python基础理论
格式化打印
print(“{}”.format(变量名))
在测试报告输出的应用:
“./report/某某公司TestReport-{}.html”.format(time.strftime(“%Y%m%d-%H%M%S”))
print(f "{变量名} ")
日常建议使用这种,方便简洁
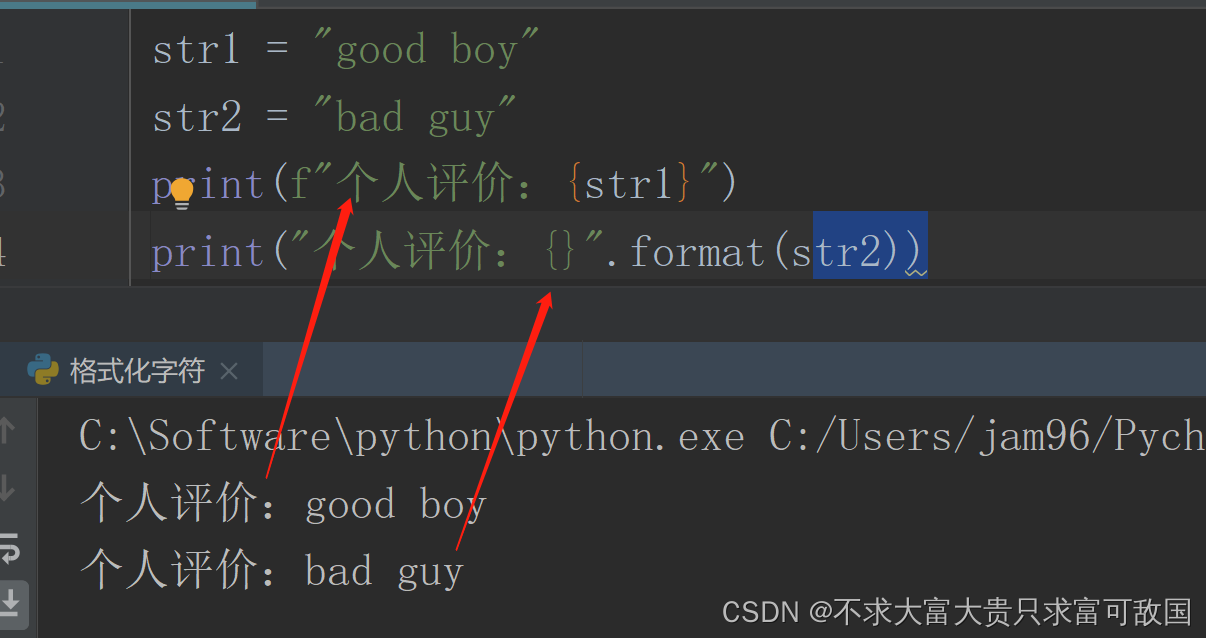
str1 = "good boy"
str2 = "bad guy"
print(f"个人评价:{str2}")
print("个人评价:{}".format(str1))
字符串
其它:title()
列表
增删改查
增:insert[索引,数据]
list=['jiang','zhang','wang','gong']
list.insert(0,"san")
print(list)
打印结果:
['san', 'jiang', 'zhang', 'wang', 'gong']
增:append[数据]
append翻译成中文是“追加”的意思,作用亦是追加,自动化中经常用此方法整理数据
list=['jiang','zhang','wang','gong']
list.append("san")
print(list)
打印结果:
['jiang', 'zhang', 'wang', 'gong', 'san']
增:extend[列表]
追加列表 (extend翻译成中文是“扩展”的意思,初学时可以根据中文含义区分append与extend)
list1=['jiang','zhang','wang','gong']
list2=["san","si"]
list1.extend(list2)
print(list1)
打印结果:
['jiang', 'zhang', 'wang', 'gong', 'san', 'si']
删:
del
pop
remove
查:
下标
改:
下标
列表复制
list1 = ["jxd","gyy"]
list2 = list1[:]
print(list2)
打印结果:
['jxd', 'gyy']
列表去重
两种实现方式
方式一:
使用set()方法 弊端:改变列表顺序
list3=["caoyu","liyu","heiyu","wugui","liyu"]
print(list(set(list3)))
打印结果:
['liyu', 'caoyu', 'heiyu', 'wugui']
方式二:
新建一个空列表,通过判断把唯一的数据追加到新列表
list3=["caoyu","liyu","heiyu","wugui","liyu"]
list4=[]
for i in list3:
if i not in list4:
list4.append(i)
print(list4)
打印结果:
['caoyu', 'liyu', 'heiyu', 'wugui']
元组
有序,可以通过下标访问成员
集合
无序,不可以通过下标访问成员
可以包含不同数据类型,比如{“张三”,“25”,“man”}
字典
get()
dict1={"1":"18205691234","龚":"15555401234","王":"13345678912"}
print(f"{dict1.get('蒋','蒋 对应的 key not exist!!')}")
打印结果:
蒋 对应的 key not exist!!
items()
dict1={"1":"18205691234","龚":"15555401234","王":"13345678912"}
for i in dict1.items():
print(i)
打印结果:
('1', '18205691234')
('龚', '15555401234')
('王', '13345678912')
dict1={"1":"18205691234","龚":"15555401234","王":"13345678912"}
for q,w in dict1.items():
print(q,w)
打印结果:
1 18205691234
龚 15555401234
王 13345678912
keys()
dict1={"1":"18205691234","龚":"15555401234","王":"13345678912"}
for e in dict1.keys():
print(e)
打印结果:
1
龚
王
values()
dict1={"1":"18205691234","龚":"15555401234","王":"13345678912"}
for r in dict1.values():
print(r)
打印结果:
18205691234
15555401234
13345678912
循环
if else
while
可迭代对象
迭代器
生成器
装饰器
自带库
time
random
random.choice(seq)
从非空序列中随机选取一个数据并带回,该序列可以是str、list、tuple 不可以是set、dict
验证:

应用:
随机生成手机号时,前两位一般只有以下四种样式:[“13”,“15”,“17”,“18”]
random.choice([“13”,“15”,“17”,“18”]):代表从[“13”,“15”,“17”,“18”]列表中随机选取一个
random.choices(population,weights=None,*,cum_weights=None,k=1)
应用:
随机生成5位字符串:
i=0
while i<5:
print("".join(random.choices(string.ascii_lowercase+string.digits,k=5)))
i+=1
结果如下:
yyhv4
fg1w4
ofq17
fdcpl
aev08
以下五种相较于以上两种较简单,最好全部掌握:
random.random()
随机生成一个[0,1)之间的浮点数。
random.randint(a,b)
随机生成[a,b]范围内一个整数。
random.randrange(a,b,step)
不指定step,随机生成[a,b)范围内一个整数。
指定step,step作为步长会进一步限制[a,b)的范围,比如randrange(0,11,2)意即生成[0,11)范围内的随机偶数。
不指定a,则默认从0开始。
random.uniform(a,b)
产生[a,b]范围内一个随机浮点数。
uniform()的a,b参数不需要遵循a<=b的规则,即a小b大也可以,此时生成[b,a]范围内的随机浮点数。但如果上面的三个方法采用这种方式就会产生TypeError或者ValueEeeor错误。
random.sample(population,k)
从集群population中选取k个元素,返回一个列表,集群可以是list、tuple、str、set。
与random.choices()的区别:一个是选取k次,一个是选取k个,选取k次的相当于选取后又放回,选取k个则选取后不放回。故random.sample()的k值不能超出集群的元素个数。
string
一般配合random模块随机生成字符串
#字母
print(string.ascii_letters)
#小写字母
print(string.ascii_lowercase)
#大写字母
print(string.ascii_uppercase)
#数字
print(string.digits)
打印结果如下:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
os
sys
json
csv
(也可以使用其他第三方库.例如pandas)
logging
日志处理打印
第三方库
requests
接口自动化使用,主要用于发送请求
Appium
APP 自动化测试
Selenium
Web自动化
pymysql
数据库的连接和操作
openpyxl
(读写excel使用,也可以使用其他第三方库))
pytest
自动化测试框架,但也是第三方包
其它
pycharm快捷键
自动导入
输入“包名”后按下Alt + Enter组合键,即可选择并导入“包名”,代码量比较大时不用每次回到最前面导入需要的库
import格式化
Ctrl + Alt + O快捷键可以格式化import部分的代码,移除没用的库,按自带库、第三方库、自己写的库分类并排序
print快速使用
在一个字符串或其他对象后边直接输入.print,可快速打印该字符串
iter快速遍历列表
iter可实现快速补全遍历数组的代码

