ФПТМ
1ЁЂseleniumМђНщ
?????????SeleniumЪЧвЛИігУгкWebгІгУГЬађВтЪдЕФЙЄОп,SeleniumВтЪджБНгдЫаадкфЏРРЦїжа,ОЭЯёеце§ЕФгУЛЇдкВйзївЛбљЁЃжЇГжЕФфЏРРЦїАќРЈIE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google?Chrome,Opera,EdgeЕШ; жЇГжЕФПЊЗЂгябдгаJavaЁЂPythonЁЂC#ЁЂrubyЁЃ
???2004ФъseleniumЕЎЩњ
???2006ФъwebdriverЕЎЩњ
???2008ФъseleniumгыwebdriverКЯВЂselenium2.0
???2016Фъselenium3.0ЕЎЩњ
???2021Фъselenium4.0ЕЎЩњ
Selenium IDE
????????ЧЖШыЕНFIrefoxфЏРРЦїжаЕФвЛИіВхМў,ЪЕЯжМђЕЅЕФфЏРРЦїВйзїЕФТМжЦКЭЛиЗХЙІФм,гІгУГЁОА:ПьЫйЕФДДНЈbugжиЯжГЁОА,дкВтЪдШЫдБВтЪдЙ§ГЬжа,ЗЂЯжbugжЎКѓПЩвдЭЈЙ§IDEНЋжиЯжЕФВНжшТМжЦЯТРД,вдАяжњПЊЗЂШЫдБИќШнвзЕФжиЯжbug
IDEТМжЦЕФНХБОПЩвдзЊЛЛЮЊЖржжгябдЁЃДгЖјАяжњЮвУЧПьЫйЕФПЊЗЂНХБО
Ps: АДОбщНЈвщОЁСПЩйгУТМжЦ,дкШЫЙЄжЧФмУЛЗЂеЙЕНвЛЖЈГЬЖШ,етЪЧвЛЬѕЭсТЗЁЃ
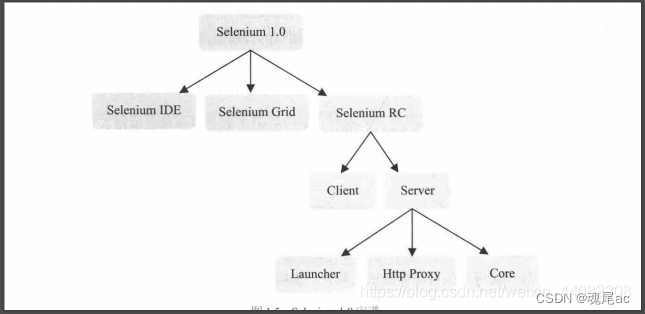
Selenium RC
????????????????Selenium RC ЪЧSeleniumМвзхЕФКЫаФВПЗжЁЃSelenium RC жЇГжЖржжВЛЭЌгябдБраДЕФздЖЏЛЏНХБОВтЪд,ЭЈЙ§Selenium RCЗўЮёЦїзїЮЊДњРэЗўЮёЦїШЅЗУЮЪгІгУ,ДгЖјДяЕНВтЪдЕФФПЕФЁЃ
Selenium RCЗеЮЇClient LibrariesКЭSelenium ServerЁЃClient LibrariesПтжївЊгУгкБраДВтЪдНХБО,гУРДПижЦSelenium ServerЕФПтЁЃSelenium Server ИКд№ПижЦфЏРРЦїааЮЊЁЃзмЕФРДЫЕ,Selenium Server АќРЈШ§ИіВПЗж:LauncherЁЂHttp ProxyКЭCoreЁЃЦфжа,Selenium CoreЪЧБЛSelenium ServerЧЖШыЕНфЏРРЦївГУцжаЁЃЦфЪЕSelenium CoreОЭЪЧвЛЖбJavaScriptКЏЪ§ЕФМЏКЯ,МДЭЈЙ§етаЉjavascriptКЏЪ§ЮвУЧВХФмЪЕЯжгУГЬађЖдфЏРРЦїЕФВйзїЁЃLauncherгУгкЦєЖЏфЏРРЦї,АбSelenium CoreМгдиЕНфЏРРЦївГУцЕБжа,ВЂАбфЏРРЦїЕФДњРэЩшжУЮЊSelenium ServerЕФHttp ProxyЁЃ
Ps: НЈвщзіWEBздЖЏЛЏЙ§ГЬжаПЩвдЫГБуНЋjsбЇЛсЁЃ
2ЁЂЛЗОГ Python + selenium
2.1ЁЂseleniumПтАВзА
УќСю:pip insatll selenium ?Лђ pip3 install selenium
2.2ЁЂЧ§ЖЏЯТди
фЏРРЦїЧ§ЖЏЯТди chrome ?(ieЁЂЛ№КќПЩздаабЇЯА)
- ШЗШЯЙШИшфЏРРЦїАцБО,ВйзїШчЯТЭМ,ШЗШЯАцБОЮЊ100.0.4896.127
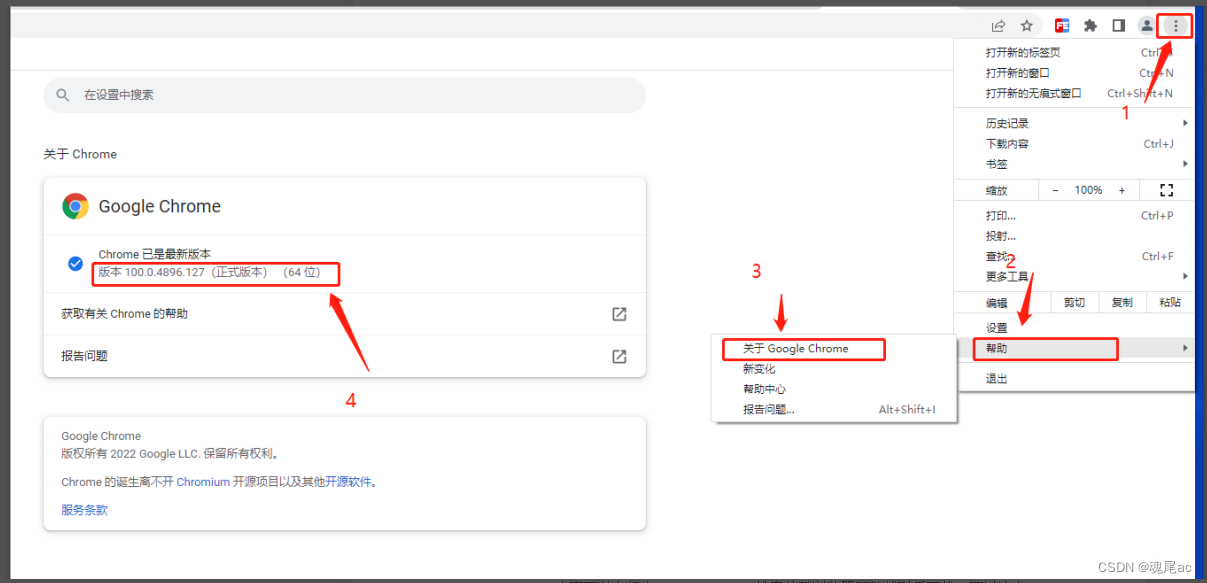
- еыЖдфЏРРЦїАцБОШЅЯТдиЖдгІЕФЧ§ЖЏ
????????ДѓМвПЩвдздааШЅwww.baidu.comЫбЫїЙШИшфЏРРЦїЧ§ЖЏевЕНКѓЯТди,ВЛЙ§етИіЙ§ГЬПЩФмБШНЯОУЁЃдкетРяЬсЙЉЫљгаАцБОЕФЯТдиСЌНг
http://chromedriver.storage.googleapis.com/index.html
? ? ? ??НјШыЭјеОевЕНЖдгІАцБОЕФЧ§ЖЏЯТди,ЩЯЭМАцБОЪЧ100.0.4896.127,ЪЧвдвЊевЕНЖдгІАцБОЯТди,ШчЙћевВЛЕНЖдгІАцБО,ПЩвдевзюЯрНќЕФАцБОЁЃвВЪЧПЩвдгУРДЧ§ЖЏфЏРРЦїЕФ,ВЛФмгУвЛЖЈЛсгаЖдгІАцБОГіЯж;ЯждкУЛгаевЕН100.0.4896.127АцБО,ЫљвдевЕНзюНгНќАцБО100.0.4896.60ЯТди
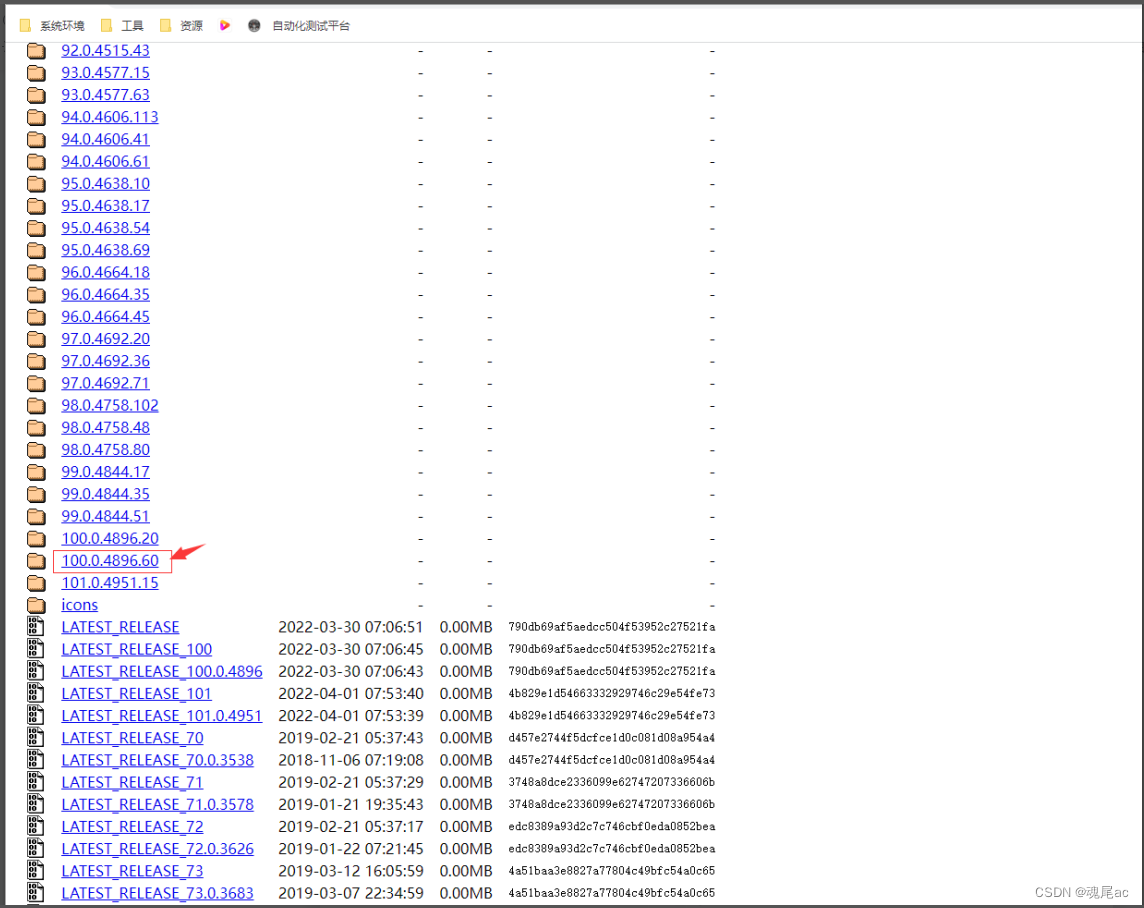
????????бЁдёЕБЧАЯЕЭГЫљЖдгІЕФАцБО,ЯёwindowАцБО,жБНгЯТwin32ЕФАќ,ВЛгУЕЃаФ64ЮЛЯЕЭГЁЃЭЈгУ,ШчЙћВЛЭЈгУ,ПЯЖЈЛсгавЛИіwin64ЕФАќЁЃ
НЋЯТдиЕФzipбЙЫѕАќНтбЙГіРДЕФchromedriver.exeЕФЮФМў
2.3ЁЂЧ§ЖЏЮЛжУгыЪЙгУ
????????Ч§ЖЏЮЛжУгаСНжж,етРяНВСщЛюЗХжУЗЈ,ЙцЗЖЗХжУЗЈДѓМвПЩЕБПЮЬтздааШЅбаОПЁЃ
СщЛюЗХжУЪЧНЋЧ§ЖЏЮФМўЗХЕНseleniumжДааДњТыЮФМўЭЌМЖФПТМЯТМДПЩЁЃ
ОйР§:
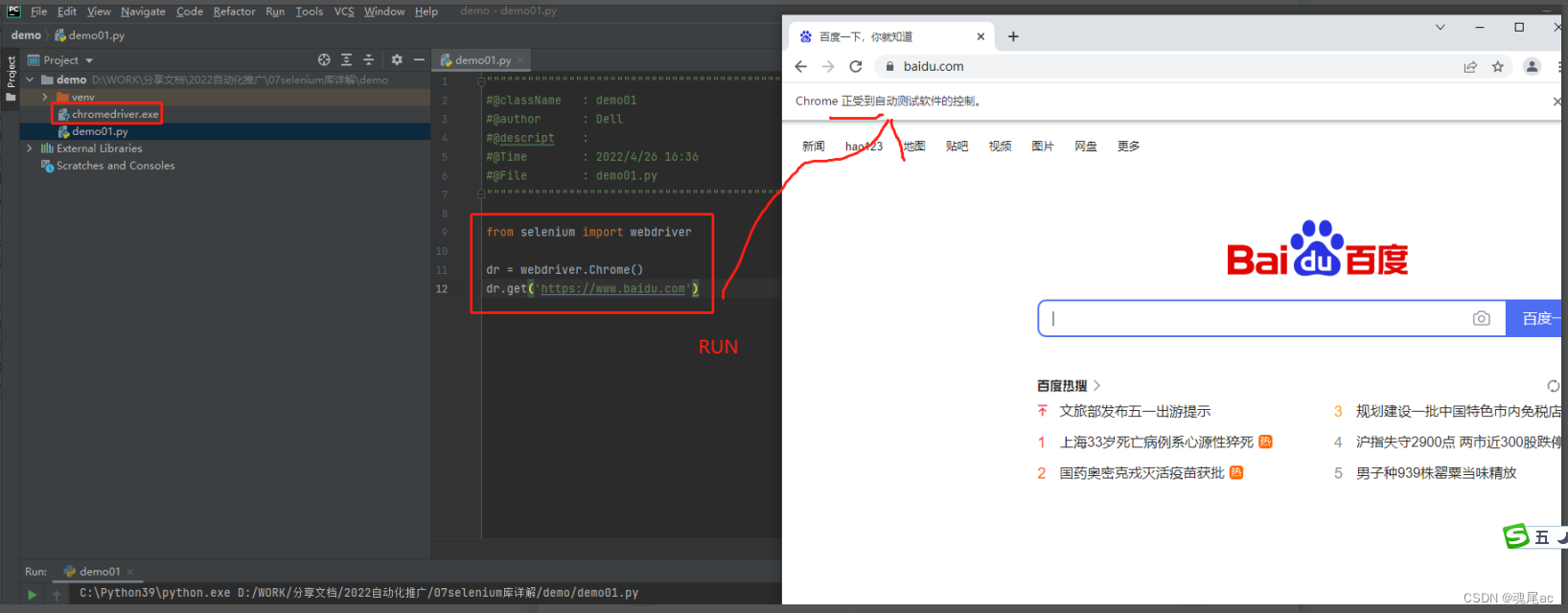
аТдівЛИіpythonЯюФП,ШЛКѓНЋchromedriver.exeЮФМўЗХЕНЯюФПФПТМЯТ
аТдівЛИіdemo01.pyЮФМўдкЮФМўРяБраДДђПЊАйЖШЕФДњТы
from selenium import webdriver
dr = webdriver.Chrome()
dr.get('https://www.baidu.com')
дЫааЁЃШчЯТЭМ,ГЩЙІДђПЊЙШИшфЏРРЦї,ЗУЮЪАйЖШЭјеО
3ЁЂseleniumПтДњТыНВНт
????????ЪЙгУseleniumжЎЧА,ашвЊЯШСЫНтвЛаЉЭјвГдЊЫиЖЈЮЛЕФжЊЪЖ,НсКЯетаЉжЊЪЖРДЪЕЯждЊЫиЖЈЮЛКѓЕуЛї,БрМЕШ
ШчКЮЪжЖЏНјаадЊЫиЖЈЮЛ?
????????ДђПЊфЏРРЦї---f12НјШыПЊЗЂепФЃЪН---дкElementsвГУц---ЪЙгУбЁдёЙЄОпШЅвГУцЕуЛїЖдгІдЊЫи---HTMLНЋздЖЏеЙПЊВЂИпССЯдЪОбЁдёЕНЕФдЊЫиБъМЧ
живЊжЊЪЖЕу
- find_element() ?гы find_elements() ЗНЗЈ
- дЊЫиЖЈЮЛАЫДѓЗНЪН
НЋЩЯУцСНЕуНсКЯЦ№РДНВНт,ШчЯТ:
3.1~3.7НщЩмЖЈЮЛАЫДѓЗНЪН,3.8ЪЧНВjsЖРСЂНХБО
3.1ЁЂid
????????дкЭјвГHTMLжаЗЂЯжгавЛИідЊЫиИеКУгаidЪєад,КмавдЫ,вђidЛљБОЩЯашвЊЮЈвЛ,ВЛШЛDocЛсГіЯжЮДжЊвьГЃЁЃЮвУЧПЩвдЪЙгУЦфЖЈЮЛГіРДетдЊЫиРДЪЕЯжЖдгІВйзїЁЃвђЮЊЫќЪЧЮЈвЛЕФ,ЫљвдвЛАуПЩвдЪЙгУfind_element()РДЖЈЮЛ
ОйР§:
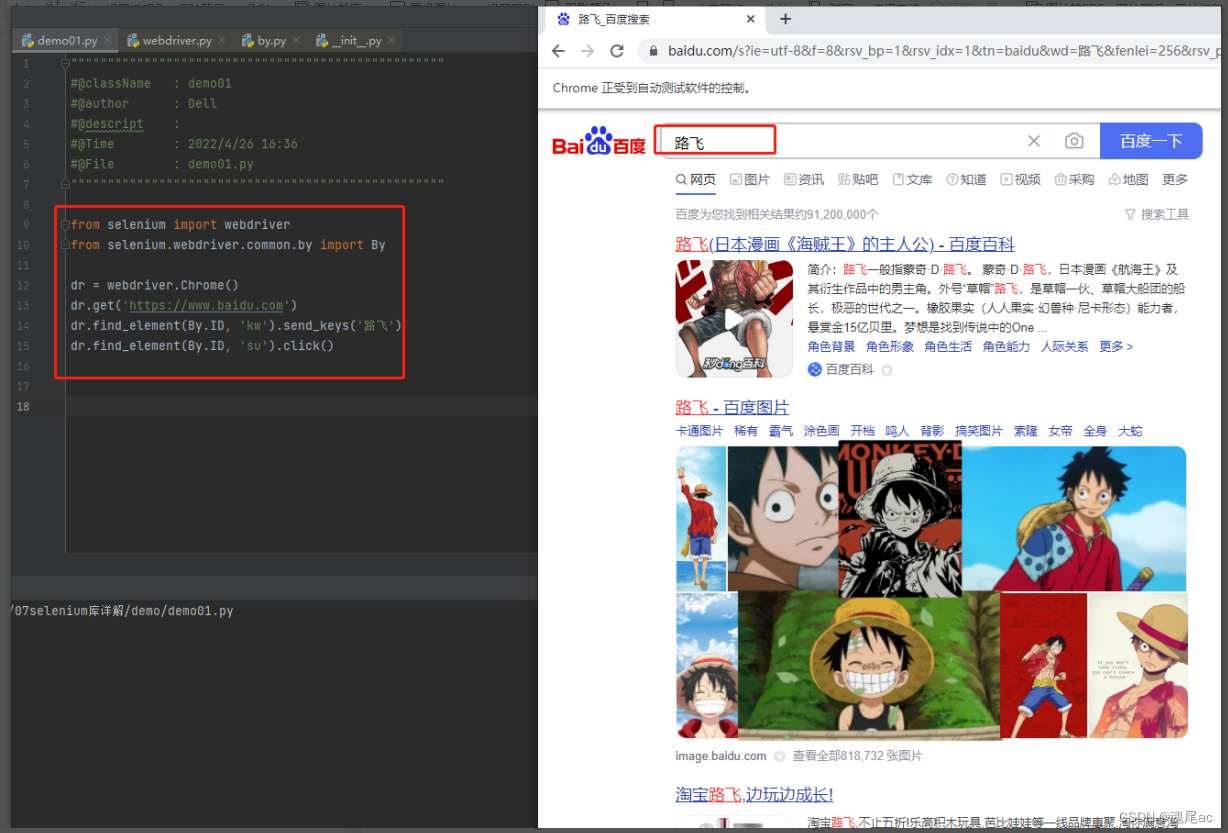
НјШыАйЖШ,ЫбЫїЁЏТЗЗЩЁЏ,
ПЩвдЭЈЙ§ f12дкhtmlРяжЊЕРАйЖШЫбЫїПђМмЕФidЪЧkw,ЫбЫїАДХЅЕФidЪЧsu
ЫљвдБраДДњТыШчЯТ:
#ЕМШыПт
from selenium import webdriver
from selenium.webdriver.common.by import By
#ГѕЪМЛЏфЏРРЦї
dr = webdriver.Chrome()
#ДђПЊАйЖШ
dr.get('https://www.baidu.com')
#ЪфШыТЗЗЩ
dr.find_element(By.ID, 'kw').send_keys('ТЗЗЩ')
#ЕуЛїАйЖШвЛЯТ
dr.find_element(By.ID, 'su').click()дкзюПЊЪМашвЊНЋ selenium ЕФ webdriverгыBy ЕМШы
дкЪфШыТЗОЖгяОфжаВщбЏдЊЫиЗНЗЈfind_elementРяВЮЪ§вЛBy.IDБэЪОЖЈЮЛЪєадЪЧid,ВЮЪ§ЖўБэЪОЪєаджЕЮЊkw
ДњТыжДааШчЯТ
3.1ЁЂname
????????дкЭјвГHTMLжаЗЂЯжгавЛИідЊЫигаnameЪєад,вВКмавдЫ,вђЮЊПЊЗЂФмЬэМгname,вВЪЧвЊИјЦфБъМЧ,НЋЦфгыЦфЫћдЊЫиЧјБ№ЁЃЮвУЧПЩвдЪЙгУЦфЖЈЮЛГіРДетдЊЫиРДЪЕЯжЖдгІВйзїЁЃ
ОйР§:
ЛЙЪЧНјШыАйЖШ,ЫбЫїЁЏжюИ№ССЁЏ
ПЩвдЭЈЙ§ f12дкhtmlРяжЊЕРАйЖШЫбЫїПђЕФnameЪЧwd,ЫбЫїАДХЅЕФidЪЧsu
ЫљвдБраДДњТыШчЯТ:(дкЩЯУцвбОЕМАќСЫ,ЯТУцЕФДњТыОЭВЛЕМАќСЫ)
dr = webdriver.Chrome()
dr.get('https://www.baidu.com')
dr.find_element(By.NAME, 'wd').send_keys('жюИ№СС')
dr.find_element(By.ID, 'su').click()ПЩвдМћЪфШыжюИ№ССетЬѕгяОфВщбЏдЊЫиЗНЗЈfind_elementВЮЪ§вЛгЩ By.NAMEБэЪОгУnameЖЈЮЛ,ВЮЪ§ЖўвВЪЧШЁnameЕФжЕwd
ДњТыжДааШчЯТ
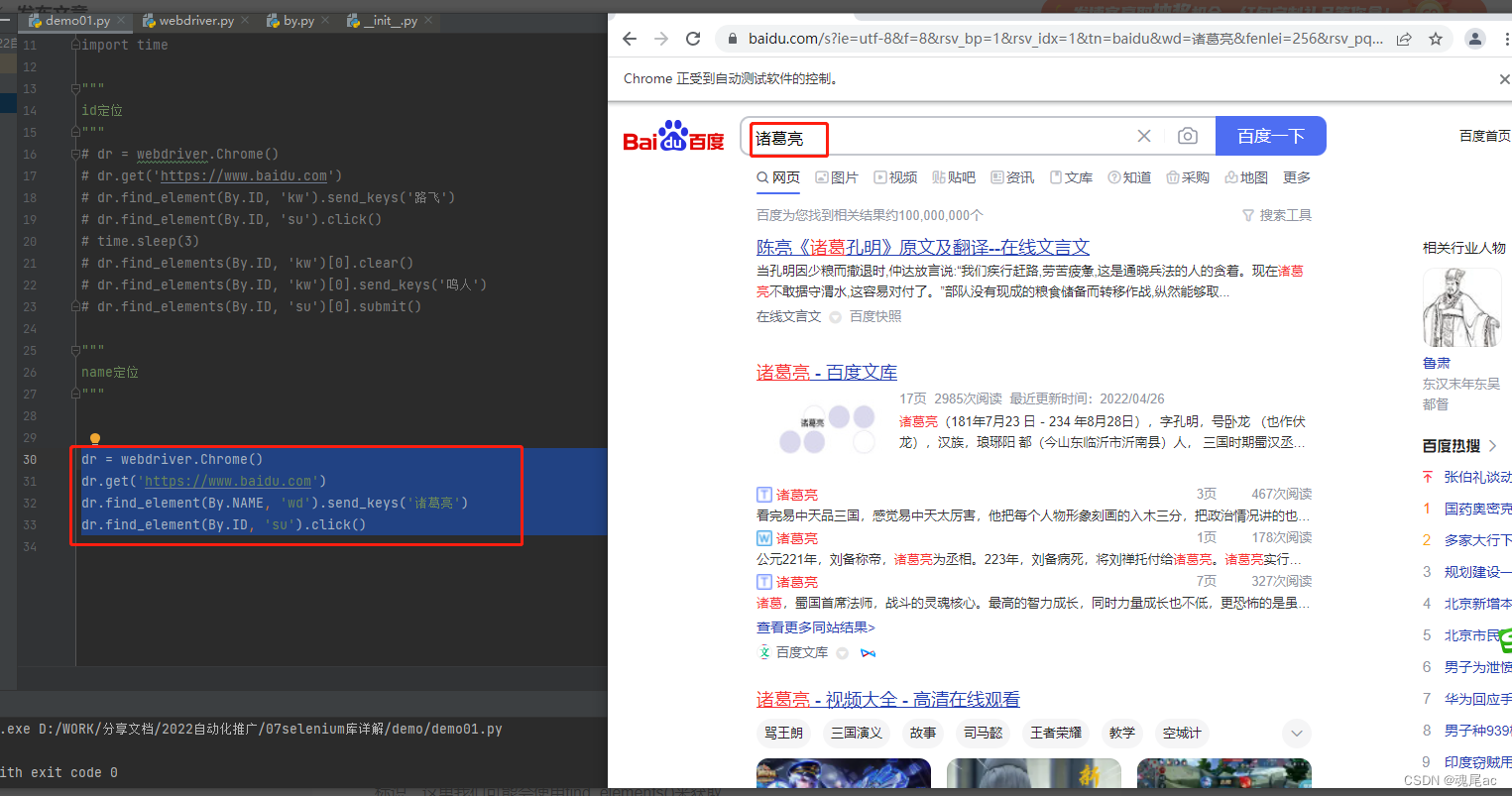
3.3ЁЂClass
????????ЭјвГHTMLвЛАуЖМЛсгаclassЪєад,ЧАЖЫПЊЗЂепЛсгУЦфРДЙщРрХњСПЬэМгбљЪН,ЫљвдЫќПЩФмВЛЪЧЮЈвЛЕФБъЪЖЁЃетРяЮвУЧПЩФмЛсЪЙгУfind_elements()РДЛёШЁ
ОйР§:
НјШыCSDN,ЕуЛїЗжРр
ЪЙгУf12ВщПДCSDNЕФHTML,ЗЂЯждкЫљгаЗжРрдЊЫиЕФclassОљЪЧnavigation-right
ЫљвдДњТыБраДШчЯТ
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
#ЕуЛїЕквЛИіЗжРр
dr.find_elements(By.CLASS_NAME, 'navigation-right')[0].click()
#ЕШД§3Уы
time.sleep(3)
#ЕуЛїЕквЛИіЗжРр
dr.find_elements(By.CLASS_NAME, 'navigation-right')[1].click()ПЩвдМћЕуЛїВщбЏдЊЫиЗНЗЈfind_elementВЮЪ§вЛгЩ By.CLASS_NAMEБэЪОСЫвЊШЁclassЖЈЮЛ,ВЮЪ§ЖўдђЪЧИјГіclassЕФжЕ
ДњТыжДааШчЯТ

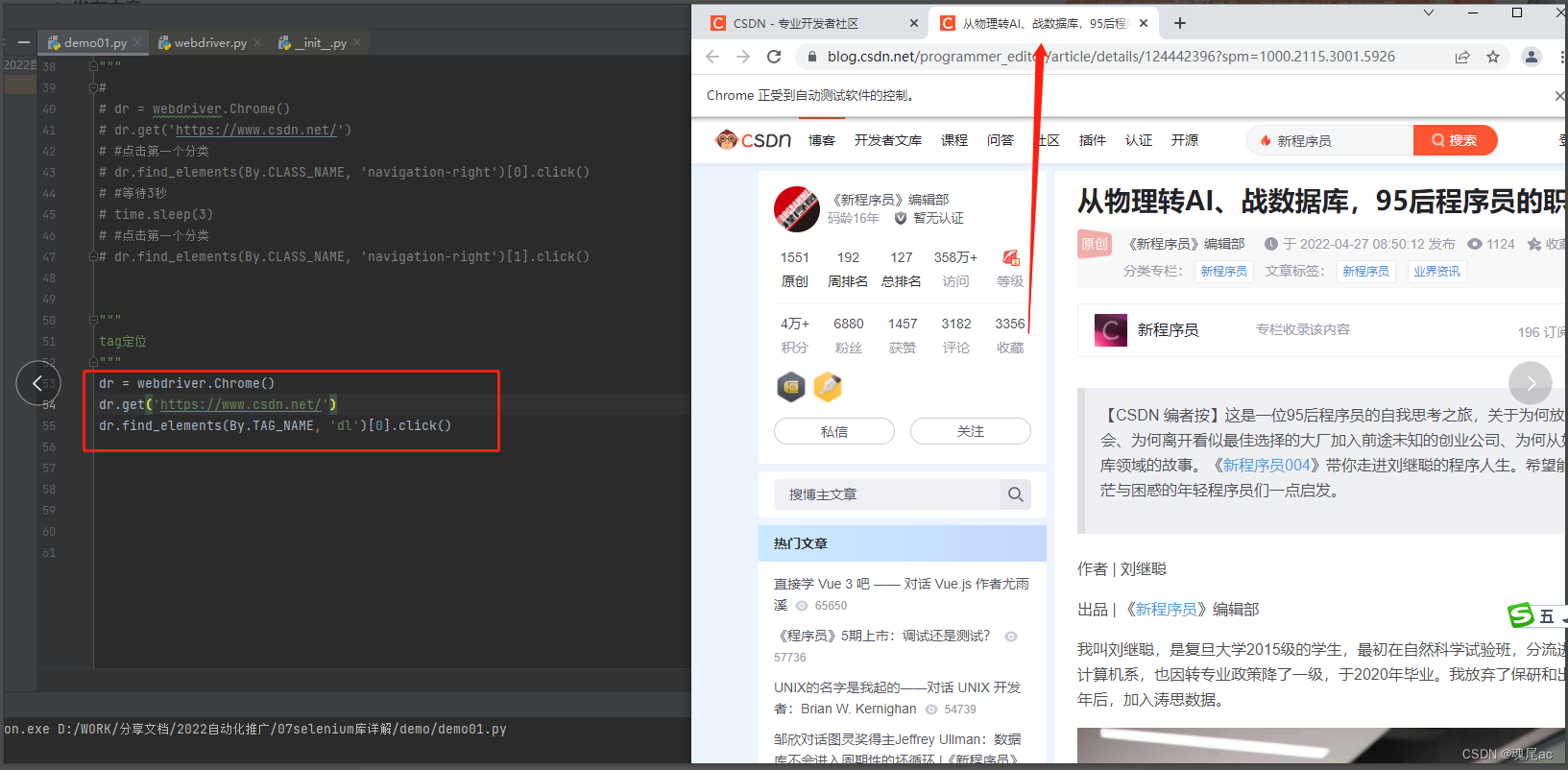
3.4ЁЂtag
????????tagЪЧЭјвГHTMLжаЕФБъМЧ,HTMLгЩБъМЧзщГЩ,вЛИіБъМЧОЭЪЧвЛИідЊЫи,ЫљвдЫќЛљБОЩЯВЛЛсЮЈвЛ,ЫљвдвВЪЙгУfind_elemenets()РДЛёШЁ
ОйР§:
НјШыCSDN,ЕуЛїЭЗЬѕаТЮХ
ЪЙгУF12ВщПДCSDNЕФHTML,ЗЂЯжЭЗЬѕаТЮХЕФЗжРрдЊЫиЕФБъЧЉЪЧdl
ЫљвдДњТыБраДШчЯТ
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.find_elements(By.TAG_NAME, 'dl')[0].click()ПЩвдМћЕуЛїВщбЏдЊЫиЗНЗЈfind_elementВЮЪ§вЛгЩ By.TAG_NAMEБэЪОСЫвЊШЁtagЖЈЮЛ,ВЮЪ§ЖўдђЪЧИјГіtagУћ
ДњТыжДааНсЙћШчЯТ
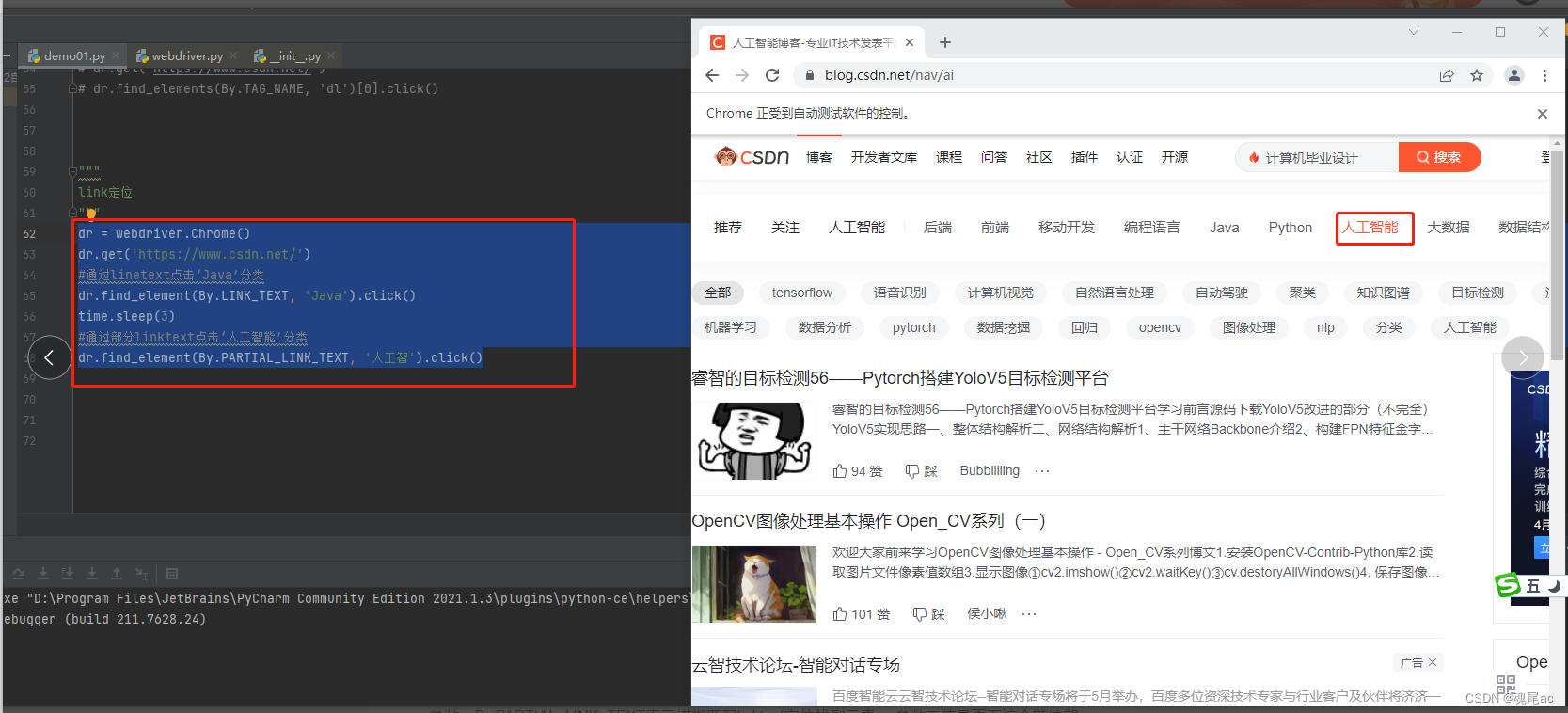
3.5ЁЂLink
????????LinkБэЪОАќКЌгаЪєадhref = ЁАhttps://www.xxxxxxx.comЁБдЊЫи,ПЩвдЭЈЙ§linktextЖЈЮЛ,linktextЪЧвГУцЩЯеЙЪОЕФЮФзжЁЃЫќЛЙПЩвдВПЗжlinktextЖЈЮЛЁЃ
ЭјЩЯКмЖрЮФеТНЋlinktextЭЈЙ§ШЋlinktextгыВПЗжlinktextЧјЗжЮЊСНжжЖЈЮЛЗНЪН,УЛгаБОЮФзюКѓЕФJSЖЈЮЛЗНЪН,вВЪЧЖдЕФЁЃ
ОйР§:
НјШыCSDN,ЕуЛїЗжРр
ЪЙгУF12ВщПДCSDNЕФHTML,ЗЂЯжЗжРрЖМЪЧгаhrefЪєадЕФ,ПЩвдгУlinktextЖЈЮЛ
ЫљвдДњТыБраДШчЯТ:
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
#ЭЈЙ§linetextЕуЛїЁЎJavaЁЏЗжРр
dr.find_element(By.LINK_TEXT, 'Java').click()
time.sleep(3)
#ЭЈЙ§ВПЗжlinktextЕуЛїЁЎШЫЙЄжЧФмЁЏЗжРр
dr.find_element(By.PARTIAL_LINK_TEXT, 'ШЫЙЄжЧ').click()ВЮЪ§вЛBy.LINK_TEXTБэЪОШЋВПЦЅХфlinktextЖЈЮЛевЕНдЊЫи,ВЮЪ§ЖўжЕЪЧвГУцетИіСДНгЕФШЋВПЮФАИЁЎJavaЁЏ
ВЮЪ§вЛBy.PARTIAL_LINK_TEXTБэЪОФЃК§ЦЅХфlinktextЖЈЮЛевЕНдЊЫи ,ВЮЪ§ЖўжЕЪЧвГУцетИіСДНгВПЗжЮФАИЁЎШЫЙЄжЧЁЏ
ДњТыжДааНсЙћШчЯТ
3.6ЁЂxpath
????????xpathЪЧXMLТЗОЖЖЈЮЛЦї,HTMLгыXMLЯрЫЦ,ЫљвдвВПЩвдгУxpathРДЖЈЮЛ,етИіЯрЖдгкЧАУцЕФРДЫЕ,ашвЊДѓМвеЦЮевЛаЉxpathЕФРэТлжЊЪЖЁЃ
| БэДяЪН | УшЪі |
| nodename | бЁШЁДЫНкЕуЕФЫљгазгНкЕу |
| / | ДгЕБЧАНкЕубЁШЁжБНгзгНкЕу |
| // | ДгЕБЧАНкЕубЁШЁзгЫяНкЕу |
| . | бЁШЁЕБЧАНкЕу |
| . . | бЁШЁЕБЧАНкЕуЕФИИНкЕу |
| @ | бЁШЁЪєад |
| * | ШЮКЮдЊЫи |
???
?????? xpathЖЈЮЛТпМЪЧЭЈЙ§idЁЂnameЁЂclassЕШЪєадЖЈЮЛЕНвЛИіДѓЗЖЮЇдЊЫиШЛКѓдйЭЈЙ§ТЗ ОЖ ЖЈЮЛЕНОЋзМдЊЫи;еыЖдЖЈЮЛЕНЖрИідЊЫиЪБвВПЩвдЯТБъШЁжЕ,ЕЋЯТБъДг1ПЊЪМЁЃПЩвд гУ xpathЖЈЮЛЕНШЮКЮдЊЫи
БэИёЕФФкШнХЊЖЎКѓ,ЕЋВЂВЛвЛЖЈЛсгУЕН,ЖЎСЫЪЧШУздМКжЊЕРxpathЪЧШчКЮЖЈЮЛЕФ;ЪЕеНжаЛљБОЩЯгУЕНxpathЖЈЮЛЪБ,вЛАуЪЙгУфЏРРЦїf12РяУцcopy xpathЙІФм,ЛёШЁЕНЖдгІдЊЫиЕФxpath(РЯЪжвЛАуЪЧздМКаДxpath,вђЮЊF12гаЪБИДжЦЕФxpathВЛЪЧзюОЋМђЕФ)
БШШчЮввЊЛёШЁCSDNММЪѕЪїдЊЫиЕФxpath,жЛашвЊАДееЯТЭММ§ЭЗЕФЫГађЕуЛї,МДПЩЛёШЁЕНЖдгІЕФxpathСЫ
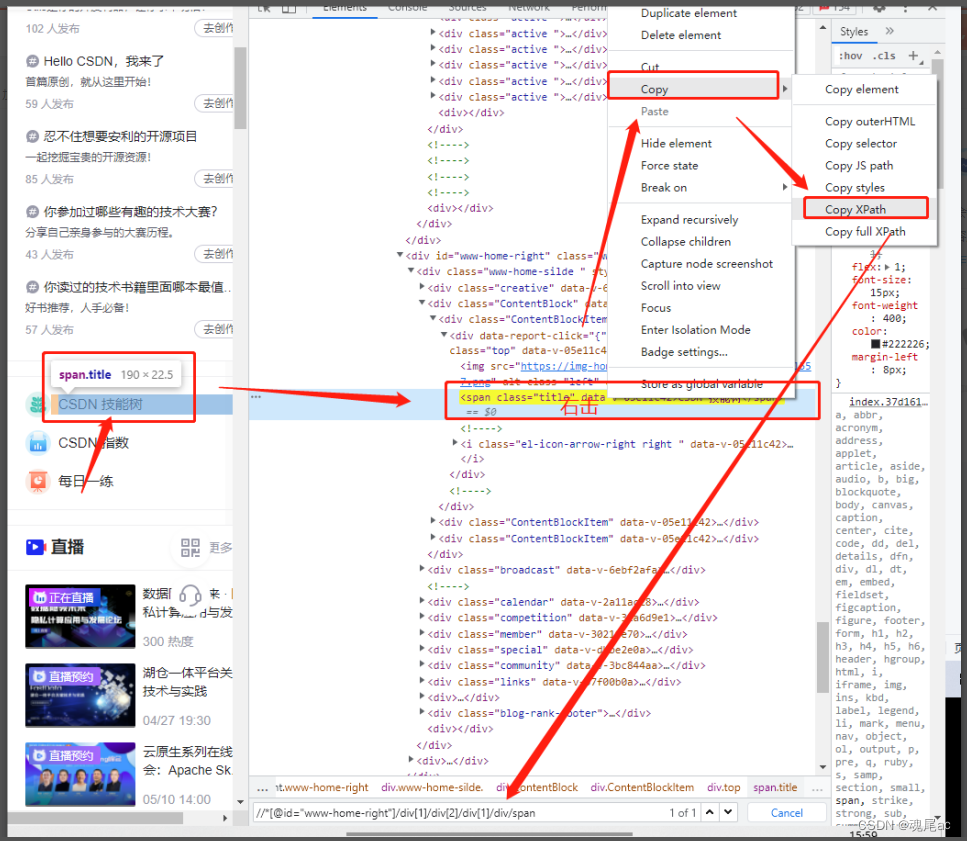
ШЛКѓгУЛљРДОйР§:
ОйР§:
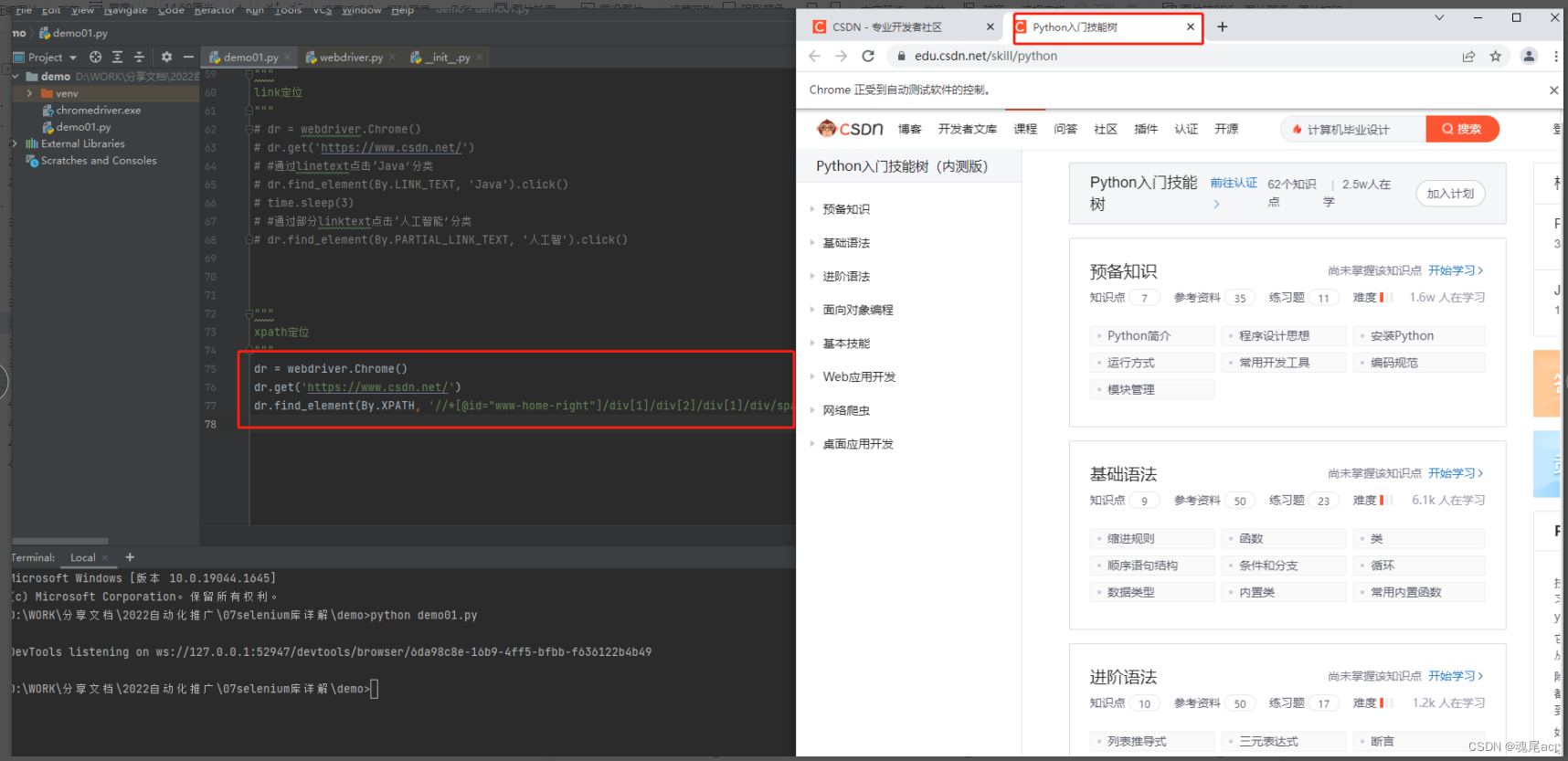
НјШыCSDN,ЕуЛїММФмЪїдЊЫи
ЭЈЙ§F12РяЕФcopy xpathЙІФмПЩвджЊЕРММФмЪїдЊЫиЕФxpathЮЊ//*[@id="www-home-right"]/div[1]/div[2]/div[1]/div/span
ЫљвдДњТыБраДШчЯТ
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.find_element(By.XPATH, '//*[@id="www-home-right"]/div[1]/div[2]/div[1]/div/span').click()ВЮЪ§вЛBy.XPATHБэЪОЪЙгУxpathЗНЪНЖЈЮЛ,ВЮЪ§ЖўЪЧИјдЊЫиxpathжЕ
ДњТыжДааШчЯТ
3.7ЁЂcssбЁдёЦї
????????cssЪЧЧАЖЫбљЪН,етРяЫЕЕФcssЖЈЮЛЪЧгУcssбљЪНРяЖЈЮЛдЊЫигУЕФЗНЗЈНазіcssбЁдёЦїЁЃ
ЗћКХ.ДњБэclass, ?ЗћКХ # ДњБэid, ТЗОЖПеИёаДtagУћ
????????ЫќгыxpathвЛбљ,ПЩвдЖЈЮЛЕНШЮКЮдЊЫи,вВПЩвджБНгЭЈЙ§F12ЕФcopy selectorРДШЁ ЕУдЊЫиЕФcssбЁдёЦї
ОйР§
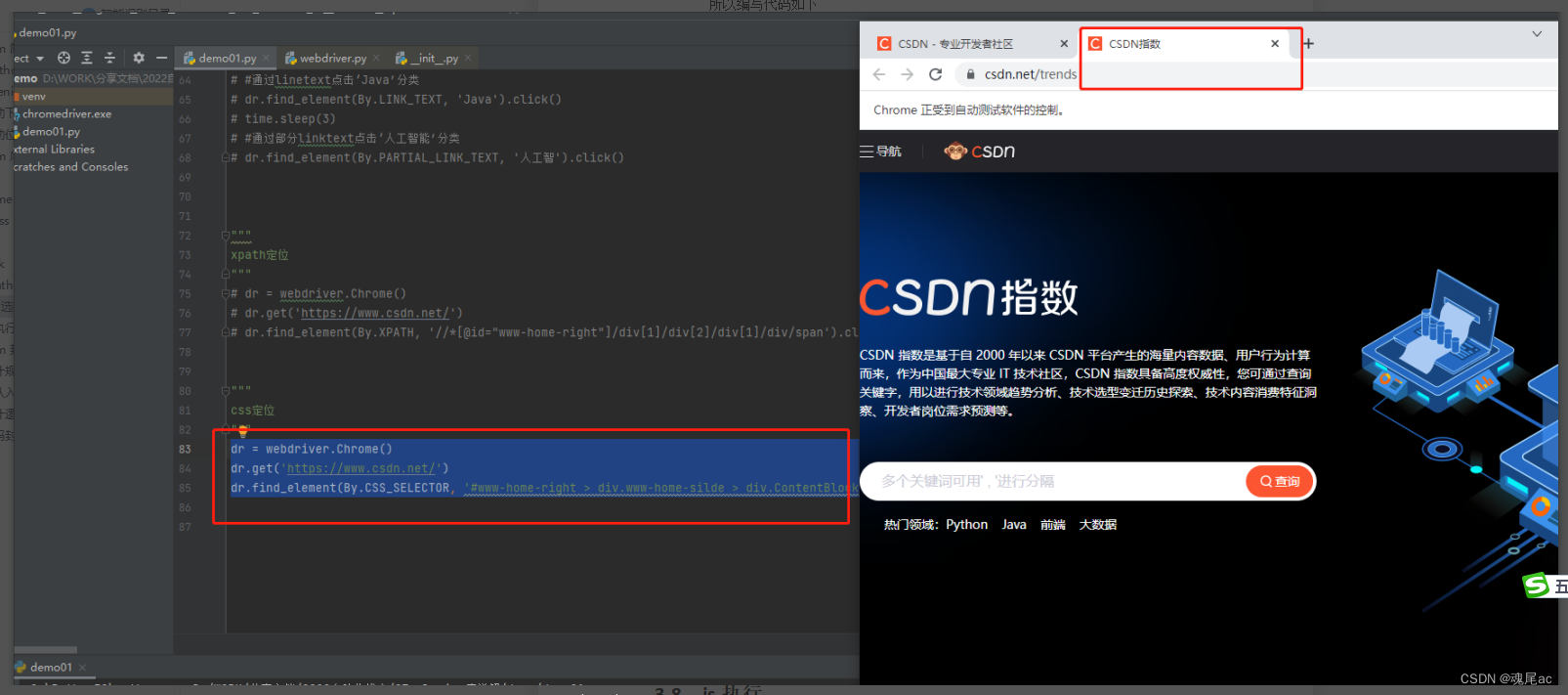
НјШыCSDN, ЕуЛїCSDNжИЪ§дЊЫи
ЭЈЙ§f12РяЕФcopy selectorШЁЕУдЊЫиЕФcssбЁдёЦїЮЊ:#www-home-right > div.www-home-silde > div.ContentBlock > div:nth-child(1) > div > span
ЫљвдДњТыБраДШчЯТ
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.find_element(By.CSS_SELECTOR, '#www-home-right > div.www-home-silde > div.ContentBlock > div:nth-child(2) > div > span').click()ВЮЪ§вЛBy.CSS_SELECTORБэЪОЪЙгУcssЗНЪНЖЈЮЛ,ВЮЪ§ЖўЪЧИјдЊЫиcssбЁдёЦї
ДњТыжДааШчЯТ:
3.8ЁЂjsжДаа
jsВЛЪЧЖЈЮЛЦї
jsВЛЪЧЖЈЮЛЦї
jsВЛЪЧЖЈЮЛЦї
jsЪЧjavascript,ЪЧПЩвдЖРвддЫааЕФНХБО;ВЛЪЙгУseleniumЕФЗНЗЈ,НјаавГУцдЊЫиЕФЕуЛїЁЂЪфШыЁЂЭЯзЇЕШЕШВйзї,ЯёШчЙћЖдjsЪЙгУКмЪьСЗ,ФЧУДвВОЭЭъШЋВЛашвЊЙмЩЯУцЕФЖЈЮЛЗНЪНЁЃШЋВППЩвдЪЙгУjsРДЪЕЯжвГУцдЊЫиЕФИїжжВйзїЁЃ
ЯёЙіЖЏЬѕЭЯзЇЪЧУЛЗЈгУдЊЫиЖЈЮЛВйзїЕФ,жЛФмЪЙгУjs
ОйР§:(аТЪжОЕфЮЪЬт)
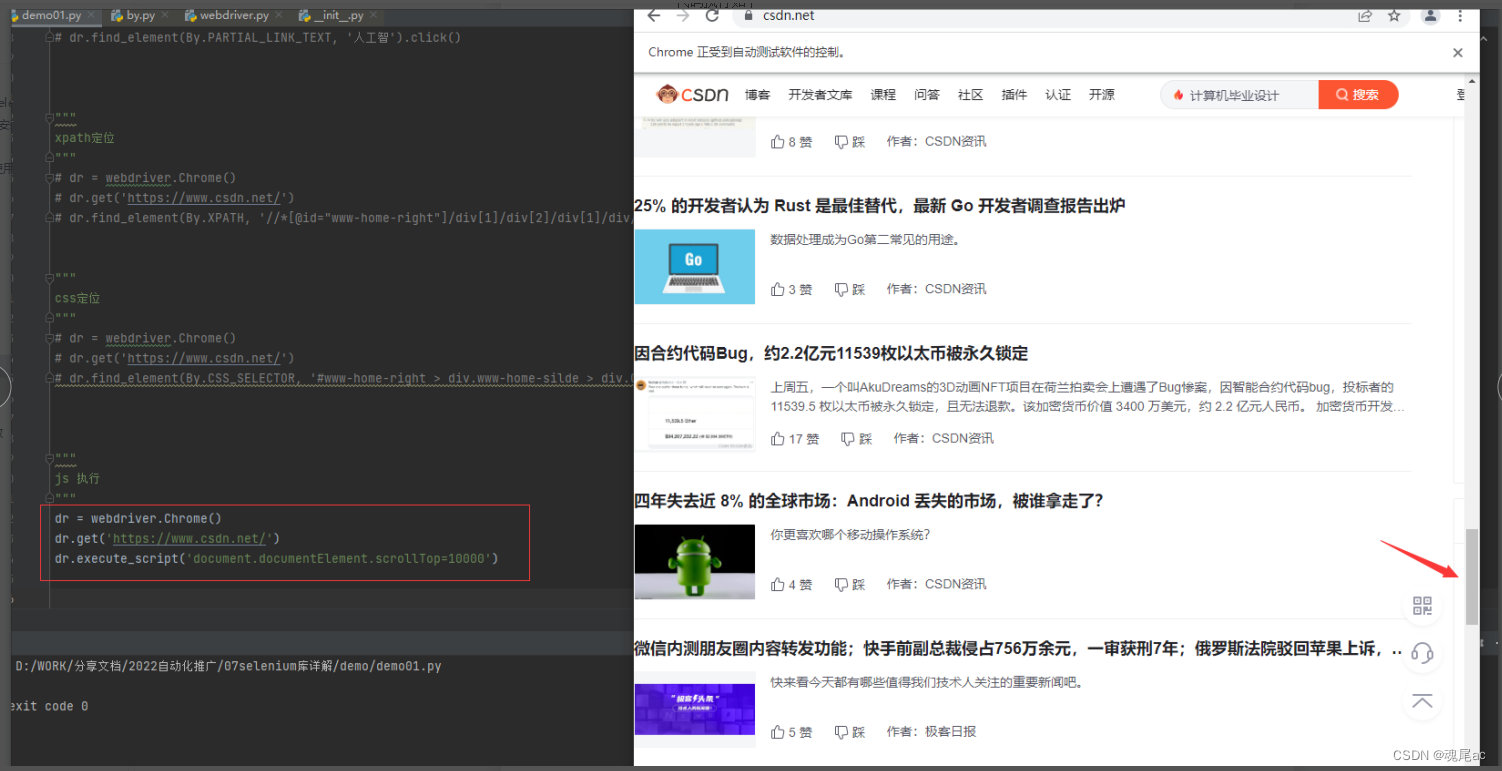
НјШыCSDN,ЭЯзЇЙіЖЏЬѕ
ЙіЖЏЬѕЭЯзЇЕФjsЮЊdocument.documentElement.scrollTop=10000
ДњТыБраДШчЯТ
dr = webdriver.Chrome()
dr.get('https://www.csdn.net/')
dr.execute_script('document.documentElement.scrollTop=10000')ЪЙгУexeute_scriptжДааJS?
ДњТыжДааШчЯТ
4ЁЂseleniumЗтзА
????????ЩЯУцНВСЫseleniumАЫДѓдЊЫиЖЈЮЛЗНЪН,ЕЋзіздЖЏЛЏПЯЖЈВЛЪЧвЛжБаДетбљЕФpythonДњТы,вђЮЊЪБМфгыПеМфЩЯЖМРЫЗбШЫСІ,ВЛШчЙІФмВтЪд,ЫљвдЮвУЧашвЊбЇЛсШЅЖўДЮЗтзАseleniumЁЃНЋЦфжЦЖЈГЩЙцдђЛЏЕФздШЛДњТыРДШУздЖЏЛЏБфЕУМђЕЅвзЖЎЁЃ
4.1ЁЂЩшМЦЙцдђ
вЛЁЂзіздЖЏЛЏЪЧФЃФтШЫЕФВйзї,ЫљвдгаВйзїзжЖЮ:ЕуЛїЁЂЪфШыЕШ
ЖўЁЂЖЈЮЛдЊЫиашвЊЖЈЮЛЗНЪН,ЫљвдгаЖЈЮЛЦїзжЖЮ:idЁЂnameЁЂclassЁЂtagЁЂlinkЁЂplinkЁЂxpathЁЂcssЁЂjs
Ш§ЁЂЖЈЮЛЦїгаСЫ,ЖЈЮЛЦїЕФЖдЯѓзжЖЮвВвЊга
ЫФЁЂвГУцЯрЭЌЪєадЕФдЊЫигаЖрИі,ЫљвдашвЊвЛИіЯТБъзжЖЮ
ЮхЁЂЪфШыЁЂЯТРЁЂМьВщашвЊжЕ,ЫљвджЕзжЖЮвВашвЊвЛИі
ЛљБОЩЯднЪБПЩвдЯШШЗЖЈетаЉзжЖЮ:
operationЁЂtypeЁЂlocatuionЁЂindexЁЂvalue
4.2ЁЂШЗШЯШыПкКЏЪ§
ЩшМЦКУЮхИіВЮЪ§Кѓ,ЛљБОЩЯВйзїОЭжЛашвЊетЮхИіВЮЪ§СЫ,ЫљвдашвЊвЛИіЭГвЛШыПкКЏЪ§,НЋетЮхИіВЮЪ§ОљДјШыЦфЪЕЁЃ
def web_autotest_opr(operation, type, locatuion, index, value)
4.3ЁЂЩшМЦТпМ
вЛЁЂЗтзАфЏРРЦїДђПЊЙІФм,ЗЕЛифЏРРЦїЖдЯѓ
ЖўЁЂЗтзАШыПкКЏЪ§
Ш§ЁЂЗтзАЖЈЮЛдЊЫиЗНЪН
ЫФЁЂЗтзАдЊЫиВйзїЗНЪН
4.4ЁЂДњТыЗтзА
from selenium import webdriver
from selenium.webdriver.common.by import By
def open_url(url):
????'''
????ДђПЊфЏРРЫГЗУЮЪurl,ВЂЗЕЛифЏЦїВйзїОфБњ
????:param url: вЊВтЪдЕФЭјеОurl
????:return: webdriverЖдЯё
????'''
????opr = webdriver.Chrome()
????opr.get(url)
????return opr
def get_element(opr:webdriver.Chrome, type, locatuion, index):
????'''
????ЛёШЁдЊЫиВЂЗЕЛи
????:param opr: фЏРРЦїОфБњ
????:param type: ЖЈЮЛЦїРраЭ
????:param locatuion: ЖЈЮЛЦї
????:param index: ЯТБъ
????:return: дЊЫиЖдЯѓ
????'''
????if str.lower(type) == 'id':
????????return opr.find_elements(By.ID, locatuion)[index]
????elif str.lower(type) == 'name':
????????return opr.find_elements(By.NAME, locatuion)[index]
????elif str.lower(type) == 'class':
????????return opr.find_elements(By.CLASS_NAME, locatuion)[index]
????elif str.lower(type) == 'tag':
????????return opr.find_elements(By.TAG_NAME, locatuion)[index]
????elif str.lower(type) == 'link':
????????return opr.find_elements(By.LINK_TEXT, locatuion)[index]
????elif str.lower(type) == 'plink':
????????return opr.find_elements(By.PARTIAL_LINK_TEXT, locatuion)[index]
????elif str.lower(type) == 'xpath':
????????return opr.find_elements(By.XPATH, locatuion)[index]
????elif str.lower(type) == 'css':
????????return opr.find_elements(By.CSS_SELECTOR, locatuion)[index]
def element_opr(el:webdriver.Chrome.find_element, operation, value):
????'''
????дЊЫиВйзї
????:param el: дЊЫиЖдЯѓ
????:param operation: ВйзїРраЭ
????:param value: жЕ
????:return: ГЩЙІ(True)orЪЇАм(False)
????'''
????if operation == 'ЕуЛї':
????????el.click()
????????return True
????elif operation == 'ЪфШы':
????????el.send_keys(value)
????????return True
def web_autotest_opr(opr:webdriver.Chrome ,operation, type, locatuion, index=0, value=''):
????'''
????дЊЫиВйзїЭГвЛШыПк
????:param opr: фЏРРЦїОфБњ
????:param operation: ВйзїРраЭ
????:param type: ЖЈЮЛЦїРраЭ
????:param locatuion: ЖЈЮЛЦї
????:param index: ЯТБъ
????:param value: жЕ
????:return: ГЩЙІ(True)orЪЇАм(False)
????'''
????if str.lower(type) != 'js':
????????el = get_element(opr, type, locatuion, index)
????????result = element_opr(el, operation, value)
????else:
????????result = opr.execute_script(locatuion)
????return result
етвЛВПЗжЪєгкUIздЖЏЛЏВтЪдПђМмЕФКЫаФВПЗжЕФЗтзА,ЕБШЛТпМПЯЖЈВЛжЙетаЉ,ВЂЧвЩЯУцетаЉДњТыЪЧУцЯђЙ§ГЬЕФ,ЕШДѓМвгаЪЕСІСЫ,ПЩвдТ§Т§гХЛЏетаЉДњТы,ОЁСПБфГЩУцЯђЖдЯѓЕФЁЃ

