1 检测零售信用额度违约示例
SkopeRules找到高精度的逻辑规则并融合它们。通过将分类和回归树拟合到子样本来完成查找良好的规则。拟合树定义一组规则(每个树节点定义一个规则);然后从袋子里测试规则,并保留精度更高的规则。
原文链接

2 示例例代码获取
选择自己使用的平台代码下载下来即可。

3 代码迁移问题
我用的是pycharm2020.2.3+python3.9+sklearn1.0.2,实例代码用的sklearn是0.22左右的版本,运行报错了。以下是我解决版本不匹配时用的方法:
根据运行报错位置,重点修改的是credit_data.py里面的代码:

首先是模块导入部分
import pandas as pd
import numpy as np
from sklearn.datasets.base import get_data_home, Bunch
from sklearn.datasets.base import _fetch_remote, RemoteFileMetadata
from os.path import exists, join
修改为:
import pandas as pd
import numpy as np
from sklearn.datasets import load_files
from sklearn.utils import Bunch
其次根据函数里面的url找到我们需要用到的数据集:信用卡数据集
url='https://archive.ics.uci.edu/ml/machine-learning-databases/'
'00350/default%20of%20credit%20card%20clients.xls',
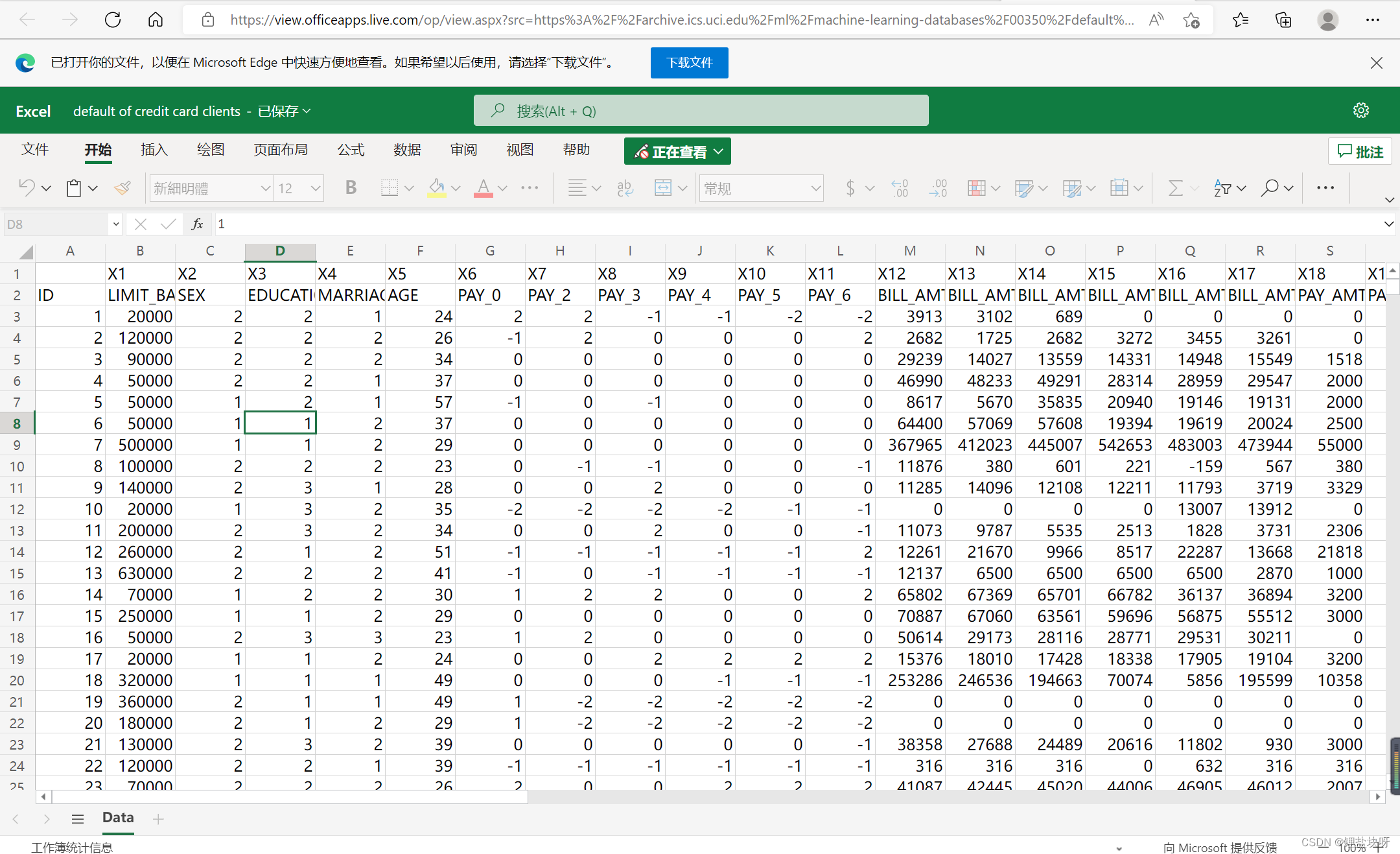
下载保存下来以后就可以将远程获取数据集简化为指定路径读取数据集:
def load_credit_data():
data = pd.read_excel('E:\\My Word\\Downloads\\auto_examples_python\\credit.xls', header=1)
dataset = Bunch(
data=(data.drop('default payment next month', axis=1)),
target=np.array(data['default payment next month'])
)
return dataset
修改完以后回到最开始的plot_credit_default.py文件里control+shift+F10就可以了,运行时间跟官网说的差不多,2分钟左右(官网说的是1 分 53.372 秒)。
4 总结
说明文档是一个好东西:sklearn-API说明文档入口。
求知的时候要尽自己最大的努力追根溯源地去求证,不能不假思索地希望答案能够从天而降,一开始可能要经过一个随机试验(乱试)的经历,有点艰难。感谢这篇博客给予我的灵感:sklearn中模块包的导入报错,通用解决办法。

