import numpy as np
import pandas as pd
path=r"C:\Users\Tsinghua-yincheng\Desktop\SZday74"
pop=pd.read_csv(path+"\\"+"state-population.csv")
areas=pd.read_csv(path+"\\"+"state-areas.csv")
abbrevs=pd.read_csv(path+"\\"+"state-abbrevs.csv")
pop.head(5)
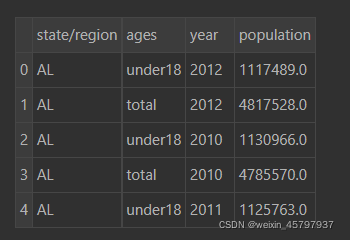
areas.head(5)

abbrevs.head(5)

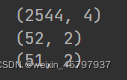
display(pop.shape,areas.shape,abbrevs.shape)
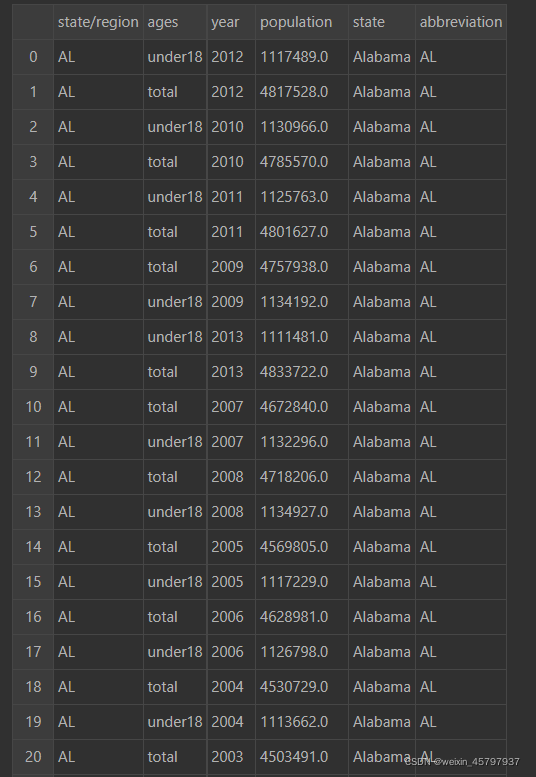
merged=pd.merge(pop,abbrevs,how="outer",
left_on="state/region",
right_on="abbreviation")
merged
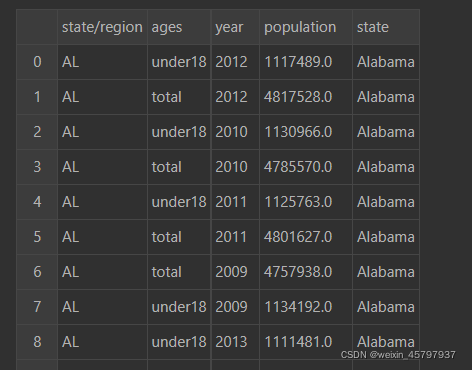
merged=merged.drop("abbreviation",axis=1)
merged
merged.isnull().any()
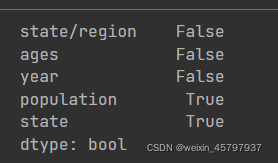
merged[merged["population"].isnull()]
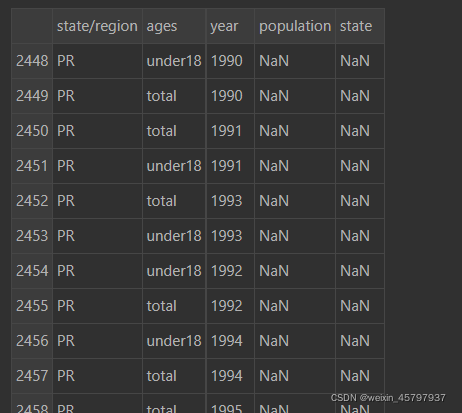
merged.loc[merged["state"].isnull(),"state/region"]

merged.loc[merged["state"].isnull(),"state/region"].unique()

merged.loc[merged["state/region"]=="PR","state"]="Puerto Rico"
merged.loc[merged["state/region"]=="USA","state"]=\
"United States"
merged.isnull().any()
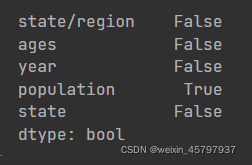
merged
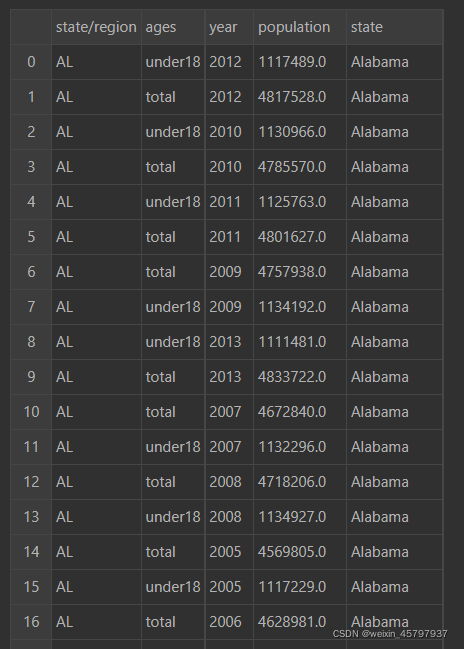
final=pd.merge(merged,areas,on="state",how="left")
final
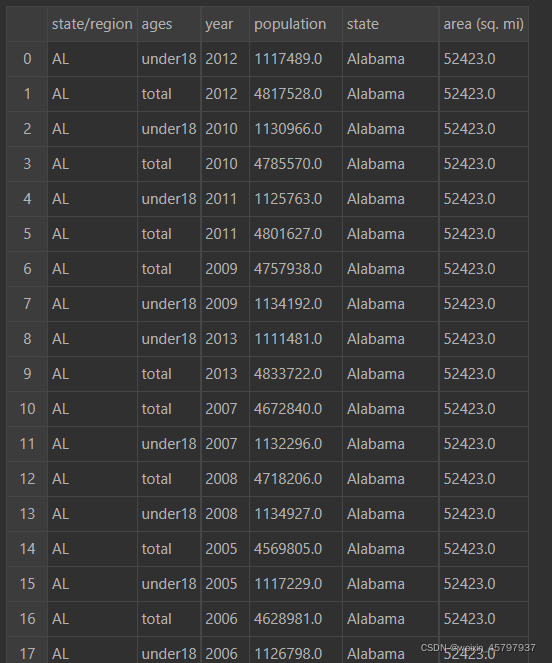
final.shape
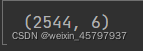
final.isnull().any()
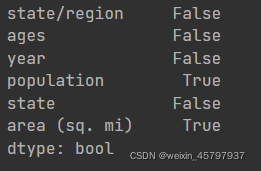
final["state"][final["area (sq. mi)"].isnull()]
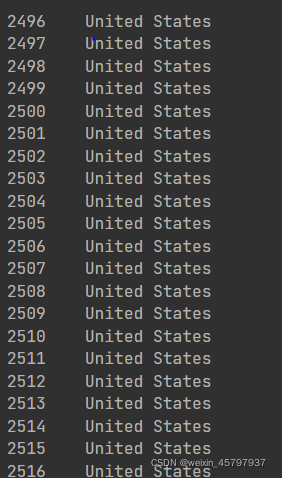
final["state"][final["area (sq. mi)"].isnull()].unique()

final.dropna(inplace=True)
final
final.isnull().any()
final
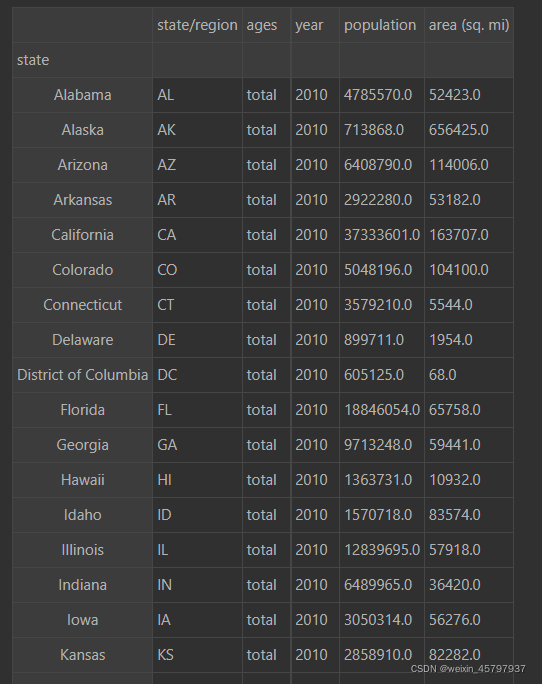
data2010=final.query("year==2010 & ages=='total'")
data2010
data2010.shape
data2010.set_index("state",inplace=True)
data2010
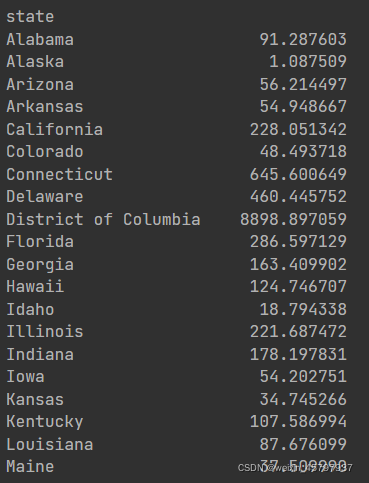
density=data2010["population"].div(data2010["area (sq. mi)"])
density
density.sort_values(ascending=False,inplace=True)
density.head(10)
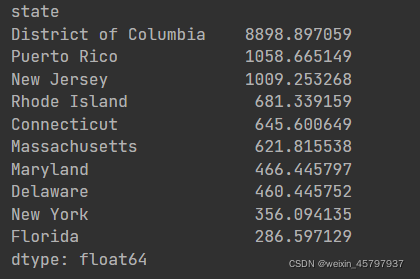
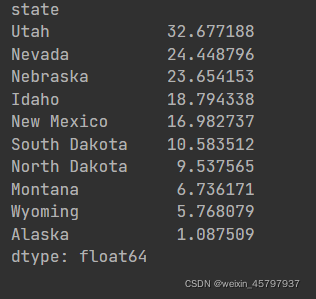
density.tail(10)
| 
