??上篇文章学习了如何统计csdn单篇博客文章的内容字数,本文学习如何统计csdn个人博客中的文章清单,包括文章类型(原创、翻译)、发表时间、文章名称、链接地址等信息。使用的模块还是BeautifulSoup和urllib。总共尝试了3种方式,分别记录如下。
从内容管理页面种抓取
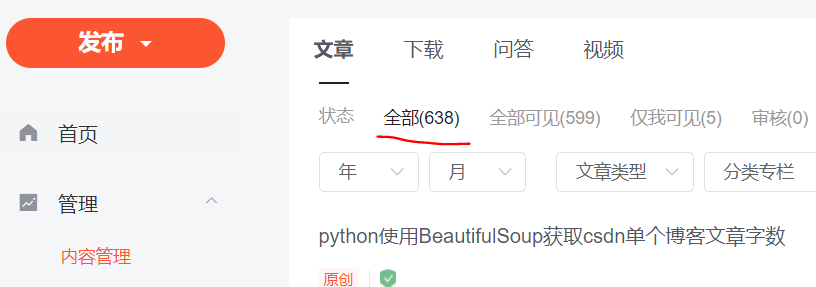
??csdn个人博客的内容管理种列出了个人发布的所有博客文章,如下图所示。最初想从这个页面种抓取内容,但是查看网页源码后,发现其中的内容并不是预想的网页结构,看不懂里面的内容,只好作罢,另想它法。

从个人博客主页抓取
??登录个人博客主页会看到发布的文章信息,而且鼠标滚动到页面底部时,会自动加载之前发布的文章。查看个人博客主页的网页源码,其结构如下图所示(内容太宽,只截了一部分):
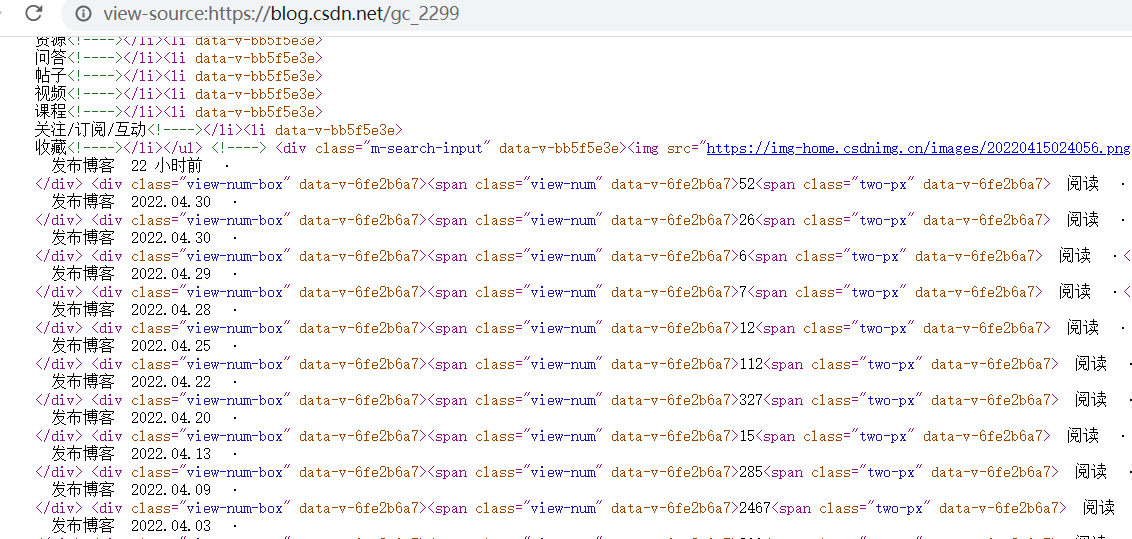
??从网页源码中可以看出如下规律:
- 一条文章记录对应一个class值为blog-list-box的article标签;
- article标签内,class值为article-type的div标签保存文章类型,其中值为article-type article-type-yc是原创文章,值为article-type article-type-fy是翻译文章;
- article标签内,class值为view-time-box的div标签保存发布时间;
- article标签内,h4标签内保存的是文章标题;
- article标签内,a标签内href属性保存的是文章链接。
??基于上述内容,编写了最初的python博客文章清单抓取程序,主要代码及程序运行效果如下(代码比较简陋,仅供参考):
# coding=gbk
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen("https://blog.csdn.net/gc_2299")
soup1=BeautifulSoup(response.read(), "lxml")
result=soup1.select("article[class='blog-list-box']")
for p in result:
bDate=p.select_one("div[class='view-time-box']")
if(p.select_one("div[class='article-type article-type-yc']")):
print("类型:原创,创建日期:%s,文章:%s,地址:%s" % (bDate.text,p.h4.text,p.a['href']))
elif(p.select_one("div[class='article-type article-type-fy']")):
print("类型:翻译,创建日期:%s,文章:%s,地址:%s" % (bDate.text,p.h4.text,p.a['href']))片

??上述程序的问题,一个是显示格式不对,一条记录换了好几行;还有一个是只能抓取个人博客主页默认显示的文章清单,目前不知道该怎么触发页码自动加载之前的文章清单。所以只能再找其它方法
从博客文章列表页码抓取
??查看csdn个人博客主页的网页源码过程中,发现最下方有个class值为item-loading的div,应该是跟鼠标滚动到底部时自动加载内容有关,其标签内的链接为https://blog.csdn.net/gc_2299/article/list/2,该地址应该就是个人博客的文章列表页面。
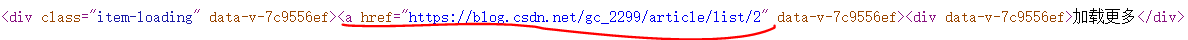
??打开上述网址,并跳转到第一页,其页面内容及网页源码如下所示:
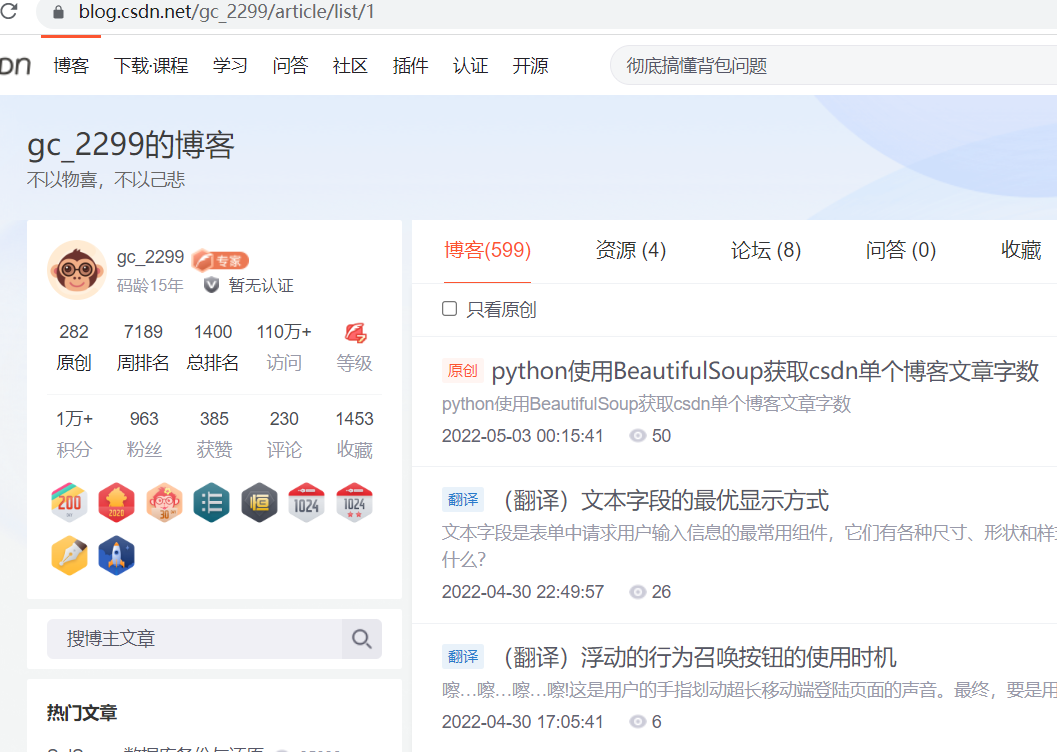

??从网页源码中可以看出如下规律:
- class值为article-list的div内保存页面中所有的文章清单;
- 一条文章记录对应一个class值为article-item-box csdn-tracking-statistics的div标签;
- 文章div标签内,class值为date的span标签保存文章发布时间;
- article标签内,h4标签内保存的是文章标题,其中h4标签内的span标签保存文章类型,a标签的href属性保存的是文章链接;
??基于上述内容,编写了第二版python博客文章清单抓取程序,主要代码及程序运行效果如下(代码比较简陋,仅供参考):
# coding=gbk
from bs4 import BeautifulSoup
import urllib.request
response = urllib.request.urlopen("https://blog.csdn.net/gc_2299/article/list/1")
soup1=BeautifulSoup(response.read(), "lxml")
result=soup1.select("div[class='article-item-box csdn-tracking-statistics']")
for p in result:
bDate=p.select_one("span[class='date']")
print("类型:%s,创建日期:%s,文章:%s,地址:%s" % (p.h4.span.text,bDate.text,p.h4.text.strip(p.h4.span.text+" \n"),p.h4.a['href']))

??目前个人博客文章总共15页,可以通过for循环拼url地址方式循环抓取每页中的文章清单,具体代码在此不再讨论。
??目前已经可以将文章类型(原创、翻译)、发表时间、文章名称、链接地址等信息抓取到,后续将学习如何将信息保存到本地文件或数据库中,以便后续进一步处理。
参考文献
[1]https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/index.html#
[2]https://blog.csdn.net/qq_41694291/article/details/107903018
[3]https://blog.csdn.net/qq_43673981/article/details/115541827

