后转入后台。
-e, --execute=COMMAND 运行一个“.wgetrc”风格的命令。
日志和输入文件:
-o, --output-file=FILE 将日志信息写入 FILE。
-a, --append-output=FILE 将信息添加至 FILE。
-d, --debug 打印大量调试信息。
-q, --quiet 安静模式 (无信息输出)。
-v, --verbose 详尽的输出 (此为默认值)。
-nv, --no-verbose 关闭详尽输出,但不进入安静模式。
--report-speed=TYPE Output bandwidth as TYPE. TYPE can be bits.
-i, --input-file=FILE 下载本地或外部 FILE 中的 URLs。
-F, --force-html 把输入文件当成 HTML 文件。
-B, --base=URL 解析与 URL 相关的
HTML 输入文件 (由 -i -F 选项指定)。
--config=FILE Specify config file to use.
下载:
-t, --tries=NUMBER 设置重试次数为 NUMBER (0 代表无限制)。
--retry-connrefused 即使拒绝连接也是重试。
-O, --output-document=FILE 将文档写入 FILE。
-nc, --no-clobber skip downloads that would download to
existing files (overwriting them).
-c, --continue 断点续传下载文件。
--progress=TYPE 选择进度条类型。
-N, --timestamping 只获取比本地文件新的文件。
--no-use-server-timestamps 不用服务器上的时间戳来设置本地文件。
-S, --server-response 打印服务器响应。
--spider 不下载任何文件。
-T, --timeout=SECONDS 将所有超时设为 SECONDS 秒。
--dns-timeout=SECS 设置 DNS 查寻超时为 SECS 秒。
--connect-timeout=SECS 设置连接超时为 SECS 秒。
--read-timeout=SECS 设置读取超时为 SECS 秒。
-w, --wait=SECONDS 等待间隔为 SECONDS 秒。
--waitretry=SECONDS 在获取文件的重试期间等待 1..SECONDS 秒。
--random-wait 获取多个文件时,每次随机等待间隔
0.5*WAIT...1.5*WAIT 秒。
--no-proxy 禁止使用代理。
-Q, --quota=NUMBER 设置获取配额为 NUMBER 字节。
--bind-address=ADDRESS 绑定至本地主机上的 ADDRESS (主机名或是 IP)。
--limit-rate=RATE 限制下载速率为 RATE。
--no-dns-cache 关闭 DNS 查寻缓存。
--restrict-file-names=OS 限定文件名中的字符为 OS 允许的字符。
--ignore-case 匹配文件/目录时忽略大小写。
-4, --inet4-only 仅连接至 IPv4 地址。
-6, --inet6-only 仅连接至 IPv6 地址。
--prefer-family=FAMILY 首先连接至指定协议的地址
FAMILY 为 IPv6,IPv4 或是 none。
--user=USER 将 ftp 和 http 的用户名均设置为 USER。
--password=PASS 将 ftp 和 http 的密码均设置为 PASS。
--ask-password 提示输入密码。
--no-iri 关闭 IRI 支持。
--local-encoding=ENC IRI (国际化资源标识符) 使用 ENC 作为本地编码。
--remote-encoding=ENC 使用 ENC 作为默认远程编码。
--unlink remove file before clobber.
目录:
-nd, --no-directories 不创建目录。
-x, --force-directories 强制创建目录。
-nH, --no-host-directories 不要创建主目录。
--protocol-directories 在目录中使用协议名称。
-P, --directory-prefix=PREFIX 以 PREFIX/... 保存文件
--cut-dirs=NUMBER 忽略远程目录中 NUMBER 个目录层。
HTTP 选项:
--http-user=USER 设置 http 用户名为 USER。
--http-password=PASS 设置 http 密码为 PASS。
--no-cache 不在服务器上缓存数据。
--default-page=NAME 改变默认页
(默认页通常是“index.html”)。
-E, --adjust-extension 以合适的扩展名保存 HTML/CSS 文档。
--ignore-length 忽略头部的‘Content-Length’区域。
--header=STRING 在头部插入 STRING。
--max-redirect 每页所允许的最大重定向。
--proxy-user=USER 使用 USER 作为代理用户名。
--proxy-password=PASS 使用 PASS 作为代理密码。
--referer=URL 在 HTTP 请求头包含‘Referer: URL’。
--save-headers 将 HTTP 头保存至文件。
-U, --user-agent=AGENT 标识为 AGENT 而不是 Wget/VERSION。
--no-http-keep-alive 禁用 HTTP keep-alive (永久连接)。
--no-cookies 不使用 cookies。
--load-cookies=FILE 会话开始前从 FILE 中载入 cookies。
--save-cookies=FILE 会话结束后保存 cookies 至 FILE。
--keep-session-cookies 载入并保存会话 (非永久) cookies。
--post-data=STRING 使用 POST 方式;把 STRING 作为数据发送。
--post-file=FILE 使用 POST 方式;发送 FILE 内容。
--content-disposition 当选中本地文件名时
允许 Content-Disposition 头部 (尚在实验)。
--content-on-error output the received content on server errors.
--auth-no-challenge 发送不含服务器询问的首次等待
的基本 HTTP 验证信息。
HTTPS (SSL/TLS) 选项:
--secure-protocol=PR choose secure protocol, one of auto, SSLv2,
SSLv3, TLSv1, TLSv1_1 and TLSv1_2.
--no-check-certificate 不要验证服务器的证书。
--certificate=FILE 客户端证书文件。
--certificate-type=TYPE 客户端证书类型,PEM 或 DER。
--private-key=FILE 私钥文件。
--private-key-type=TYPE 私钥文件类型,PEM 或 DER。
--ca-certificate=FILE 带有一组 CA 认证的文件。
--ca-directory=DIR 保存 CA 认证的哈希列表的目录。
--random-file=FILE 带有生成 SSL PRNG 的随机数据的文件。
--egd-file=FILE 用于命名带有随机数据的 EGD 套接字的文件。
FTP 选项:
--ftp-user=USER 设置 ftp 用户名为 USER。
--ftp-password=PASS 设置 ftp 密码为 PASS。
--no-remove-listing 不要删除‘.listing’文件。
--no-glob 不在 FTP 文件名中使用通配符展开。
--no-passive-ftp 禁用“passive”传输模式。
--preserve-permissions 保留远程文件的权限。
--retr-symlinks 递归目录时,获取链接的文件 (而非目录)。
WARC options:
--warc-file=FILENAME save request/response data to a .warc.gz file.
--warc-header=STRING insert STRING into the warcinfo record.
--warc-max-size=NUMBER set maximum size of WARC files to NUMBER.
--warc-cdx write CDX index files.
--warc-dedup=FILENAME do not store records listed in this CDX file.
--no-warc-compression do not compress WARC files with GZIP.
--no-warc-digests do not calculate SHA1 digests.
--no-warc-keep-log do not store the log file in a WARC record.
--warc-tempdir=DIRECTORY location for temporary files created by the
WARC writer.
递归下载:
-r, --recursive 指定递归下载。
-l, --level=NUMBER 最大递归深度 (inf 或 0 代表无限制,即全部下载)。
--delete-after 下载完成后删除本地文件。
-k, --convert-links 让下载得到的 HTML 或 CSS 中的链接指向本地文件。
--backups=N before writing file X, rotate up to N backup files.
-K, --backup-converted 在转换文件 X 前先将它备份为 X.orig。
-m, --mirror -N -r -l inf --no-remove-listing 的缩写形式。
-p, --page-requisites 下载所有用于显示 HTML 页面的图片之类的元素。
--strict-comments 用严格方式 (SGML) 处理 HTML 注释。
递归接受/拒绝:
-A, --accept=LIST 逗号分隔的可接受的扩展名列表。
-R, --reject=LIST 逗号分隔的要拒绝的扩展名列表。
--accept-regex=REGEX regex matching accepted URLs.
--reject-regex=REGEX regex matching rejected URLs.
--regex-type=TYPE regex type (posix|pcre).
-D, --domains=LIST 逗号分隔的可接受的域列表。
--exclude-domains=LIST 逗号分隔的要拒绝的域列表。
--follow-ftp 跟踪 HTML 文档中的 FTP 链接。
--follow-tags=LIST 逗号分隔的跟踪的 HTML 标识列表。
--ignore-tags=LIST 逗号分隔的忽略的 HTML 标识列表。
-H, --span-hosts 递归时转向外部主机。
-L, --relative 只跟踪有关系的链接。
-I, --include-directories=LIST 允许目录的列表。
--trust-server-names use the name specified by the redirection
url last component.
-X, --exclude-directories=LIST 排除目录的列表。
-np, --no-parent 不追溯至父目录。

