CPU密集型 VS IO密集型
我们可以把任务分为计算密集型和IO密集型。
????????第一种计算密集型任务的特点是要进??量的计算,消耗CPU资源,?如计算圆周率、对视频进??清解码等等,全靠CPU的运算能?。这种计算密集型任务虽然也可以?多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执?任务的效率就越低,所以,要最?效地利?CPU,计算密集型任务同时进?的数量应当等于CPU的核?数。
????????计算密集型任务由于主要消耗CPU资源,因此,代码运?效率?关重要。Python这样的脚本语?运?效率很低,完全不适合计算密集型任
务。对于计算密集型任务,最好?C语?编写。
????????第?种IO密集型,涉及到?络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的?部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越?,但也有?个限度。常见的?部分任务都是IO密集型任务,?如Web应?。
????????IO密集型任务执?期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,?运?速度极快的C语?替换?Python这样运?速度极低的脚本语?,完全?法提升运?效率。对于IO密集型任务,最合适的语?就是开发效率最?(代码量最少)的语?,脚本语?是?选,C语?最差。
????????所以,python更适合I/O密集型任务(一般都是走业务流程,网络和磁盘操作比较集中)
多进程--->多线程--->协程
一、什么是进程和线程
进程是分配资源的最小单位,线程是系统调度的最小单位。
当应用程序运行时最少会开启一个进程,此时计算机会为这个进程开辟独立的内存空间,不同的进程享有不同的空间,而一个CPU在同一时刻只能够运行一个进程,其他进程处于等待状态。
一个进程内部包括一个或者多个线程,这些线程共享此进程的内存空间与资源。相当于把一个任务又细分成若干个子任务,每个线程对应一个子任务。
二、多进程和多线程
对于一个CPU来说,在同一时刻只能运行一个进程或者一个线程,而单核CPU往往是在进程或者线程间切换执行,每个进程或者线程得到一定的CPU时间,由于切换的速度很快,在我们看来是多个任务在并行执行(同一时刻多个任务在执行),但实际上是在并发执行(一段时间内多个任务在执行)。
单核CPU的并发往往涉及到进程或者线程的切换,进程的切换比线程的切换消耗更多的时间与资源。在单核CPU下,CPU密集的任务采用多进程或多线程不会提升性能,而在IO密集的任务中可以提升(IO阻塞时CPU空闲)。
而多核CPU就可以做到同时执行多个进程或者多个进程,也就是并行运算。在拥有多个CPU的情况下,往往使用多进程或者多线程的模式执行多个任务。
三、python中的多进程和多线程
1、多进程
def Test(pid):
print("当前进程{}:{}".format(pid, os.getpid()))
for i in range(1000000000):
pass
if __name__ == '__main__':
#单进程
start = time.time()
for i in range(2):
Test(i)
end = time.time()
print((end - start))单进程输出结果如图1:
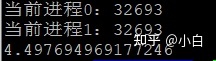
图1
def Test(pid):
print("当前子进程{}:{}".format(pid, os.getpid()))
for i in range(100000000):
pass
if __name__ == '__main__':
#多进程
print("父进程:{}".format(os.getpid()))
start = time.time()
pool = Pool(processes=2)
pid = [i for i in range(2)]
pool.map(Test, pid)
pool.close()
pool.join()
end = time.time()
print((end - start))多进程输出结果如图2:
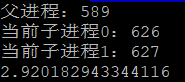
图2
从输出结果可以看出都是执行两次for循环,多进程比单进程减少了近乎一半的时间(这里使用了两个进程),并且查看CPU情况可以看出多进程利用了多个CPU。
python中的多进程可以利用mulitiprocess模块的Pool类创建,利用Pool的map方法来运行子进程。一般多进程的执行如下代码:
def Test(pid):
print("当前子进程{}:{}".format(pid, os.getpid()))
for i in range(100000000):
pass
if __name__ == '__main__':
#多进程
print("父进程:{}".format(os.getpid()))
pool = Pool(processes=2)
pid = [i for i in range(4)]
pool.map(Test, pid)
pool.close()
pool.join()1、利用Pool类创建一个进程池,processes声明在进程池中最多可以运行几个子进程,不声明的情况下会自动根据CPU数量来设定,原则上进程池容量不超过CPU数量。(出于资源的考虑,不要创建过多的进程)
2、声明一个可迭代的变量,该变量的长度决定要执行多少次子进程。
3、利用map()方法执行多进程,map方法两个参数,第一个参数是多进程执行的方法名,第二个参数是第二步声明的可迭代变量,里面的每一个元素是方法所需的参数。 这里需要注意几个点:1)进程池满的时候请求会等待,以上述代码为例,声明了一个容量为2的进程池,但是可迭代变量有4个,那么在执行的时候会先创建两个子进程,此时进程池已满,等待有子进程执行完成,才继续处理请求;
2) 子进程处理完一个请求后,会利用已经创建好的子进程继续处理新的请求而不会重新创建进程。
从图3可以看出上述两个点,如果同时处理4个进程,那么只需要2秒钟,这里是分成两次处理,花费了4秒,并且两次处理使用的子进程号都相同。

图3
3)map会将每个子进程的返回值汇总成一个列表返回。
4、在所有请求处理结束后使用close()方法关闭进程池不再接受请求。
5、使用join()方法让主进程阻塞,等待子进程退出,join()方法要放在close()方法之后,防止主进程在子进程结束之前退出。
2、多线程
python的多线程模块用threading类进行创建
import time
import threading
import os
count = 0
def change(n):
global count
count = count + n
count = count - n
def run(n):
print("当前子线程:{}".format(threading.current_thread().name))
for i in range(10000000):
change(n)
if __name__ == '__main__':
print("主线程:{}".format(threading.current_thread().name))
thread_1 = threading.Thread(target=run, args=(3,))
thread_2 = threading.Thread(target=run, args=(10,))
thread_1.start()
thread_2.start()
thread_1.join()
thread_2.join()
print(count)程序执行会创建一个进程,进程会默认启动一个主线程,使用threading.Thread()创建子线程;target为要执行的函数;args传入函数需要的参数;start()启动子线程,join()阻塞主线程先运行子线程。 由于变量由多个线程共享,任何一个线程都可以对于变量进行修改,如果同时多个线程修改变量就会出现错误。
上面的程序在理论上的结果应该为0,但运行结果如图4

图4
出现这个结果的原因就是多个线程同时对于变量修改,在赋值时出现错误,具体解释见多线程
解决这个问题就是在修改变量的时候加锁,这样就可以避免出现多个线程同时修改变量。
import time
import threading
import os
count = 0
lock = threading.Lock()
def change(n):
global count
count = count + n
count = count - n
def run(n):
print("当前子线程:{}".format(threading.current_thread().name))
for i in range(10000000):
# lock.acquire()
# try:
change(n)
# finally:
# lock.release()
if __name__ == '__main__':
print("主线程:{}".format(threading.current_thread().name))
thread_1 = threading.Thread(target=run, args=(3,))
thread_2 = threading.Thread(target=run, args=(10,))
thread_1.start()
thread_2.start()
thread_1.join()
thread_2.join()
print(count)python中的线程需要先获取GIL(Global Interpreter Lock)锁才能继续运行,每一个进程仅有一个GIL,线程在获取到GIL之后执行100字节码或者遇到IO中断时才会释放GIL,这样在CPU密集的任务中,即使有多个CPU,多线程也是不能够利用多个CPU来提高速率,甚至可能会因为竞争GIL导致速率慢于单线程。所以对于CPU密集任务往往使用多进程,IO密集任务使用多进程和多线程更具情况搭配。
python协程
通常我们认为线程是轻量级的进程,因此我们也把协程理解为轻量级的线程即微线程。
通常在Python中我们进行并发编程一般都是使用多线程或者多进程来实现的,对于计算型任务由于GIL的存在我们通常使用多进程来实现,而对于IO型任务我们可以通过线程调度来让线程在执行IO任务时让出GIL,从而实现表面上的并发。其实对于IO型任务我们还有一种选择就是协程,协程是运行在单线程当中的"并发",协程相比多线程一大优势就是省去了多线程之间的切换开销,获得了更大的运行效率。
协程,又称微线程,纤程,英文名Coroutine。协程的作用是在执行函数A时可以随时中断去执行函数B,然后中断函数B继续执行函数A(可以自由切换)。但这一过程并不是函数调用,这一整个过程看似像多线程,然而协程只有一个线程执行。
那协程有什么优势呢?
- 执行效率极高,因为子程序切换(函数)不是线程切换,由程序自身控制,没有切换线程的开销。所以与多线程相比,线程的数量越多,协程性能的优势越明显。
- 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在控制共享资源时也不需要加锁,因此执行效率高很多。
协程可以处理IO密集型程序的效率问题,但是处理CPU密集型不是它的长处,如要充分发挥CPU利用率可以结合多进程+协程。
Python中的协程经历了很长的一段发展历程。其大概经历了如下三个阶段:?最初的生成器变形yield/send?引入@asyncio.coroutine和yield from * 引入async/await关键字
上述是协程概念和优势的一些简介,感觉会比较抽象,Python2.x对协程的支持比较有限,生成器yield实现了一部分但不完全,gevent模块倒是有比较好的实现;Python3.4加入了asyncio模块,在Python3.5中又提供了async/await语法层面的支持,Python3.6中asyncio模块更加完善和稳定。接下来我们围绕这些内容详细阐述一下。
Python2.x协程
python2.x实现协程的方式有:?yield + send?gevent (见后续章节)
yield + send(利用生成器实现协程)
我们通过“生产者-消费者”模型来看一下协程的应用,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产。
#-*- coding:utf8 -*-
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER]Consuming %s...' % n)
r = '200 OK'
def producer(c):
# 启动生成器
c.send(None)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER]Producing %s...' % n)
r = c.send(n)
print('[PRODUCER]Consumer return: %s' % r)
c.close()
if __name__ == '__main__':
c = consumer()
producer(c)send(msg)与next()的区别在于send可以传递参数给yield表达式,这时传递的参数会作为yield表达式的值,而yield的参数是返回给调用者的值。换句话说,就是send可以强行修改上一个yield表达式的值。比如函数中有一个yield赋值a = yield 5,第一次迭代到这里会返回5,a还没有赋值。第二次迭代时,使用send(10),那么就是强行修改yield 5表达式的值为10,本来是5的,结果a = 10。send(msg)与next()都有返回值,它们的返回值是当前迭代遇到yield时,yield后面表达式的值,其实就是当前迭代中yield后面的参数。第一次调用send时必须是send(None),否则会报错,之所以为None是因为这时候还没有一个yield表达式可以用来赋值。上述例子运行之后输出结果如下:
[PRODUCER]Producing 1...
[CONSUMER]Consuming 1...
[PRODUCER]Consumer return: 200 OK
[PRODUCER]Producing 2...
[CONSUMER]Consuming 2...
[PRODUCER]Consumer return: 200 OK
[PRODUCER]Producing 3...
[CONSUMER]Consuming 3...
[PRODUCER]Consumer return: 200 OK
[PRODUCER]Producing 4...
[CONSUMER]Consuming 4...
[PRODUCER]Consumer return: 200 OK
[PRODUCER]Producing 5...
[CONSUMER]Consuming 5...
[PRODUCER]Consumer return: 200 OKPython3.x协程
除了Python2.x中协程的实现方式,Python3.x还提供了如下方式实现协程:?asyncio + yield from (python3.4+)?asyncio + async/await (python3.5+)
Python3.4以后引入了asyncio模块,可以很好的支持协程。
asyncio + yield from
asyncio是Python3.4版本引入的标准库,直接内置了对异步IO的支持。asyncio的异步操作,需要在coroutine中通过yield from完成。看如下代码(需要在Python3.4以后版本使用):
#-*- coding:utf8 -*-
import asyncio
@asyncio.coroutine
def test(i):
print('test_1', i)
r = yield from asyncio.sleep(1)
print('test_2', i)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
tasks = [test(i) for i in range(3)]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()@asyncio.coroutine把一个generator标记为coroutine类型,然后就把这个coroutine扔到EventLoop中执行。test()会首先打印出test_1,然后yield from语法可以让我们方便地调用另一个generator。由于asyncio.sleep()也是一个coroutine,所以线程不会等待asyncio.sleep(),而是直接中断并执行下一个消息循环。当asyncio.sleep()返回时,线程就可以从yield from拿到返回值(此处是None),然后接着执行下一行语句。把asyncio.sleep(1)看成是一个耗时1秒的IO操作,在此期间主线程并未等待,而是去执行EventLoop中其他可以执行的coroutine了,因此可以实现并发执行。
asyncio + async/await
为了简化并更好地标识异步IO,从Python3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。请注意,async和await是coroutine的新语法,使用新语法只需要做两步简单的替换:
- 把@asyncio.coroutine替换为async
- 把yield from替换为await
看如下代码(在Python3.5以上版本使用):
#-*- coding:utf8 -*-
import asyncio
async def test(i):
print('test_1', i)
await asyncio.sleep(1)
print('test_2', i)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
tasks = [test(i) for i in range(3)]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()运行结果与之前一致。与前一节相比,这里只是把yield from换成了await,@asyncio.coroutine换成了async,其余不变。
Gevent
Gevent是一个基于Greenlet实现的网络库,通过greenlet实现协程。基本思想是一个greenlet就认为是一个协程,当一个greenlet遇到IO操作的时候,比如访问网络,就会自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO操作。
Greenlet是作为一个C扩展模块,它封装了libevent事件循环的API,可以让开发者在不改变编程习惯的同时,用同步的方式写异步IO的代码。
#-*- coding:utf8 -*-
import gevent
def test(n):
for i in range(n):
print(gevent.getcurrent(), i)
if __name__ == '__main__':
g1 = gevent.spawn(test, 3)
g2 = gevent.spawn(test, 3)
g3 = gevent.spawn(test, 3)
g1.join()
g2.join()
g3.join()运行结果:
<Greenlet at 0x10a6eea60: test(3)> 0
<Greenlet at 0x10a6eea60: test(3)> 1
<Greenlet at 0x10a6eea60: test(3)> 2
<Greenlet at 0x10a6eed58: test(3)> 0
<Greenlet at 0x10a6eed58: test(3)> 1
<Greenlet at 0x10a6eed58: test(3)> 2
<Greenlet at 0x10a6eedf0: test(3)> 0
<Greenlet at 0x10a6eedf0: test(3)> 1
<Greenlet at 0x10a6eedf0: test(3)> 2可以看到3个greenlet是依次运行而不是交替运行。要让greenlet交替运行,可以通过gevent.sleep()交出控制权:
def test(n):
for i in range(n):
print(gevent.getcurrent(), i)
gevent.sleep(1)运行结果:
<Greenlet at 0x10382da60: test(3)> 0
<Greenlet at 0x10382dd58: test(3)> 0
<Greenlet at 0x10382ddf0: test(3)> 0
<Greenlet at 0x10382da60: test(3)> 1
<Greenlet at 0x10382dd58: test(3)> 1
<Greenlet at 0x10382ddf0: test(3)> 1
<Greenlet at 0x10382da60: test(3)> 2
<Greenlet at 0x10382dd58: test(3)> 2
<Greenlet at 0x10382ddf0: test(3)> 2当然在实际的代码里,我们不会用gevent.sleep()去切换协程,而是在执行到IO操作时gevent会自动完成,所以gevent需要将Python自带的一些标准库的运行方式由阻塞式调用变为协作式运行。这一过程在启动时通过monkey patch完成:
#-*- coding:utf8 -*-
from gevent import monkey; monkey.patch_all()
from urllib import request
import gevent
def test(url):
print('Get: %s' % url)
response = request.urlopen(url)
content = response.read().decode('utf8')
print('%d bytes received from %s.' % (len(content), url))
if __name__ == '__main__':
gevent.joinall([
gevent.spawn(test, 'http://httpbin.org/ip'),
gevent.spawn(test, 'http://httpbin.org/uuid'),
gevent.spawn(test, 'http://httpbin.org/user-agent')
])运行结果:
Get: http://httpbin.org/ip
Get: http://httpbin.org/uuid
Get: http://httpbin.org/user-agent
53 bytes received from http://httpbin.org/uuid.
40 bytes received from http://httpbin.org/user-agent.
31 bytes received from http://httpbin.org/ip.从结果看,3个网络操作是并发执行的,而且结束顺序不同,但只有一个线程。
总结
至此Python中的协程就介绍完毕了,示例程序中都是以sleep代表异步IO的,在实际项目中可以使用协程异步的读写网络、读写文件、渲染界面等,而在等待协程完成的同时,CPU还可以进行其他的计算,协程的作用正在于此。那么协程和多线程的差异在哪里呢?多线程的切换需要靠操作系统来完成,当线程越来越多时切换的成本会很高,而协程是在一个线程内切换的,切换过程由我们自己控制,因此开销小很多,这就是协程和多线程的根本差异。

