基于Windows安装langconv实现繁体和简体字的转换
在学习自然语言处理的时候,大家可能已经发现有些中文数据集是繁体字,那么当我们的任务需求是输出简体字时就需要对原始中文数据集进行字体转换,达到顺利输出的目的。
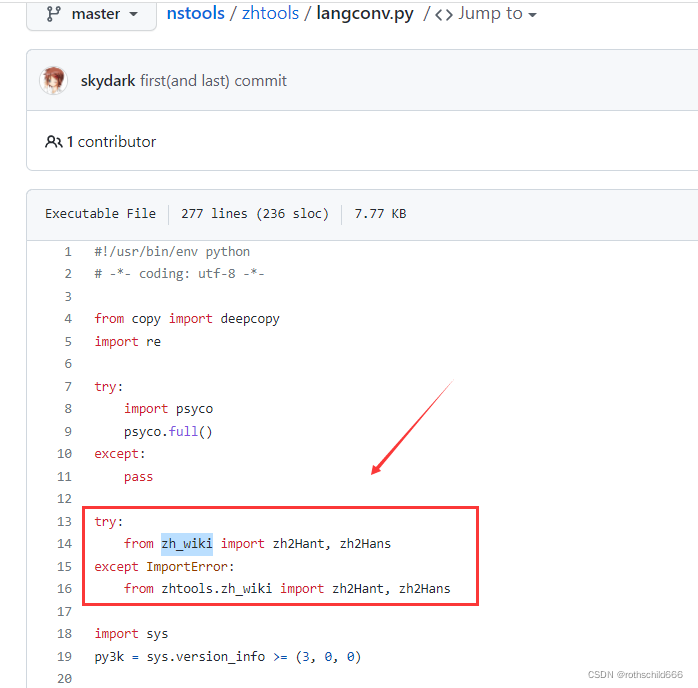
一、点击下面的链接打开对应的安装包的网页。注意:为什么要下载zh_wiki文件,原因是langconv文件内的代码需要用到(见下面第三张图)。
- zh_wiki.py文件:zh_wiki.py文件
- langconv.py文件:langconv.py文件
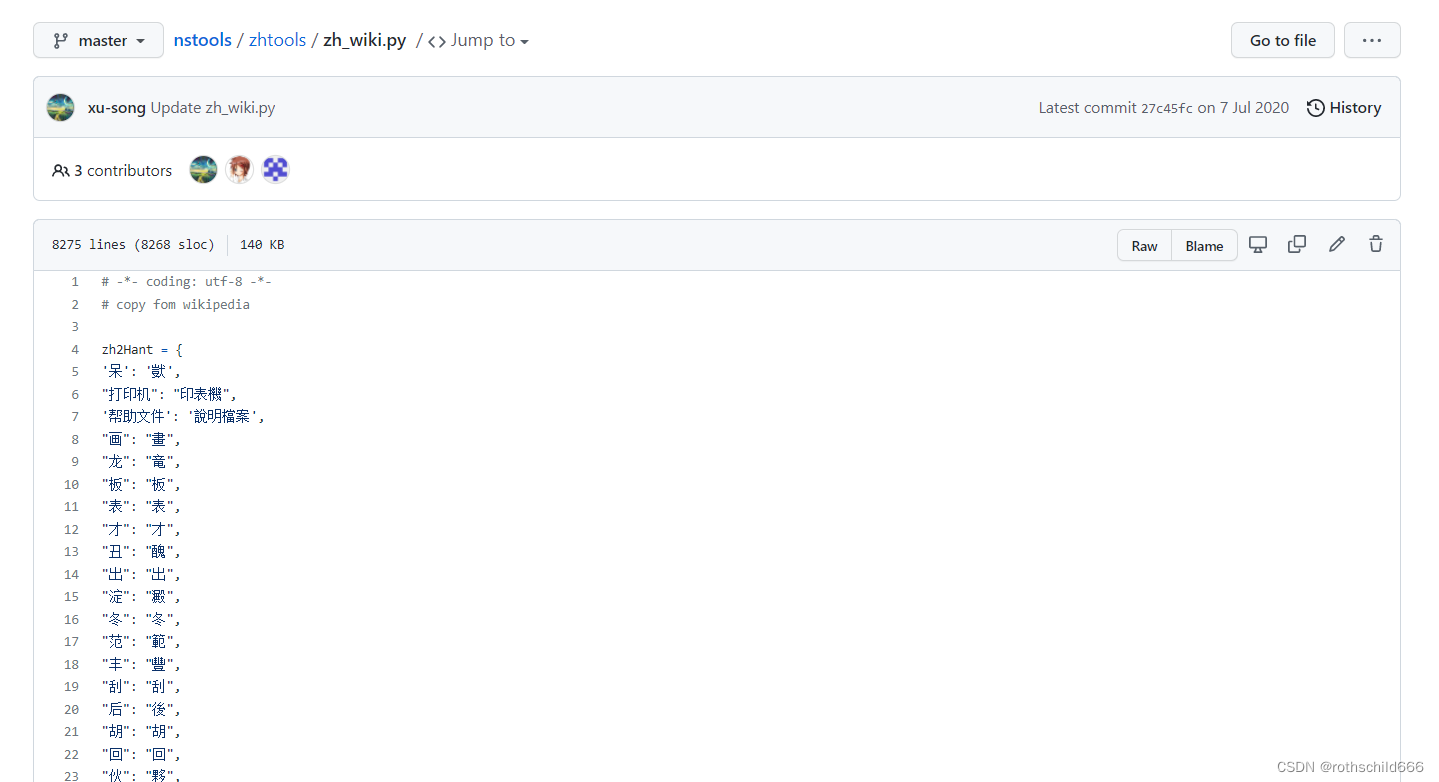
二、对应分别都点击“raw”。

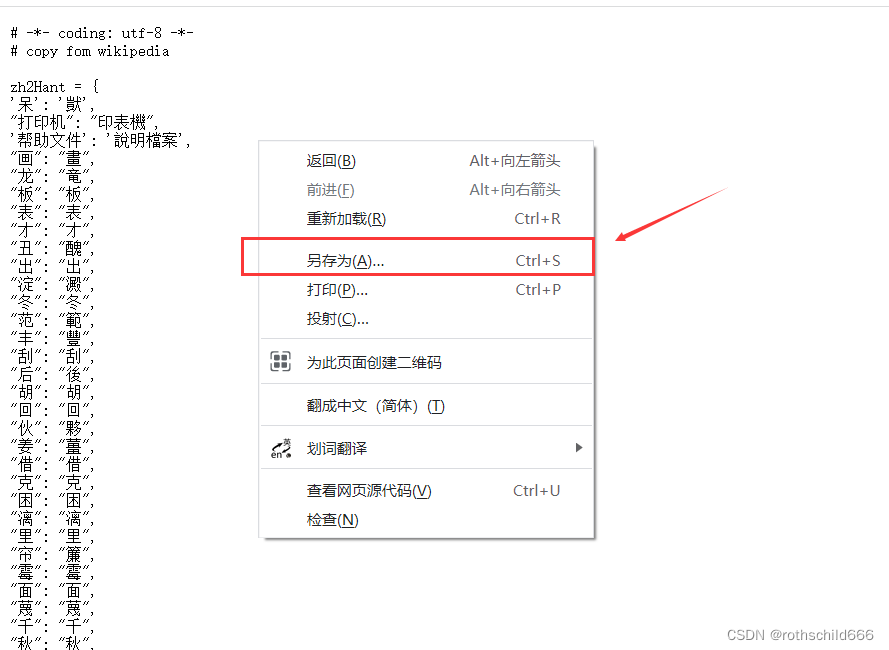
三、然后分别都再右击鼠标点击“另存为…”。
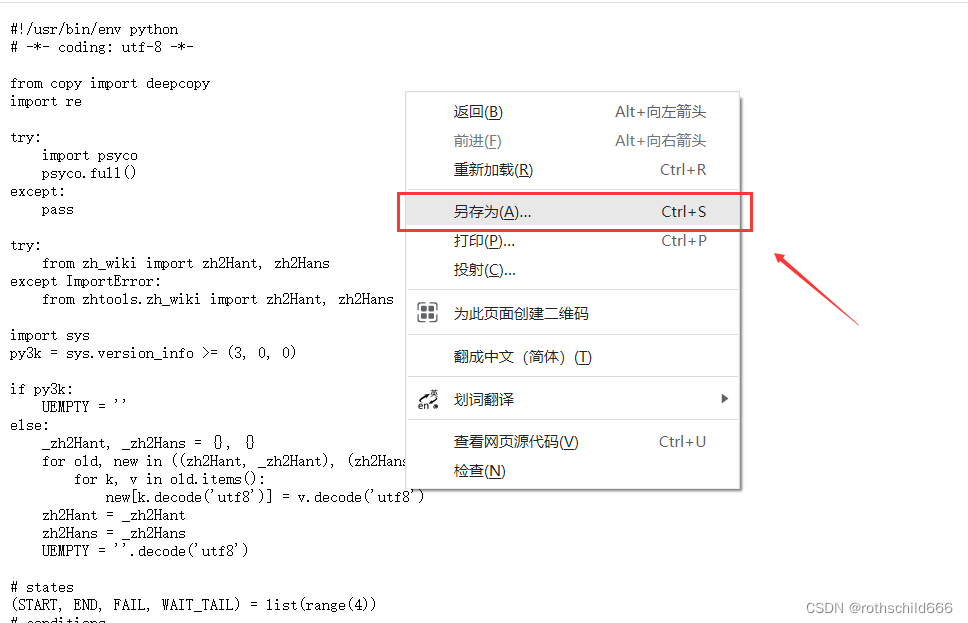
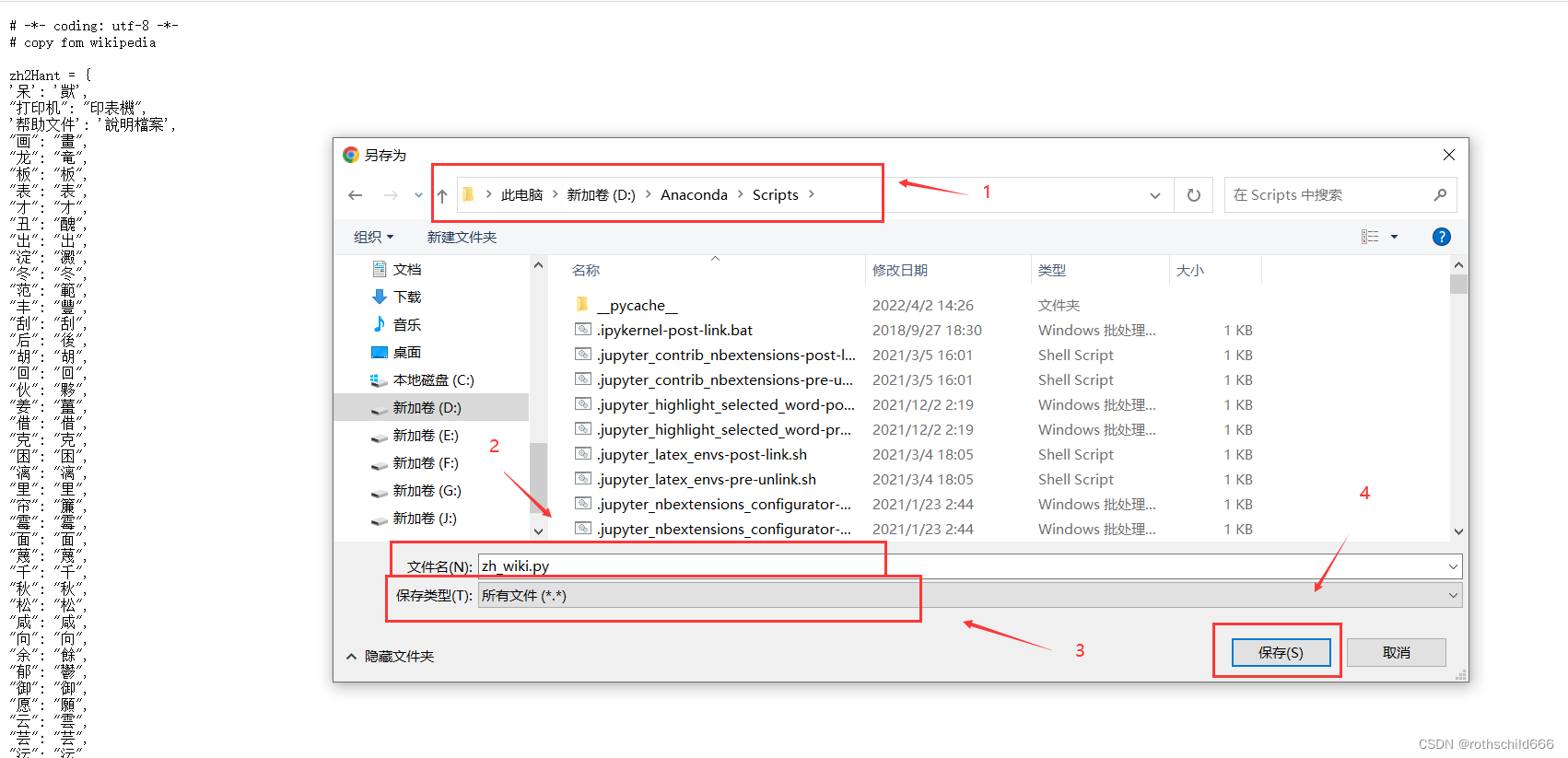
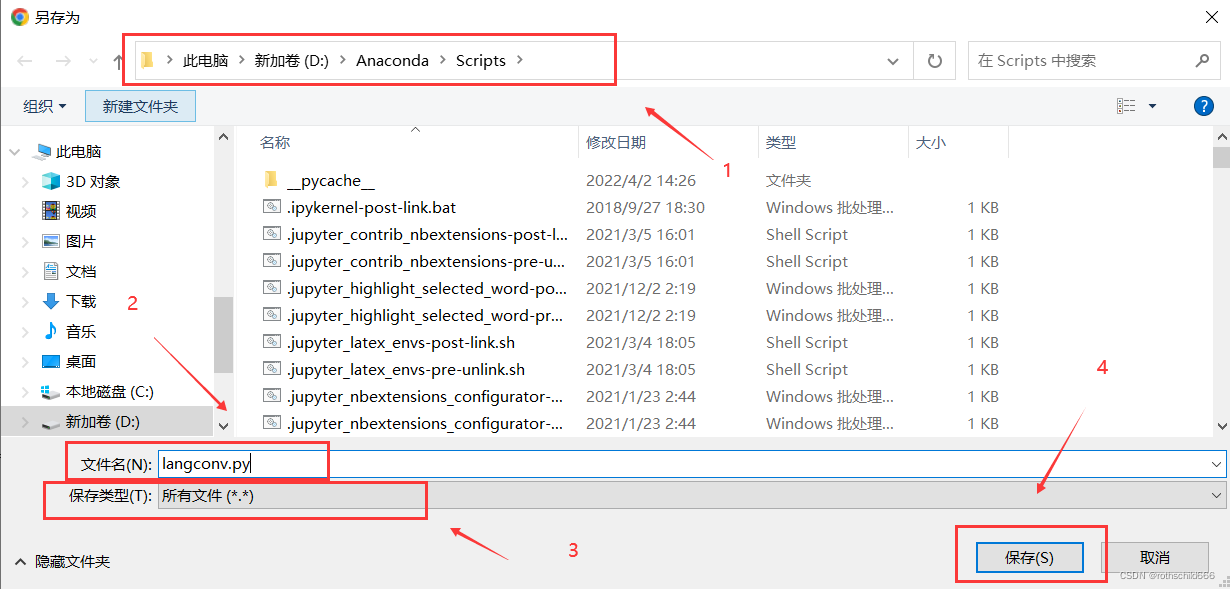
四、然后弹出另保存的新弹框后,首先选择文件保存的路径,选择安装到你需要使用这个功能的python项目的路径(建议选择此种方式),当然不听话的你也可以随便保存到自己想放置此文件的路径(比如:博主放到“D:\Anaconda\Scripts”路径,需要时使用sys这个python库即可,见下面代码),然后将文件名去掉默认的后缀“.txt”,然后保存类型选择“所有文件”,最后点击“保存”,然后等待十秒下载完成。
import sys
from sys import path
path.append(r'D:\Anaconda\Scripts') # 项目中添加langconv文件的路径,注意要放在import前

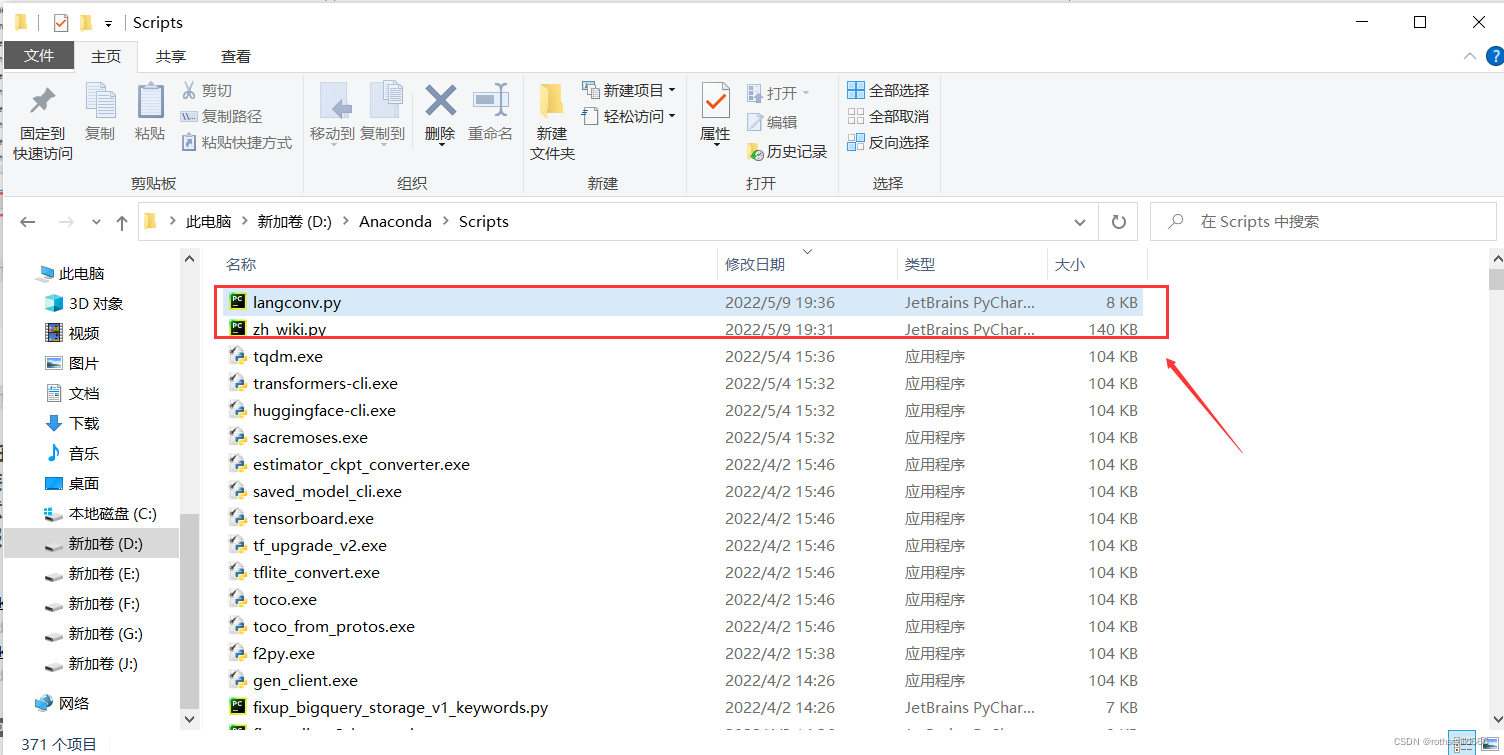
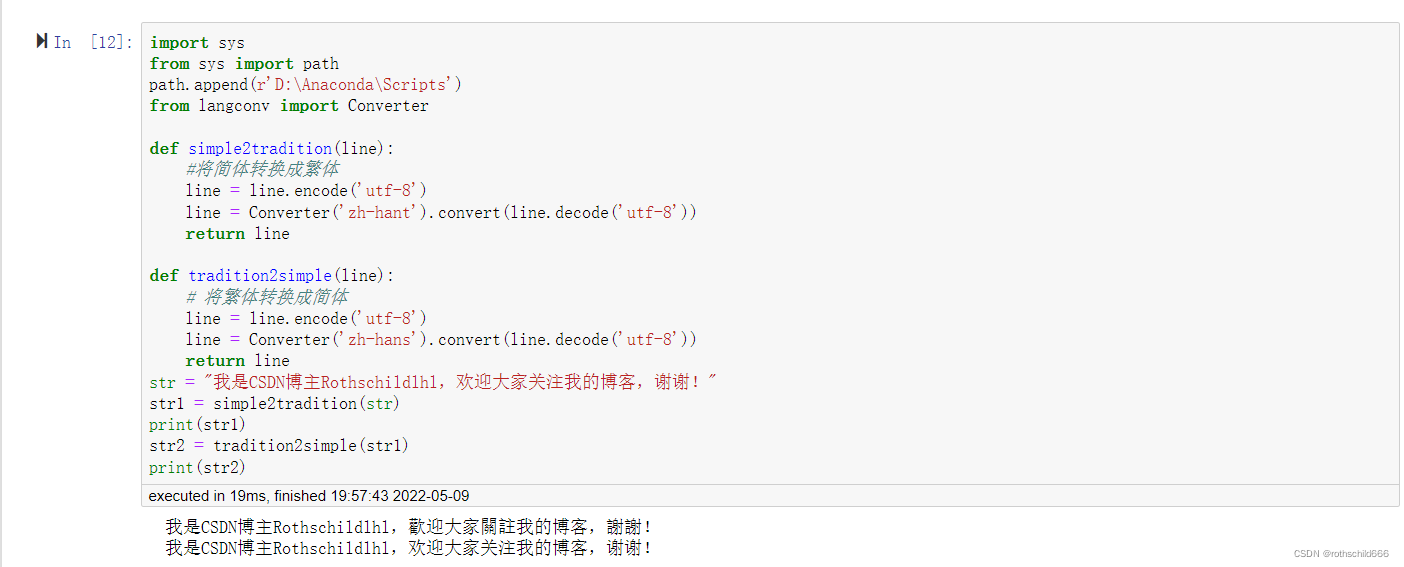
五、复制下面代码在jupyter notebook上运行,若没有安装软件可以参考博主下面两篇文章进行安装,运行结果如下图所示则表示安装langconv实现繁体和简体字的转换成功。注意:字符串不能先进行decode解码,要先encode编码再解码,否则运行程序会报错。
import sys
from sys import path
path.append(r'D:\Anaconda\Scripts')
from langconv import Converter
def simple2tradition(line):
#将简体转换成繁体
line = line.encode('utf-8')
line = Converter('zh-hant').convert(line.decode('utf-8'))
return line
def tradition2simple(line):
# 将繁体转换成简体
line = line.encode('utf-8')
line = Converter('zh-hans').convert(line.decode('utf-8'))
return line
str = "我是CSDN博主Rothschildlhl,欢迎大家关注我的博客,谢谢!"
str1 = simple2tradition(str)
print(str1)
str2 = tradition2simple(str1)
print(str2)