引子
最近调研了蛮多能跑德州扑克的平台,但有些代码太老,有些太过复杂,很难找到开源的、方便的代码供研究。最近发现neuron_poker,考虑安装的复杂程度、代码阅读难度、运行效率等因素,综合来看算是不错,而且还带有GUI界面,唯一的遗憾就是里面Keras和torch.keras混用,而我pytorch用的比较多,所以没有深入研究。
本文简单介绍一下neuron_poker的安装及使用。这是一个用于强化学习研究德州扑克的环境,主要用于学术研究。github链接:https://github.com/dickreuter/neuron_poker。

虽然readme里面的内容已经足够了,但对于完全的小白来说可能比较不友好,于是我决定写一篇保姆级别的使用教程。顺带一提,我的操作系统是win10。
安装Anaconda
顺便还可以安装一下pycharm。这部分网上的教程非常多,能看见这篇博文的同学搜索引擎随便搜,点开前几个链接看看准没错。
可以用conda -V 和python -V来检查自己有没有安装好。
安装环境及相关依赖
主要分为三步:git clone , conda create env 和pip install
选择一个文件夹,命令行进入。
命令行输入git clone https://github.com/dickreuter/neuron_poker.git,回车运行。

如果报错提示缺少git就用 pip install git这个命令安装一下,如果没有办法访问github就用国内的镜像。
安装好neuron_poker.git后,运行cd neroun_poker-master进入对应的文件夹。
运行指令 conda create -n neuron_poker python=3.7,创建一个虚拟环境,neuron_poker就是环境名称,如果是第一次创建的话可能需要自动下载一些第三方拓展包,等待一会儿之后conda activate neuron_poker打开虚拟环境。
我直接使用的环境是base。

然后运行指令pip install -r requirements.txt就可以自动安装需要的第三方依赖库了。
现实Requirement already satisfied 就说明安装第三方依赖完成了。
运行代码
直接在命令行输入指令。
python main.py selfplay random --render
用随机决策的电脑玩家自博弈。
命令行会有输出,并且会自动跳出游戏界面:
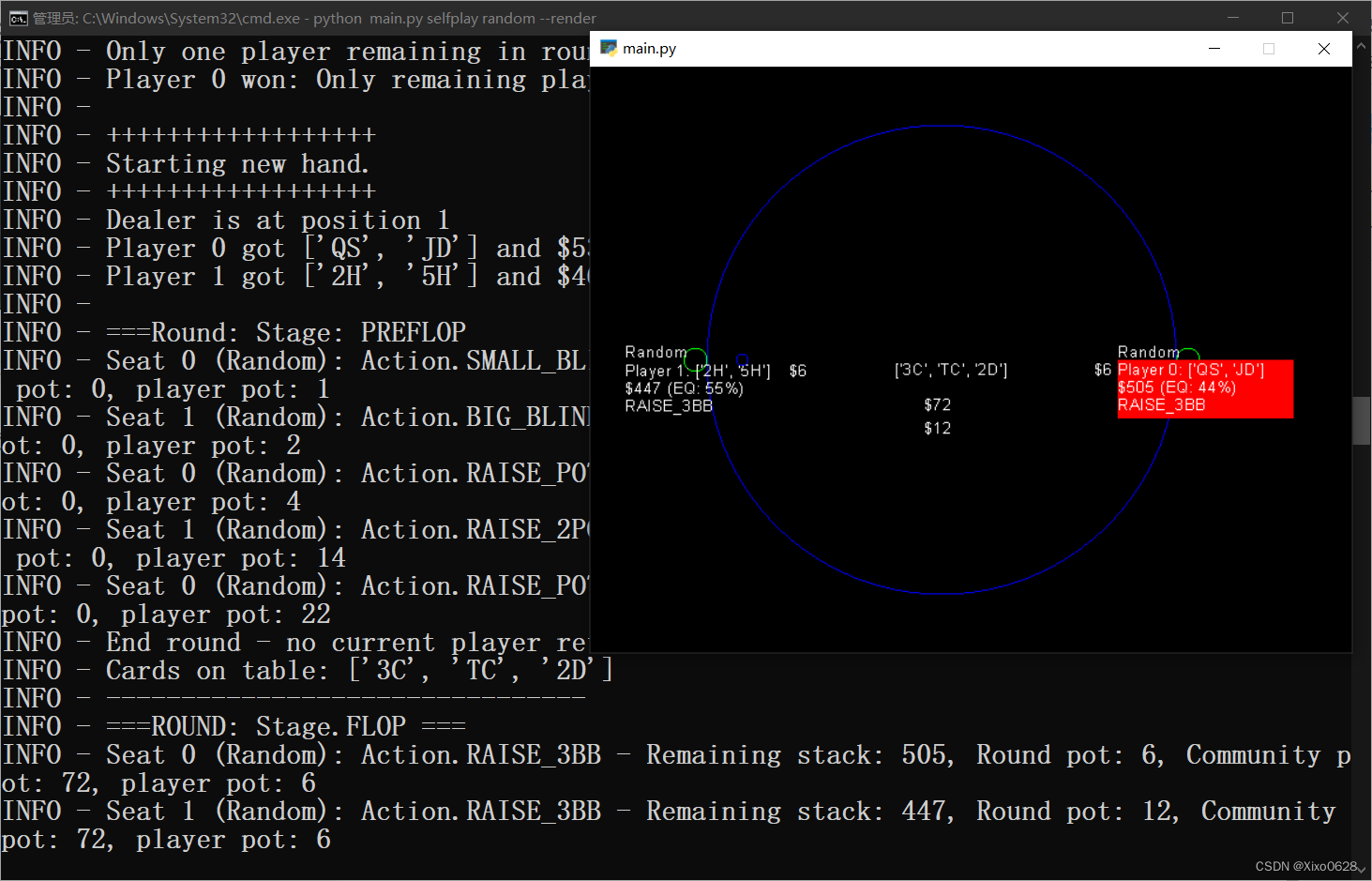
如果到了这一步,恭喜你,代码已经可以正常运行了!
后面补充一些其它的指令:
python main.py selfplay keypress --render
用键盘按键与电脑AI交互博弈。
python main.py selfplay equity_improvement --improvement_rounds=20 --episodes=10
用遗传算法与自我改善训练一个agent。
python main.py selfplay dqn_train -c
使用 c++ 蒙特卡洛训练DQN agent。
里面这些参数的含义就要具体在main.py里面找了。
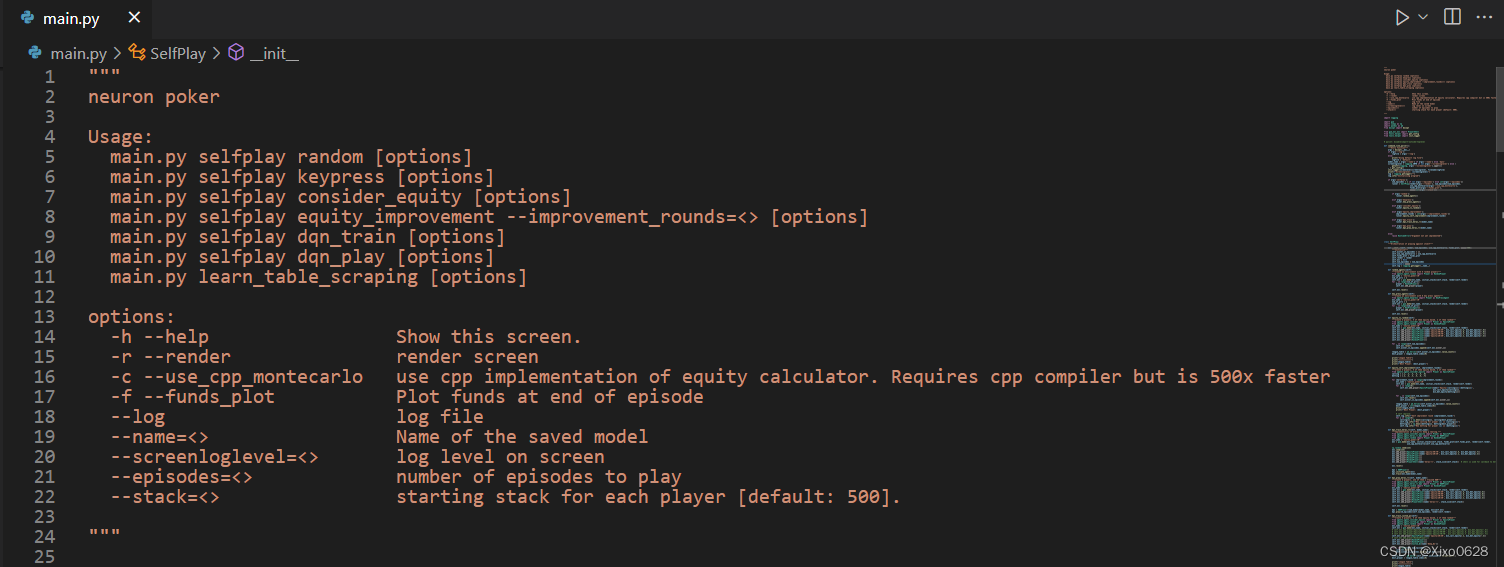
上面显示的自博弈是只有2个agent。这部分是在main.py的第106行修改玩家人数为6就可以了。
这是6个agent的的界面。

如果想深入细节更改源码,就需要进一步阅读源码和项目文档了,也就是代码的doc文件夹及readme.rst等文件。开启neuron_poker的探索之旅吧!
祝好!

