����Ŀ¼
�������(��)
1. ���̺��߳�
�����˽��½��̺��̡߳�
���:
-
һ������,������һ������,һ��������������һ������,�����ǹ����ڹ�����
-
һ������,������һ������,һ��������������һ���߳�,�������߳��ڹ�����
�������еĴ���ʾ������һ������,��ʹ��python xx.py ����ʱ,�ڲ��ʹ���һ������(������),�ڽ����д�����һ���߳�(���߳�),���߳��������д��롣
���̺��߳�:
�߳�,�Ǽ�����п��Ա�cpu���ȵ���С��Ԫ(�����ڹ���)��
����,�Ǽ������Դ�������С��Ԫ(����Ϊ�߳��ṩ��Դ)��
һ�������п����ж���߳�,ͬһ�������е��߳̿��Թ����˽����е���Դ��
��ǰ���ǿ����ij��������е���Ϊ��ֻ��ͨ�����е���ʽ����,�Ŷ���һִ��,ǰ��δ���,����Ҳ������������:
import time
import requests
url_list = [
("����F4ģ����.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"),
("���ؿ���.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"),
("��˹mvp.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg")
]
print(time.time())
for file_name, url in url_list:
res = requests.get(url)
with open(file_name, mode='wb') as f:
f.write(res.content)
print(file_name, time.time())
���ͨ�� ���� �� �߳� �����Խ� ���� �ij����Ϊ����,��������ʾ����˵����ͬʱ����������Ƶ,�����̵ܶ�ʱ���ھͿ���������ɡ�
1.1 ���߳�
- һ������,����һ������,��������д��� 3������,���д�������
- һ������,����һ������,��������д��� 3���߳�,���д�������
���ڶ��̶߳���������ʾ�������Ż�:
import time
import requests
import threading
url_list = [
("����F4ģ����.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"),
("���ؿ���.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"),
("��˹mvp.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg")
]
def task(file_name, video_url):
res = requests.get(video_url)
with open(file_name, mode='wb') as f:
f.write(res.content)
print(time.time())
for name, url in url_list:
# �����߳�,��ÿ���̶߳�ȥִ��task����(������ͬ)
t = threading.Thread(target=task, args=(name, url))
t.start()
1.2 �����
���ڶ���̶���������ʾ�������Ż�:
- һ������,���� ��������,ÿ������ һ������(��3��),���д�������
- һ������,���� ��������,ÿ������ һ���߳�(��3��),���д�������
import time
import requests
import multiprocessing
# ���̴���֮��,�ڽ����л��ᴴ��һ���̡߳�
# t = multiprocessing.Process(target=������, args=(name, url))
# t.start()
url_list = [
("����F4ģ����.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"),
("���ؿ���.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"),
("��˹mvp.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg")
]
def task(file_name, video_url):
res = requests.get(video_url)
with open(file_name, mode='wb') as f:
f.write(res.content)
print(time.time())
if __name__ == '__main__':
print(time.time())
for name, url in url_list:
t = multiprocessing.Process(target=task, args=(name, url))
t.start()
��������,��һᷢ�� ����� �Ŀ����� ���߳� �Ŀ��������Dz���ʹ�ö��߳�Ҫ�ȶ���̸���ѽ?
������,�������������һ��Python���õ�GIL����֪ʶ,Ȼ���ٸ��� ���� �� �߳� ���Ե��ص��ܽ�����ʺ�Ӧ�ó�����
1.3 GIL��
GIL, ȫ�ֽ�������(Global Interpreter Lock),��CPython����������һ������,��һ��������ͬһ��ʱ��ֻ����һ���߳̿��Ա�CPU���á�
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-yhOp7ceA-1649035741120)(assets/image-20210218184651385.png)]](https://img-blog.csdnimg.cn/f9a60f189579423eba99c8a6c88599ab.png)
������������� ������Ķ������,��CPUͬʱ����һЩ����,�ʺ��ö���̿���(��ʹ��Դ������)��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-0mN3uOQQ-1649035741121)(assets/image-20210218185849637.png)]](https://img-blog.csdnimg.cn/143a9fba92224f65bac019358bcb01b9.png)
����������� ������Ķ������,�ʺ��ö��߳̿�����
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-KzQn1Fiy-1649035741122)(assets/image-20210218185953326.png)]](https://img-blog.csdnimg.cn/f6af2c25ce35435fba96102580ea2ac5.png)
�����ij�����,���������Ҫʹ��CPU�������,IO��������Ҫ����CPU�Ķ������,����,������һ�仰:
- �����ܼ���,�ö����,����:���������ݼ��㡾�ۼӼ���ʾ������
- IO�ܼ���,�ö��߳�,����:�ļ���д���������ݴ��䡾���ض�����Ƶʾ������
�ۼӼ���ʾ��(�����ܼ���):
-
�����
import time start = time.time() result = 0 for i in range(100000000): result += i print(result) end = time.time() print("��ʱ:", end - start) # ��ʱ: 9.522780179977417 -
����̴���
import time import multiprocessing def task(start, end, queue): result = 0 for i in range(start, end): result += i queue.put(result) if __name__ == '__main__': queue = multiprocessing.Queue() start_time = time.time() p1 = multiprocessing.Process(target=task, args=(0, 50000000, queue)) p1.start() p2 = multiprocessing.Process(target=task, args=(50000000, 100000000, queue)) p2.start() v1 = queue.get(block=True) #���� v2 = queue.get(block=True) #���� print(v1 + v2) end_time = time.time() print("��ʱ:", end_time - start_time) # ��ʱ: 2.6232550144195557
��Ȼ,�ڳ����� ���߳� �� ����� �ǿ��Խ��ʹ��,����:����2������(������CPU������ͬ),ÿ�������д���3���̡߳�
import multiprocessing
import threading
def thread_task():
pass
def task(start, end):
t1 = threading.Thread(target=thread_task)
t1.start()
t2 = threading.Thread(target=thread_task)
t2.start()
t3 = threading.Thread(target=thread_task)
t3.start()
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task, args=(0, 50000000))
p1.start()
p2 = multiprocessing.Process(target=task, args=(50000000, 100000000))
p2.start()
2. ���߳̿���
import threading
def task(arg):
pass
# ����һ��Thread����(�߳�),����װ�̱߳�CPU����ʱӦ��ִ�е��������ز�����
t = threading.Thread(target=task,args=('xxx',))
# �߳�������(�ȴ�CPU����),�����������ִ�С�
t.start()
print("����ִ��...") # ���߳�ִ�������д���,������(�ȴ����߳�)
�̵߳ij�������:
-
t.start(),��ǰ�߳�������(�ȴ�CPU����,����ʱ������CPU������)��import threading loop = 10000000 number = 0 def _add(count): global number for i in range(count): number += 1 t = threading.Thread(target=_add,args=(loop,)) t.start() print(number) -
t.join(),�ȴ���ǰ�̵߳�����ִ����Ϻ������¼���ִ�С�import threading number = 0 def _add(): global number for i in range(10000000): number += 1 t = threading.Thread(target=_add) t.start() t.join() # ���̵߳ȴ���... print(number)import threading number = 0 def _add(): global number for i in range(10000000): number += 1 def _sub(): global number for i in range(10000000): number -= 1 t1 = threading.Thread(target=_add) t2 = threading.Thread(target=_sub) t1.start() t1.join() # t1�߳�ִ�����,�ż��������� t2.start() t2.join() # t2�߳�ִ�����,�ż��������� print(number)import threading loop = 10000000 number = 0 def _add(count): global number for i in range(count): number += 1 def _sub(count): global number for i in range(count): number -= 1 t1 = threading.Thread(target=_add, args=(loop,)) t2 = threading.Thread(target=_sub, args=(loop,)) t1.start() t2.start() t1.join() # t1�߳�ִ�����,�ż��������� t2.join() # t2�߳�ִ�����,�ż��������� print(number) -
t.setDaemon(����ֵ),�ػ��߳�(�������start֮ǰ)t.setDaemon(True),����Ϊ�ػ��߳�,���߳�ִ����Ϻ�,���߳�Ҳ�Զ��رա�t.setDaemon(False),����Ϊ���ػ��߳�,���̵߳ȴ����߳�,���߳�ִ����Ϻ�,���̲߳Ž�����(Ĭ��)
import threading import time def task(arg): time.sleep(5) print('����') t = threading.Thread(target=task, args=(11,)) t.setDaemon(True) # True/False t.start() print('END') -
�߳����Ƶ����úͻ�ȡ
import threading def task(arg): # ��ȡ��ǰִ�д˴�����߳� name = threading.current_thread().getName() print(name) for i in range(10): t = threading.Thread(target=task, args=(11,)) t.setName('��ħ-{}'.format(i)) t.start() -
�Զ����߳���,ֱ�ӽ��߳���Ҫ������д��run�����С�
import threading class MyThread(threading.Thread): def run(self): print('ִ�д��߳�', self._args) t = MyThread(args=(100,)) t.start()import requests import threading class DouYinThread(threading.Thread): def run(self): file_name, video_url = self._args res = requests.get(video_url) with open(file_name, mode='wb') as f: f.write(res.content) url_list = [ ("����F4ģ����.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"), ("���ؿ���.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"), ("��˹mvp.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg") ] for item in url_list: t = DouYinThread(args=(item[0], item[1])) t.start()
3. �̰߳�ȫ
һ�������п����ж���߳�,���̹߳������н����е���Դ��
����߳�ͬʱȥ����һ��"����",������������ݻ��ҵ����,����:
-
ʾ��1
import threading loop = 10000000 number = 0 def _add(count): global number for i in range(count): number += 1 def _sub(count): global number for i in range(count): number -= 1 t1 = threading.Thread(target=_add, args=(loop,)) t2 = threading.Thread(target=_sub, args=(loop,)) t1.start() t2.start() t1.join() # t1�߳�ִ�����,�ż��������� t2.join() # t2�߳�ִ�����,�ż��������� print(number)import threading lock_object = threading.RLock() loop = 10000000 number = 0 def _add(count): lock_object.acquire() # ���� global number for i in range(count): number += 1 lock_object.release() # �ͷ��� def _sub(count): lock_object.acquire() # ������(�ȴ�) global number for i in range(count): number -= 1 lock_object.release() # �ͷ��� t1 = threading.Thread(target=_add, args=(loop,)) t2 = threading.Thread(target=_sub, args=(loop,)) t1.start() t2.start() t1.join() # t1�߳�ִ�����,�ż��������� t2.join() # t2�߳�ִ�����,�ż��������� print(number) -
ʾ��2:
import threading num = 0 def task(): global num for i in range(1000000): num += 1 print(num) for i in range(2): t = threading.Thread(target=task) t.start()import threading num = 0 lock_object = threading.RLock() def task(): print("��ʼ") lock_object.acquire() # ��1���ִ���߳̽��벢����,�����߳̾���Ҫ�ٴ˵ȴ��� global num for i in range(1000000): num += 1 lock_object.release() # �̳߳�ȥ,�����,�����߳̾Ϳ��Խ��벢ִ���� print(num) for i in range(2): t = threading.Thread(target=task) t.start()import threading num = 0 lock_object = threading.RLock() def task(): print("��ʼ") with lock_object: # ���������Ĺ���,�ڲ��Զ�ִ�� acquire �� release global num for i in range(1000000): num += 1 print(num) for i in range(2): t = threading.Thread(target=task) t.start()
�ڿ����Ĺ�����Ҫע����Щ����Ĭ�϶��� �̰߳�ȫ��(�ڲ����������Ļ���),������ʹ�õ�ʱ������ͨ�����ٴ���,����:
import threading
data_list = []
lock_object = threading.RLock()
def task():
print("��ʼ")
for i in range(1000000):
data_list.append(i)
print(len(data_list))
for i in range(2):
t = threading.Thread(target=task)
t.start()

����,Ҫ��ע�⿴һЩ�����ĵ����Ƿ�����̰߳�ȫ��
4. �߳���
�ڳ����������Ҫ�Լ��ֶ�����,һ��������:Lock �� RLock��
-
Lock,ͬ������
import threading num = 0 lock_object = threading.Lock() def task(): print("��ʼ") lock_object.acquire() # ��1���ִ���߳̽��벢����,�����߳̾���Ҫ�ٴ˵ȴ��� global num for i in range(1000000): num += 1 lock_object.release() # �̳߳�ȥ,�����,�����߳̾Ϳ��Խ��벢ִ���� print(num) for i in range(2): t = threading.Thread(target=task) t.start() -
RLock,�ݹ�����
import threading num = 0 lock_object = threading.RLock() def task(): print("��ʼ") lock_object.acquire() # ��1���ִ���߳̽��벢����,�����߳̾���Ҫ�ٴ˵ȴ��� global num for i in range(1000000): num += 1 lock_object.release() # �̳߳�ȥ,�����,�����߳̾Ϳ��Խ��벢ִ���� print(num) for i in range(2): t = threading.Thread(target=task) t.start()
RLock֧�ֶ���������Ͷ���ͷ�;Lock��֧�֡�����:
import threading
import time
lock_object = threading.RLock()
def task():
print("��ʼ")
lock_object.acquire()
lock_object.acquire()
print(123)
lock_object.release()
lock_object.release()
for i in range(3):
t = threading.Thread(target=task)
t.start()
import threading
lock = threading.RLock()
# ����ԱA������һ������,�������Ա����������ߵ���,�ڲ���Ҫ��������֤���ݰ�ȫ��
def func():
with lock:
pass
# ����ԱB������һ������,����ֱ�ӵ������������
def run():
print("��������")
func() # ���ó���ԱAд��func����,�ڲ��õ�������
print("��������")
# ����ԱC������һ������,�Լ���Ҫ����,ͬʱҲ��Ҫ����func������
def process():
with lock:
print("��������")
func() # ----------------> ��ʱ�ͻ���ֶ���������,ֻ��RLock֧��(Lock��֧��)��
print("��������")
5.����
����,���ھ�����Դ�������ڱ˴�ͨ�Ŷ���ɵ�һ������������
import threading
num = 0
lock_object = threading.Lock()
def task():
print("��ʼ")
lock_object.acquire() # ��1���ִ���߳̽��벢����,�����߳̾���Ҫ�ٴ˵ȴ���
lock_object.acquire() # ��1���ִ���߳̽��벢����,�����߳̾���Ҫ�ٴ˵ȴ���
global num
for i in range(1000000):
num += 1
lock_object.release() # �̳߳�ȥ,�����,�����߳̾Ϳ��Խ��벢ִ����
lock_object.release() # �̳߳�ȥ,�����,�����߳̾Ϳ��Խ��벢ִ����
print(num)
for i in range(2):
t = threading.Thread(target=task)
t.start()
import threading
import time
lock_1 = threading.Lock()
lock_2 = threading.Lock()
def task1():
lock_1.acquire()
time.sleep(1)
lock_2.acquire()
print(11)
lock_2.release()
print(111)
lock_1.release()
print(1111)
def task2():
lock_2.acquire()
time.sleep(1)
lock_1.acquire()
print(22)
lock_1.release()
print(222)
lock_2.release()
print(2222)
t1 = threading.Thread(target=task1)
t1.start()
t2 = threading.Thread(target=task2)
t2.start()
6.�̳߳�
Python3�йٷ�����ʽ�ṩ�̳߳ء�
�̲߳��ǿ���Խ��Խ��,���Ķ��˿��ܻᵼ��ϵͳ�����ܸ�����,����:���µĴ����Dz��Ƽ�����Ŀ�����б�д��
������:�����ƵĴ����̡߳�
import threading
def task(video_url):
pass
url_list = ["www.xxxx-{}.com".format(i) for i in range(30000)]
for url in url_list:
t = threading.Thread(target=task, args=(url,))
t.start()
# ����ÿ�ζ�����һ���߳�ȥ����,���������̫��,�߳̾ͻ��ر��,����Ч�ʷ��������ˡ�
����:ʹ���̳߳�
ʾ��1:
import time
from concurrent.futures import ThreadPoolExecutor
# pool = ThreadPoolExecutor(100)
# pool.submit(������,����1,����2,����...)
def task(video_url,num):
print("��ʼִ������", video_url)
time.sleep(5)
# �����̳߳�,���ά��10���̡߳�
pool = ThreadPoolExecutor(10)
url_list = ["www.xxxx-{}.com".format(i) for i in range(300)]
for url in url_list:
# ���̳߳����ύһ������,�̳߳�������п����߳�,�����һ���߳�ȥִ��,ִ����Ϻ��ٽ��߳̽������̳߳�;���û�п����߳�,��ȴ���
pool.submit(task, url,2)
print("END")
ʾ��2:�ȴ��̳߳ص�����ִ����ϡ�
import time
from concurrent.futures import ThreadPoolExecutor
def task(video_url):
print("��ʼִ������", video_url)
time.sleep(5)
# �����̳߳�,���ά��10���̡߳�
pool = ThreadPoolExecutor(10)
url_list = ["www.xxxx-{}.com".format(i) for i in range(300)]
for url in url_list:
# ���̳߳����ύһ������,�̳߳�������п����߳�,�����һ���߳�ȥִ��,ִ����Ϻ��ٽ��߳̽������̳߳�;���û�п����߳�,��ȴ���
pool.submit(task, url)
print("ִ����...")
pool.shutdown(True) # �ȴ��̳߳��е�����ִ����Ϻ�,�ڼ���ִ��
print('����������')
ʾ��3:����ִ��������,�ٸɵ������¡�
import time
import random
from concurrent.futures import ThreadPoolExecutor, Future
def task(video_url):
print("��ʼִ������", video_url)
time.sleep(2)
return random.randint(0, 10)
def done(response):
print("����ִ�к�ķ���ֵ", response.result())
# �����̳߳�,���ά��10���̡߳�
pool = ThreadPoolExecutor(10)
url_list = ["www.xxxx-{}.com".format(i) for i in range(15)]
for url in url_list:
# ���̳߳����ύһ������,�̳߳�������п����߳�,�����һ���߳�ȥִ��,ִ����Ϻ��ٽ��߳̽������̳߳�;���û�п����߳�,��ȴ���
future = pool.submit(task, url)
future.add_done_callback(done) # �������߳�ִ��
# �������ֹ�,����:taskר������,doneר�Ž����ص�����д�뱾���ļ���
ʾ��4:����ͳһ��ȡ�����
import time
import random
from concurrent.futures import ThreadPoolExecutor,Future
def task(video_url):
print("��ʼִ������", video_url)
time.sleep(2)
return random.randint(0, 10)
# �����̳߳�,���ά��10���̡߳�
pool = ThreadPoolExecutor(10)
future_list = []
url_list = ["www.xxxx-{}.com".format(i) for i in range(15)]
for url in url_list:
# ���̳߳����ύһ������,�̳߳�������п����߳�,�����һ���߳�ȥִ��,ִ����Ϻ��ٽ��߳̽������̳߳�;���û�п����߳�,��ȴ���
future = pool.submit(task, url)
future_list.append(future)
pool.shutdown(True)
for fu in future_list:
print(fu.result())
����:�����̳߳����ض���ͼƬ��
����һ��mv.csv�ļ�
26044585,Hush,https://hbimg.huabanimg.com/51d46dc32abe7ac7f83b94c67bb88cacc46869954f478-aP4Q3V
19318369,��ʮһ,https://hbimg.huabanimg.com/703fdb063bdc37b11033ef794f9b3a7adfa01fd21a6d1-wTFbnO
15529690,Law344,https://hbimg.huabanimg.com/b438d8c61ed2abf50ca94e00f257ca7a223e3b364b471-xrzoQd
18311394,Jennah��,https://hbimg.huabanimg.com/4edba1ed6a71797f52355aa1de5af961b85bf824cb71-px1nZz
18009711,���尮����,https://hbimg.huabanimg.com/03331ef39b5c7687f5cc47dbcbafd974403c962ae88ce-Co8AUI
30574436,������~,https://hbimg.huabanimg.com/2f5b657edb9497ff8c41132e18000edb082d158c2404-8rYHbw
17740339,��,https://hbimg.huabanimg.com/dbc6fd49f1915545cc42c1a1492a418dbaebd2c21bb9-9aDqgl
18741964,ͩĩtonmo,https://hbimg.huabanimg.com/b60cee303f62aaa592292f45a1ed8d5be9873b2ed5c-gAJehO
30535005,TANGZHIQI,https://hbimg.huabanimg.com/bbd08ee168d54665bf9b07899a5c4a4d6bc1eb8af77a4-8Gz3K1
31078743,�������,https://hbimg.huabanimg.com/c46fbc3c9a01db37b8e786cbd7174bbd475e4cda220f4-F1u7MX
25519376,�߳ߴ�,https://hbimg.huabanimg.com/ee29ee198efb98f970e3dc2b24c40d89bfb6f911126b6-KGvKes
21113978,C-CLong,https://hbimg.huabanimg.com/7fa6b2a0d570e67246b34840a87d57c16a875dba9100-SXsSeY
24674102,szaa,https://hbimg.huabanimg.com/0716687b0df93e8c3a8e0925b6d2e4135449cd27597c4-gWdv24
30508507,����С�һ�,https://hbimg.huabanimg.com/4eafdbfa21b2f300a7becd8863f948e5e92ef789b5a5-1ozTKq
12593664,yokozen,https://hbimg.huabanimg.com/cd07bbaf052b752ed5c287602404ea719d7dd8161321b-cJtHss
16899164,һ���,https://hbimg.huabanimg.com/0940b557b28892658c3bcaf52f5ba8dc8402100e130b2-G966Uz
847937,����My�°�er��,https://hbimg.huabanimg.com/e2d6bb5bc8498c6f607492a8f96164aa2366b104e7a-kWaH68
31010628,����������,https://hbimg.huabanimg.com/c4fb6718907a22f202e8dd14d52f0c369685e59cfea7-82FdsK
13438168,����������,https://hbimg.huabanimg.com/1edae3ce6fe0f6e95b67b4f8b57c4cebf19c501b397e-BXwiW6
28593155,Դ����,https://hbimg.huabanimg.com/626cfd89ca4c10e6f875f3dfe1005331e4c0fd7fd429-9SeJeQ
28201821,�ϻ�ߺ�,https://hbimg.huabanimg.com/f59d4780531aa1892b80e0ec94d4ec78dcba08ff18c416-769X6a
28255146,����AAA,https://hbimg.huabanimg.com/3c034c520594e38353a039d7e7a5fd5e74fb53eb1086-KnpLaL
30537613,��?,https://hbimg.huabanimg.com/efd81d22c1b1a2de77a0e0d8e853282b83b6bbc590fd-y3d4GJ
22665880,�պ�ػ�,https://hbimg.huabanimg.com/69f0f959979a4fada9e9e55f565989544be88164d2b-INWbaF
16748980,keer521521,https://hbimg.huabanimg.com/654953460733026a7ef6e101404055627ad51784a95c-B6OFs4
30536510,�����ǡ�,https://hbimg.huabanimg.com/61cfffca6b2507bf51a507e8319d68a8b8c3a96968f-6IvMSk
30986577,�ճɱ�����,https://hbimg.huabanimg.com/c381ecc43d6c69758a86a30ebf72976906ae6c53291f9-9zroHF
26409800,CsysADk7,https://hbimg.huabanimg.com/bf1d22092c2070d68ade012c588f2e410caaab1f58051-ahlgLm
30469116,18��ȫ��,https://hbimg.huabanimg.com/654953460733026a7ef6e101404055627ad51784a95c-B6OFs4
17473505,���λ�,https://hbimg.huabanimg.com/0e38d810e5a24f91ebb251fd3aaaed8bb37655b14844c-pgNJBP
19165177,��˼��b?,https://hbimg.huabanimg.com/4815ea0e4905d0f3bb82a654b481811dadbfe5ce2673-vMVr0B
16059616,������ؼ,https://hbimg.huabanimg.com/8760a2b08d87e6ed4b7a9715b1a668176dbf84fec5b-jx14tZ
30734152,sCWVkJDG,https://hbimg.huabanimg.com/f31a5305d1b8717bbfb897723f267d316e58e7b7dc40-GD3e22
24019677,���ޱ���,https://hbimg.huabanimg.com/6fdfa9834abe362e978b517275b06e7f0d5926aa650-N1xCXE
16670283,Y-������,https://hbimg.huabanimg.com/a3bbb0045b536fc27a6d2effa64a0d43f9f5193c177f-I2vHaI
21512483,��ķ2,https://hbimg.huabanimg.com/98cc50a61a7cc9b49a8af754ffb26bd15764a82f1133-AkiU7D
16441049,������,https://hbimg.huabanimg.com/ae8a70cd85aff3a8587ff6578d5cf7620f3691df13e46-lmrIi9
24795603,?????v,https://hbimg.huabanimg.com/a7183cc3a933aa129d7b3230bf1378fd8f5857846cc5-3tDtx3
29819152,����ʿ���,https://hbimg.huabanimg.com/ca4ecb573bf1ff0415c7a873d64470dedc465ea1213c6-RAkArS
19101282,���¸�?,https://hbimg.huabanimg.com/ab6d04ebaff3176e3570139a65155856871241b58bc6-Qklj2E
28337572,�������ɢ,https://hbimg.huabanimg.com/117ad8b6eeda57a562ac6ab2861111a793ca3d1d5543-SjWlk2
17342758,����instant,https://hbimg.huabanimg.com/72b5f9042ec297ae57b83431123bc1c066cca90fa23-3MoJNj
18483372,BeauȾ,https://hbimg.huabanimg.com/077115cb622b1ff3907ec6932e1b575393d5aae720487-d1cdT9
22127102,�Ի���С����,https://hbimg.huabanimg.com/6c3cbf9f27e17898083186fc51985e43269018cc1e1df-QfOIBG
13802024,LoveHsu,https://hbimg.huabanimg.com/f720a15f8b49b86a7c1ee4951263a8dbecfe3e43d2d-GPEauV
22558931,�Թ�϶ؼ�滨�ᤦ,https://hbimg.huabanimg.com/e49e1341dfe5144da5c71bd15f1052ef07ba7a0e1296b-jfyfDJ
11762339,cojoy,https://hbimg.huabanimg.com/5b27f876d5d391e7c4889bc5e8ba214419eb72b56822-83gYmB
30711623,ѩ��ѧ��ѽ,https://hbimg.huabanimg.com/2c288a1535048b05537ba523b3fc9eacc1e81273212d1-nr8M4t
18906718,������,https://hbimg.huabanimg.com/7b02ad5e01bd8c0a29817e362814666a7800831c154a6-AvBDaG
31037856,���������,https://hbimg.huabanimg.com/654953460733026a7ef6e101404055627ad51784a95c-B6OFs4
26830711,�Ƚ�̷,https://hbimg.huabanimg.com/51547ade3f0aef134e8d268cfd4ad61110925aefec8a-NKPEYX
ʵ��ͼƬ����:
import os
import requests
from concurrent.futures import ThreadPoolExecutor
def download(file_name, image_url):
res = requests.get(
url=image_url,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
)
# ���imagesĿ¼�Ƿ���ڡ�������,��imagesĿ¼
if not os.path.exists("images"):
# ����imagesĿ¼
os.makedirs("images")
file_path = os.path.join("images", file_name)
# 2.��ͼƬ������д�뵽�ļ�
with open(file_path, mode='wb') as img_object:
img_object.write(res.content)
# �����̳߳�,���ά��10���̡߳�
pool = ThreadPoolExecutor(10)
with open("mv.csv", mode='r', encoding='utf-8') as file_object:
for line in file_object:
nid, name, url = line.split(",")
file_name = "{}.png".format(name)
pool.submit(download, file_name, url)
import os
import requests
from concurrent.futures import ThreadPoolExecutor
def download(image_url):
res = requests.get(
url=image_url,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
)
return res
def outer(file_name):
def save(response):
res = response.result()
# д�뱾��
# # ���imagesĿ¼�Ƿ����?������,��imagesĿ¼
if not os.path.exists("images"):
# ����imagesĿ¼
os.makedirs("images")
file_path = os.path.join("images", file_name)
# # 2.��ͼƬ������д�뵽�ļ�
with open(file_path, mode='wb') as img_object:
img_object.write(res.content)
return save
# �����̳߳�,���ά��10���̡߳�
pool = ThreadPoolExecutor(10)
with open("mv.csv", mode='r', encoding='utf-8') as file_object:
for line in file_object:
nid, name, url = line.split(",")
file_name = "{}.png".format(name)
fur = pool.submit(download, url)
fur.add_done_callback(outer(file_name))
�������(��)
1. ����̿���
�����Ǽ��������Դ�������С��Ԫ;
һ�������п����ж���߳�,ͬһ�������е��̹߳�����Դ;
���������֮����������롣
Python��ͨ������̿�������CPU�Ķ������,�����ܼ��Ͳ��������ڶ���̡�
1.1 ���̽���
import multiprocessing
def task():
pass
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task)
p1.start()
from multiprocessing import Process
def task(arg):
pass
def run():
p = multiprocessing.Process(target=task, args=('xxx',))
p.start()
if __name__ == '__main__':
run()
������Python�л���multiprocessiongģ������Ľ���:
Depending on the platform, multiprocessing supports three ways to start a process. These start methods are
fork,��������������������Դ����֧���ļ�����/�߳����ȴ��Ρ���unix��������λ�ÿ�ʼ�����졿
The parent process uses
os.fork()to fork the Python interpreter. The child process, when it begins, is effectively identical to the parent process. All resources of the parent are inherited by the child process. Note that safely forking a multithreaded process is problematic.Available on Unix only. The default on Unix.spawn,��run�������ر���Դ������֧���ļ�����/�߳����ȴ��Ρ���unix��win����main����鿪ʼ��������
The parent process starts a fresh python interpreter process. The child process will only inherit those resources necessary to run the process object��s
run()method. In particular, unnecessary file descriptors and handles from the parent process will not be inherited. Starting a process using this method is rather slow compared to using fork or forkserver.Available on Unix and Windows. The default on Windows and macOS.forkserver,��run�������ر���Դ������֧���ļ�����/�߳����ȴ��Ρ�������unix����main����鿪ʼ��
When the program starts and selects the forkserver start method, a server process is started. From then on, whenever a new process is needed, the parent process connects to the server and requests that it fork a new process. The fork server process is single threaded so it is safe for it to use
os.fork(). No unnecessary resources are inherited.Available on Unix platforms which support passing file descriptors over Unix pipes.
import multiprocessing
multiprocessing.set_start_method("spawn")
Changed in version 3.8: On macOS, the spawn start method is now the default. The fork start method should be considered unsafe as it can lead to crashes of the subprocess. See bpo-33725.
Changed in version 3.4: spawn added on all unix platforms, and forkserver added for some unix platforms. Child processes no longer inherit all of the parents inheritable handles on Windows.
On Unix using the spawn or forkserver start methods will also start a resource tracker process which tracks the unlinked named system resources (such as named semaphores or SharedMemory objects) created by processes of the program. When all processes have exited the resource tracker unlinks any remaining tracked object. Usually there should be none, but if a process was killed by a signal there may be some ��leaked�� resources. (Neither leaked semaphores nor shared memory segments will be automatically unlinked until the next reboot. This is problematic for both objects because the system allows only a limited number of named semaphores, and shared memory segments occupy some space in the main memory.)
�ٷ��ĵ�:https://docs.python.org/3/library/multiprocessing.html
-
ʾ��1
import multiprocessing import time """ def task(): print(name) name.append(123) if __name__ == '__main__': multiprocessing.set_start_method("fork") # fork��spawn��forkserver name = [] p1 = multiprocessing.Process(target=task) p1.start() time.sleep(2) print(name) # [] """ """ def task(): print(name) # [123] if __name__ == '__main__': multiprocessing.set_start_method("fork") # fork��spawn��forkserver name = [] name.append(123) p1 = multiprocessing.Process(target=task) p1.start() """ """ def task(): print(name) # [] if __name__ == '__main__': multiprocessing.set_start_method("fork") # fork��spawn��forkserver name = [] p1 = multiprocessing.Process(target=task) p1.start() name.append(123) """ -
ʾ��2
import multiprocessing def task(): print(name) print(file_object) if __name__ == '__main__': multiprocessing.set_start_method("fork") # fork��spawn��forkserver name = [] file_object = open('x1.txt', mode='a+', encoding='utf-8') p1 = multiprocessing.Process(target=task) p1.start()
����:
import multiprocessing
def task():
print(name)
file_object.write("hello\n")
file_object.flush()
if __name__ == '__main__':
multiprocessing.set_start_method("fork")
name = []
file_object = open('x1.txt', mode='a+', encoding='utf-8')
file_object.write("goodnight\n")
p1 = multiprocessing.Process(target=task)
p1.start()
import multiprocessing
def task():
print(name)
file_object.write("hello\n")
file_object.flush()
if __name__ == '__main__':
multiprocessing.set_start_method("fork")
name = []
file_object = open('x1.txt', mode='a+', encoding='utf-8')
file_object.write("goodnight\n")
file_object.flush()
p1 = multiprocessing.Process(target=task)
p1.start()
import multiprocessing
import threading
import time
def func():
print("����")
with lock:
print(666)
time.sleep(1)
def task():
# ��������Ҳ�DZ������ߵ�״̬
# ��˭��������? ���ӽ����е����߳���������
for i in range(10):
t = threading.Thread(target=func)
t.start()
time.sleep(2)
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method("fork")
name = []
lock = threading.RLock()
lock.acquire()
# print(lock)
# lock.acquire() # ������
# print(lock)
# lock.release()
# print(lock)
# lock.acquire() # ������
# print(lock)
p1 = multiprocessing.Process(target=task)
p1.start()
1.2 ��������
���̵ij�������:
-
p.start(),��ǰ����������,�ȴ���CPU����(������Ԫ��ʵ�ǽ����е��߳�)�� -
p.join(),�ȴ���ǰ���̵�����ִ����Ϻ������¼���ִ�С�import time from multiprocessing import Process def task(arg): time.sleep(2) print("ִ����...") if __name__ == '__main__': multiprocessing.set_start_method("spawn") # windowsĬ��spawn p = Process(target=task, args=('xxx',)) p.start() p.join() print("����ִ��...") -
p.daemon = ����ֵ,�ػ�����(�������start֮ǰ) -
p.daemon =True,����Ϊ�ػ�����,������ִ����Ϻ�,�ӽ���Ҳ�Զ��رա� -
p.daemon =False,����Ϊ���ػ�����,�����̵ȴ��ӽ���,�ӽ���ִ����Ϻ�,�����̲Ž�����
import time
from multiprocessing import Process
def task(arg):
time.sleep(2)
print("ִ����...")
if __name__ == '__main__':
multiprocessing.set_start_method("spawn") # windowsĬ��spawn
p = Process(target=task, args=('xxx',))
p.daemon = True
p.start()
print("����ִ��...")
-
���̵����Ƶ����úͻ�ȡ
import os import time import threading import multiprocessing def func(): time.sleep(3) def task(arg): for i in range(10): t = threading.Thread(target=func) t.start() print(os.getpid(), os.getppid()) print("�̸߳���", len(threading.enumerate())) time.sleep(2) print("��ǰ���̵�����:", multiprocessing.current_process().name) if __name__ == '__main__': print(os.getpid()) multiprocessing.set_start_method("spawn") p = multiprocessing.Process(target=task, args=('xxx',)) p.name = "��������" p.start() print("����ִ��...") -
�Զ��������,ֱ�ӽ��߳���Ҫ������д��run�����С�
import multiprocessing class MyProcess(multiprocessing.Process): def run(self): print('ִ�д˽���', self._args) if __name__ == '__main__': multiprocessing.set_start_method("spawn") p = MyProcess(args=('xxx',)) p.start() print("����ִ��...") -
CPU����,����һ�㴴�����ٸ�����?(����CPU�������)��
import multiprocessing count = multiprocessing.cpu_count() print(count) # �鿴����ϵͳCPU����import multiprocessing if __name__ == '__main__': count = multiprocessing.cpu_count() for i in range(count - 1): p = multiprocessing.Process(target=xxxx) p.start()
2.���̼����ݵĹ���
��������Դ�������С��Ԫ,ÿ�������ж�ά���Լ�����������,��������
import multiprocessing
def task(data):
data.append(666)
if __name__ == '__main__':
data_list = []
p = multiprocessing.Process(target=task, args=(data_list,))
p.start()
p.join()
print("������:", data_list) # []
�����Ҫ������֮����й���,����Խ���һЩ����Ķ�����ʵ�֡�
2.1 ����
Shared memory
Data can be stored in a shared memory map using Value or Array. For example, the following code
'c': ctypes.c_char, 'u': ctypes.c_wchar,
'b': ctypes.c_byte, 'B': ctypes.c_ubyte,
'h': ctypes.c_short, 'H': ctypes.c_ushort,
'i': ctypes.c_int, 'I': ctypes.c_uint, (��u��ʾ����)
'l': ctypes.c_long, 'L': ctypes.c_ulong,
'f': ctypes.c_float, 'd': ctypes.c_double
from multiprocessing import Process, Value, Array
def func(n, m1, m2):
n.value = 888
m1.value = 'a'.encode('utf-8')
m2.value = "��"
if __name__ == '__main__':
num = Value('i', 666)
v1 = Value('c')
v2 = Value('u')
p = Process(target=func, args=(num, v1, v2))
p.start()
p.join()
print(num.value) # 888
print(v1.value) # a
print(v2.value) # ��
from multiprocessing import Process, Value, Array
def f(data_array):
data_array[0] = 666
if __name__ == '__main__':
arr = Array('i', [11, 22, 33, 44]) # ����:Ԫ�����ͱ�����int; ֻ������ô�������ݡ�
p = Process(target=f, args=(arr,))
p.start()
p.join()
print(arr[:])
Server process
A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies.
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.append(666)
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list()
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)
2.2 ����
multiprocessing supports two types of communication channel between processes
Queues
The Queue class is a near clone of queue.Queue. For example
import multiprocessing
def task(q):
for i in range(10):
q.put(i)
if __name__ == '__main__':
queue = multiprocessing.Queue()
p = multiprocessing.Process(target=task, args=(queue,))
p.start()
p.join()
print("������")
print(queue.get())
print(queue.get())
print(queue.get())
print(queue.get())
print(queue.get())
Pipes
The Pipe() function returns a pair of connection objects connected by a pipe which by default is duplex (two-way). For example:
import time
import multiprocessing
def task(conn):
time.sleep(1)
conn.send([111, 22, 33, 44])
data = conn.recv() # ����
print("�ӽ��̽���:", data)
time.sleep(2)
if __name__ == '__main__':
parent_conn, child_conn = multiprocessing.Pipe()
p = multiprocessing.Process(target=task, args=(child_conn,))
p.start()
info = parent_conn.recv() # ����
print("�����̽���:", info)
parent_conn.send(666)
��������Python�ڲ��ṩ�Ľ���֮�����ݹ����ͽ����Ļ���,��Ϊ�˽⼴��,����Ŀ�����к���ʹ��,������Ŀ��һ��������������������Դ�Ĺ���,����:MySQL��redis�ȡ�
3. ������
������������ռʽȥ��ijЩ����ʱ��,Ϊ�˷�ֹ����������,����ͨ�������������⡣
import time
from multiprocessing import Process, Value, Array
def func(n, ):
n.value = n.value + 1
if __name__ == '__main__':
num = Value('i', 0)
for i in range(20):
p = Process(target=func, args=(num,))
p.start()
time.sleep(3)
print(num.value)
import time
from multiprocessing import Process, Manager
def f(d, ):
d[1] += 1
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
d[1] = 0
for i in range(20):
p = Process(target=f, args=(d,))
p.start()
time.sleep(3)
print(d)
import time
import multiprocessing
def task():
# �����ļ��б�������ݾ���һ��ֵ:10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("�Ŷ���Ʊ��")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
if __name__ == '__main__':
for i in range(20):
p = multiprocessing.Process(target=task)
p.start()
����Ȼ,������ڲ���ʱ�ͻ������,��ʱ����Ҫ��������:
import time
import multiprocessing
def task(lock):
print("��ʼ")
lock.acquire()
# �����ļ��б�������ݾ���һ��ֵ:10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("�Ŷ���Ʊ��")
time.sleep(0.5)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
lock = multiprocessing.RLock() # ������
for i in range(10):
p = multiprocessing.Process(target=task, args=(lock,))
p.start()
# spawnģʽ,��Ҫ�������
time.sleep(7)
import time
import multiprocessing
import os
def task(lock):
print("��ʼ")
lock.acquire()
# �����ļ��б�������ݾ���һ��ֵ:10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print(os.getpid(), "�Ŷ���Ʊ��")
time.sleep(0.5)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
lock = multiprocessing.RLock()
process_list = []
for i in range(10):
p = multiprocessing.Process(target=task, args=(lock,))
p.start()
process_list.append(p)
# spawnģʽ,��Ҫ�������
for item in process_list:
item.join()
import time
import multiprocessing
def task(lock):
print("��ʼ")
lock.acquire()
# �����ļ��б�������ݾ���һ��ֵ:10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("�Ŷ���Ʊ��")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method('fork')
lock = multiprocessing.RLock()
for i in range(10):
p = multiprocessing.Process(target=task, args=(lock,))
p.start()
4. ���̳�
import time
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
def task(num):
print("ִ��", num)
time.sleep(2)
if __name__ == '__main__':
# ��ģʽ
pool = ProcessPoolExecutor(4)
for i in range(10):
pool.submit(task, i)
print(1)
print(2)
import time
from concurrent.futures import ProcessPoolExecutor
def task(num):
print("ִ��", num)
time.sleep(2)
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
for i in range(10):
pool.submit(task, i)
# �ȴ����̳��е�����ִ����Ϻ�,�ټ�������ִ�С�
pool.shutdown(True)
print(1)
import time
from concurrent.futures import ProcessPoolExecutor
import multiprocessing
def task(num):
print("ִ��", num)
time.sleep(2)
return num
def done(res):
print(multiprocessing.current_process())
time.sleep(1)
print(res.result())
time.sleep(1)
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
for i in range(50):
fur = pool.submit(task, i)
fur.add_done_callback(done) # done�ĵ����������̴���(���̳߳ز�ͬ)
print(multiprocessing.current_process())
pool.shutdown(True)
ע��:����ڽ��̳���Ҫʹ�ý�����,����Ҫ����Manager�е�Lock��RLock��ʵ�֡�
import time
import multiprocessing
from concurrent.futures.process import ProcessPoolExecutor
def task(lock):
print("��ʼ")
# lock.acquire()
# lock.relase()
with lock:
# �����ļ��б�������ݾ���һ��ֵ:10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("�Ŷ���Ʊ��")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
if __name__ == '__main__':
pool = ProcessPoolExecutor()
# lock_object = multiprocessing.RLock() # ����ʹ��
manager = multiprocessing.Manager()
lock_object = manager.RLock() # Lock
for i in range(10):
pool.submit(task, lock_object)
����:����ÿ���û����������
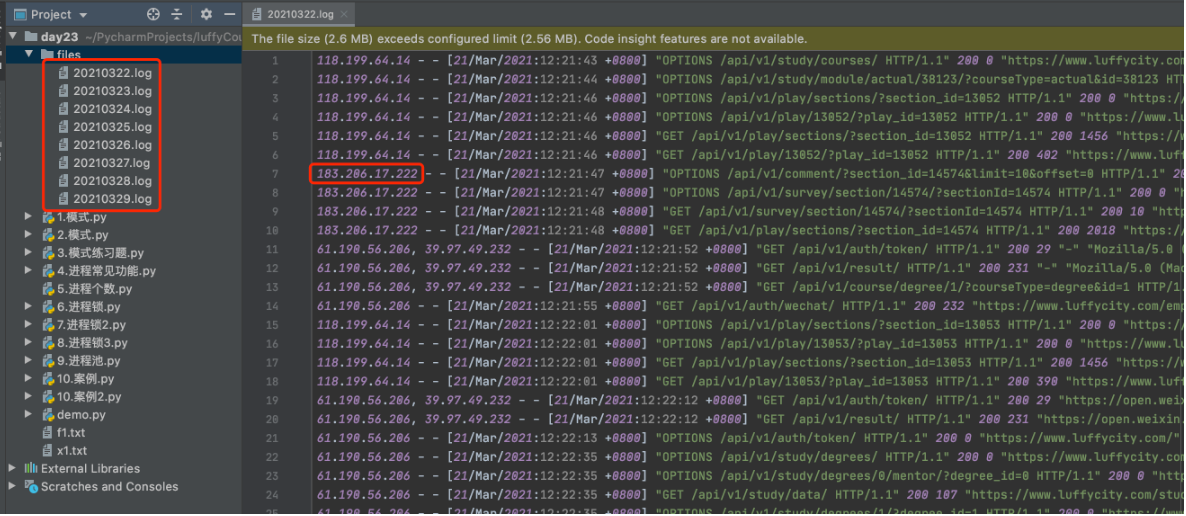
-
ʾ��1
import os import time from concurrent.futures import ProcessPoolExecutor from multiprocessing import Manager def task(file_name, count_dict): ip_set = set() total_count = 0 ip_count = 0 file_path = os.path.join("files", file_name) file_object = open(file_path, mode='r', encoding='utf-8') for line in file_object: if not line.strip(): continue user_ip = line.split(" - -", maxsplit=1)[0].split(",")[0] total_count += 1 if user_ip in ip_set: continue ip_count += 1 ip_set.add(user_ip) count_dict[file_name] = {"total": total_count, 'ip': ip_count} time.sleep(1) def run(): # ����Ŀ¼��ȡ�ļ�����ʼ���ֵ� """ 1.��ȡĿ¼�����е��ļ�,ÿ�����̴���һ���ļ��� """ pool = ProcessPoolExecutor(4) with Manager() as manager: """ count_dict={ "20210322.log":{"total":10000,'ip':800}, } """ count_dict = manager.dict() for file_name in os.listdir("files"): pool.submit(task, file_name, count_dict) pool.shutdown(True) for k, v in count_dict.items(): print(k, v) if __name__ == '__main__': run() -
ʾ��2
import os import time from concurrent.futures import ProcessPoolExecutor def task(file_name): ip_set = set() total_count = 0 ip_count = 0 file_path = os.path.join("files", file_name) file_object = open(file_path, mode='r', encoding='utf-8') for line in file_object: if not line.strip(): continue user_ip = line.split(" - -", maxsplit=1)[0].split(",")[0] total_count += 1 if user_ip in ip_set: continue ip_count += 1 ip_set.add(user_ip) time.sleep(1) return {"total": total_count, 'ip': ip_count} def outer(info, file_name): def done(res, *args, **kwargs): info[file_name] = res.result() return done def run(): # ����Ŀ¼��ȡ�ļ�����ʼ���ֵ� """ 1.��ȡĿ¼�����е��ļ�,ÿ�����̴���һ���ļ��� """ info = {} pool = ProcessPoolExecutor(4) for file_name in os.listdir("files"): fur = pool.submit(task, file_name) fur.add_done_callback( outer(info, file_name) ) # �ص�����:������ pool.shutdown(True) for k, v in info.items(): print(k, v) if __name__ == '__main__': run()
5. ��
��ʱ���˽�Ϊ����
��������ṩ��:�̡߳����� ����ʵ�ֲ������(��ʵ����)��
Э��(Coroutine),�dz���Աͨ������������һ������(����ʵ����)��
Э��Ҳ���Ա���Ϊ�߳�,��һ���û�̬�ڵ��������л�������
�����֮,��ʵ����ͨ��һ���߳�ʵ�ִ������л�ִ��(��������ִ��)��
����:
def func1():
print(1)
...
print(2)
def func2():
print(3)
...
print(4)
func1()
func2()
������������ͨ�ĺ��������ִ��,�����̷ֱ�ִ�����������еĴ���,���Ⱥ�����:1��2��3��4��
���������Э�̼�����ô�Ϳ���ʵ�ֺ����������л�ִ��,��������:1��3��2��4 ��
��Python���ж��ַ�ʽ����ʵ��Э��,����:
-
greenlet
pip install greenletfrom greenlet import greenlet def func1(): print(1) # ��1��:��� 1 gr2.switch() # ��3��:�л��� func2 ���� print(2) # ��6��:��� 2 gr2.switch() # ��7��:�л��� func2 ����,����һ��ִ�е�λ�ü������ִ�� def func2(): print(3) # ��4��:��� 3 gr1.switch() # ��5��:�л��� func1 ����,����һ��ִ�е�λ�ü������ִ�� print(4) # ��8��:��� 4 gr1 = greenlet(func1) gr2 = greenlet(func2) gr1.switch() # ��1��:ȥִ�� func1 ���� -
yield
def func1(): yield 1 yield from func2() yield 2 def func2(): yield 3 yield 4 f1 = func1() for item in f1: print(item)
��Ȼ�������ֶ�ʵ����Э��,�����ֱ�д����ķ�ʽûɶ���塣
���������л�ִ��,���ܷ����ó����ִ���ٶȸ�����(��Ƚ��ڴ���)��
Э����β��ܸ���������?
��Ҫ���û��ֶ�ȥ�л�,��������IO����ʱ���Զ��л���
Python��3.4֮���Ƴ���asyncioģ�� + Python3.5�Ƴ�async��async� ,�ڲ�����Э�̲�������IO�����Զ����л���
import asyncio
async def func1():
print(1)
await asyncio.sleep(2)
print(2)
async def func2():
print(3)
await asyncio.sleep(2)
print(4)
tasks = [
asyncio.ensure_future(func1()),
asyncio.ensure_future(func2())
]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
"""
��Ҫ�Ȱ�װ:pip3 install aiohttp
"""
import aiohttp
import asyncio
async def fetch(session, url):
print("��������:", url)
async with session.get(url, verify_ssl=False) as response:
content = await response.content.read()
file_name = url.rsplit('_')[-1]
with open(file_name, mode='wb') as file_object:
file_object.write(content)
async def main():
async with aiohttp.ClientSession() as session:
url_list = [
'https://www3.autoimg.cn/newsdfs/g26/M02/35/A9/120x90_0_autohomecar__ChsEe12AXQ6AOOH_AAFocMs8nzU621.jpg',
'https://www2.autoimg.cn/newsdfs/g30/M01/3C/E2/120x90_0_autohomecar__ChcCSV2BBICAUntfAADjJFd6800429.jpg',
'https://www3.autoimg.cn/newsdfs/g26/M0B/3C/65/120x90_0_autohomecar__ChcCP12BFCmAIO83AAGq7vK0sGY193.jpg'
]
tasks = [asyncio.create_task(fetch(session, url)) for url in url_list]
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
ͨ���������ݷ���,�ڴ���IO����ʱ,Э��ͨ��һ���߳̾Ϳ���ʵ�ֲ����IJ�����
Э�̡��̡߳����̵�����?
�߳�,�Ǽ�����п��Ա�cpu���ȵ���С��Ԫ��
����,�Ǽ������Դ�������С��Ԫ(����Ϊ�߳��ṩ��Դ)��
һ�������п����ж���߳�,ͬһ�������е��߳̿��Թ����˽����е���Դ��
����CPython��GIL�Ĵ���:
- �߳�,������IO�ܼ��Ͳ�����
- ����,�����ڼ����ܼ��Ͳ�����
Э��,Э��Ҳ���Ա���Ϊ�߳�,��һ���û�̬�ڵ��������л�����,�ڿ����н������IO�Զ��л�,�Ϳ���ͨ��һ���߳�ʵ�ֲ���������
����,�ڴ���IO����ʱ,Э�̱��̸߳��ӽ�ʡ����(Э�̵Ŀ����Ѷȴ�һЩ)��
���ںܶ�Python�еĿ�ܶ���֧��Э��,����:FastAPI��Tornado��Sanic��Django 3��aiohttp��,��ҵ����ʹ�õ�ҲԽ��Խ��(Ŀǰ�����ر��)��
����Э��,Ŀǰֻ��Ҫ���˽���Щ�����,������Ŀ�����Ӧ�� ��ʱ���ع����˽�,�ȴ��ѧ��Web��ܺ��������֪ʶ֮��,����ѧϰ�Ͳ���Ч�����ѡ�
���̺߳Ͷ����������永��
Ϊ�˷�ֹ�Ӿ�ƣ��,������һ����Ůͼ��վ��һ������ͼƬ����ϰ����,
��ַ:
https://www.pximg.com/topic/nvshen/page/3
url�����3���ǵ���ҳ,������ʾ��ֻ��һ�µ���ҳ��ͼƬ��
����б�ҳ��24��ͼƬ����,�������ȥ,����ҳ��������:

������Ҫ���ľ����Ȼ�ȡ�б�ҳ������url,Ȼ��������ҳ��ȡͼƬurl,����ͼƬurl��������,����ͼƬ��🆗�ˡ�
���������ǿ���д��������:
���� 1. ������ҳ��, ����ҳ�����õ�����ҳ��url.
���뵽����ҳ. ������ҳ����ȡ��ͼƬ�����ص�ַ
���� 2. ����������ͼƬ(����ʹ���̳߳�����)
ʹ�ö��н��н���֮���ͨ�š�
�����:
import os
import requests
from lxml import etree
from multiprocessing import Process, Queue
from concurrent.futures import ThreadPoolExecutor
def get_img_src(q):
url = "https://www.pximg.com/topic/nvshen/page/3"
resp = requests.get(url)
resp.encoding = 'utf-8'
# print(resp.text)
tree = etree.HTML(resp.text)
href_list = tree.xpath("//div[@class='camLiTitleC hot']/p/a/@href")
for href in href_list:
resp_child = requests.get(href)
resp_child.encoding = "utf-8"
child_tree = etree.HTML(resp_child.text)
# https://img.pximg.com/wp-content/uploads/2018/04/a59f6f26b7dbaa7.jpg?x-oss-process=image/resize,m_fill,w_80/quality,q_90/sharpen,100/format,webp
# src ����������Сͼ,��?�и�ȡ��jpg���Ǵ�ͼ,
src_list = child_tree.xpath("//li/a/img/@src") # ����һ������ҳ�ж���ͼƬ
for src in src_list:
src = src.split('?')[0]
print(src)
q.put(src) # ������
q.put("OK��")
def download(url):
file_name = url.split("/")[-1]
if not os.path.exists("images"):
# ����imagesĿ¼
os.makedirs("images")
file_path = os.path.join("images", file_name)
with open(file_path, mode="wb") as f:
resp = requests.get(url)
f.write(resp.content) # �������
def download_all(q):
# �ڽ����ﴴ���̳߳�
with ThreadPoolExecutor(10) as t:
while 1:
src = q.get() # ������
if src == "OK��":
break
# print(src)
t.submit(download, src)
if __name__ == '__main__':
q = Queue()
p1 = Process(target=get_img_src, args=(q,))
p2 = Process(target=download_all, args=(q,))
p1.start()
p2.start()
���ս��:
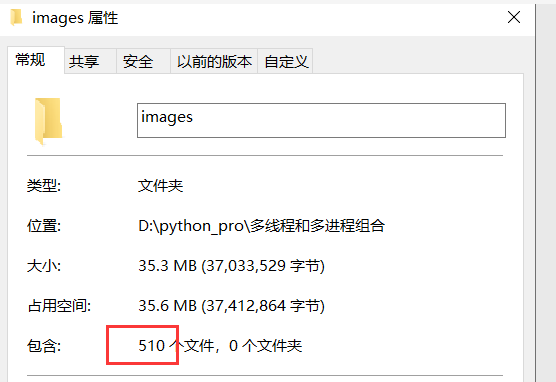
һ���б�ҳ24������url,һ������ҳ�����20������ͼ��
�������ҳ��ٶ�����ͼƬ,Ӧ���Ǻ����ġ�
ע��,�����������վûɶ��ά��,�Ƚ�����,��ЩͼƬ����û����,��ʵ������ҳ�ϵ�urlȷʵ��,���dz��������,�Ⲣ����Ҫ,��ε���ҪĿ�����������˼·��
���µ��˽���,��Ը���Ķ�������һ�����,��ӭ����,�����,�ո���ɶ��,������ľ�������,���й������о�,�úý���������!������!�´μ�!

