?�������ʽ������֤��վ
regex101: build, test, and debug regex
Ŀ¼
9��������? ?��ʾҪƥ�� ָ���ļ����ַ�֮һ
?10����ʼ����βλ�� �� ���С�����ģʽ
?2��?finditer? ���ص���һ��������
һ���������ʽ
1��. ƥ���ַ�
.? ���Ա�ʾ�����з�֮����������ⵥ���ַ���
������ı�,ѡȡ�����е���ɫ
ƻ������ɫ��
�����dz�ɫ��
�㽶�ǻ�ɫ��
��ѻ�Ǻ�ɫ���Ϳ���ʹ��? .ɫ����ƥ��? ����:

��д python�������� :
import re
content = """
ƻ������ɫ��
�����dz�ɫ��
�㽶�ǻ�ɫ��
��ѻ�Ǻ�ɫ��
"""
# r �Ƿ�ֹת��
p = re.compile(r'.ɫ')
for i in p.findall(content):
print(i)
?�������:
D:\pythontest\plane\venv\Scripts\python.exe D:/pythontest/plane/�������ʽ/test1.py
��ɫ
��ɫ
��ɫ
��ɫ
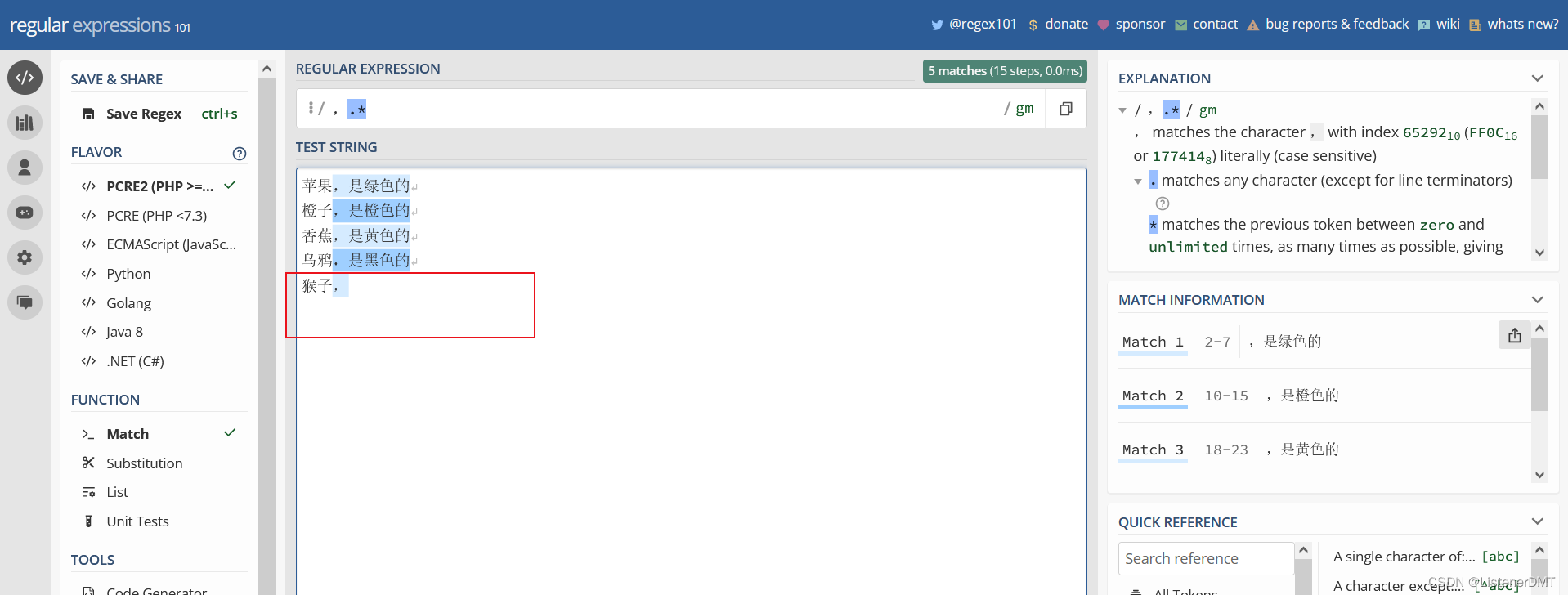
2�� *? ��ʾ�ظ�ƥ�������
*��ʾƥ��ǰ����ӱ���ʽ�����,����0�Ρ�����,��Ҫ��������ı���,ѡ��ÿ�ж��ź�����ַ�������,�������ű�����
ƻ��,����ɫ��
����,�dz�ɫ��
�㽶,�ǻ�ɫ��
��ѻ,�Ǻ�ɫ��
����,�Ϳ�������д�������ʽ
,.*������ . ����, ��ʾ �����ַ����Գ��������, ������������ʽ����˼�����ڶ��ź���� �����ַ�,��������
��֤����:
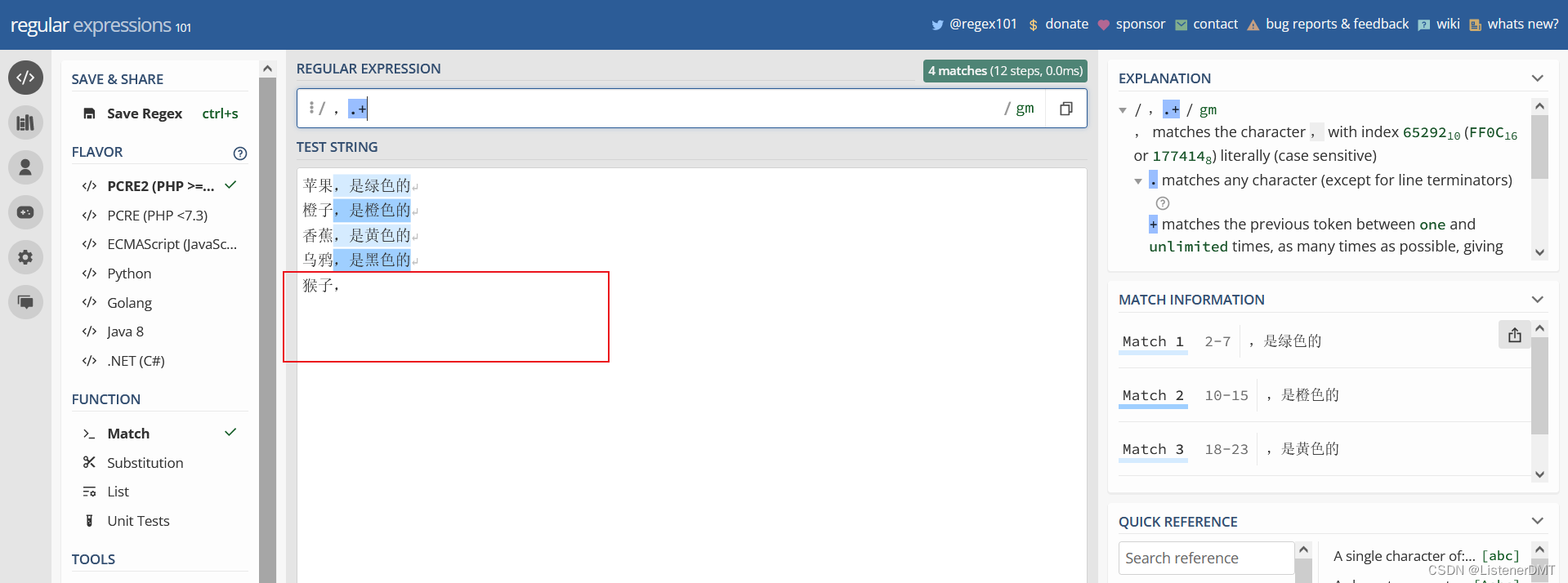
?3��+?�ظ�ƥ����? ,������0��
����? 2?������??
?4���ʺ�? ƥ�� 0 - 1? ��

5��������? ָ��ƥ�����
�����ű�ʾ ǰ����ַ�ƥ��
ָ���Ĵ��������� ,������ı�
��ͮͮ,������,�ں���,����������
����ʽ
��{3}�ͱ�ʾƥ�� ������ �� �� 3������ʽ
��{3,4}�ͱ�ʾƥ�� ������ �� �� ����3��,���� 4 ����ֻ��ƥ�� �����,������ʾ

?6��̰��ģʽ�ͷ�̰��ģʽ
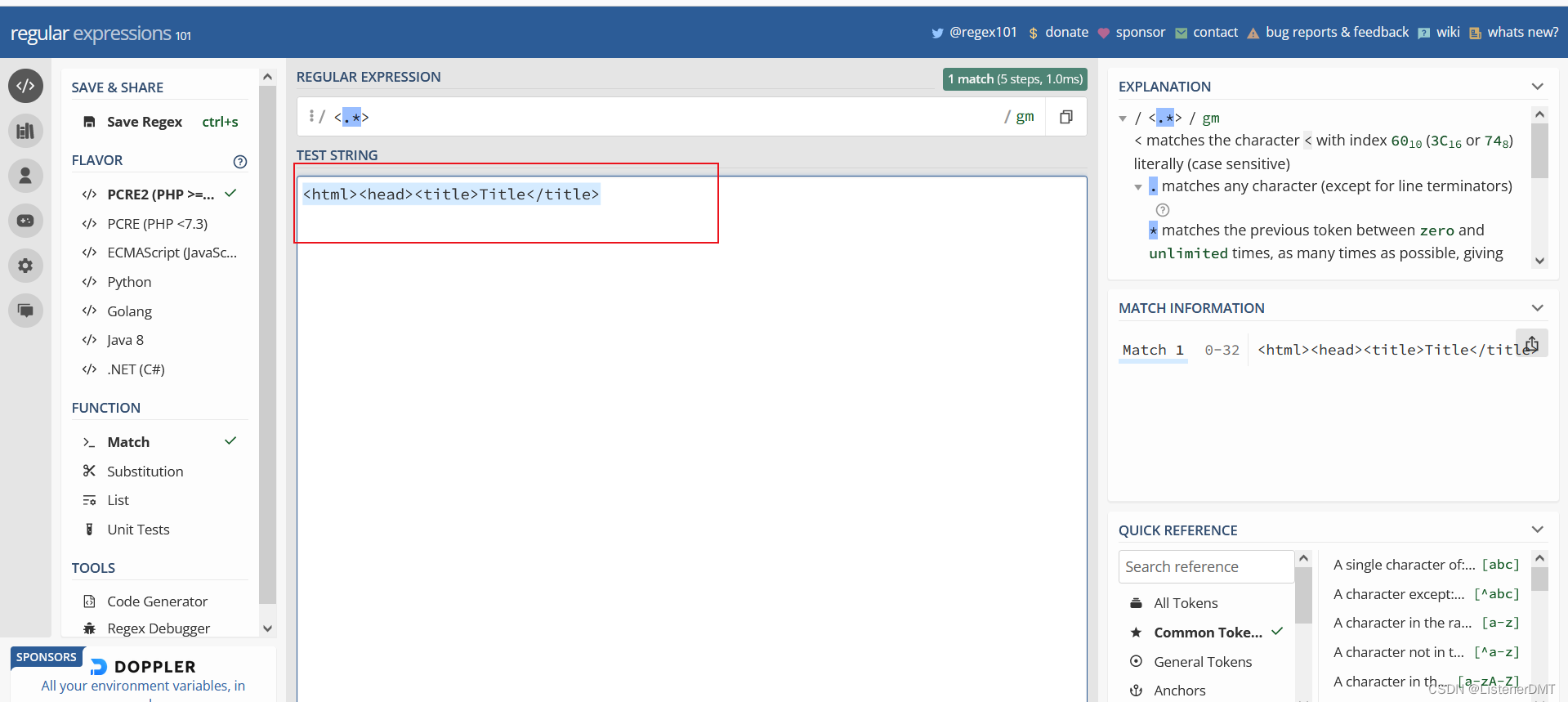
����Ҫ��������ַ����е�����html��ǩ����ȡ����,
source = '<html><head><title>Title</title>'
�õ�������һ���б�
['<html>', '<head>', '<title>', '</title>']
�������뵽ʹ���������ʽ <.*>
��������ƥ��
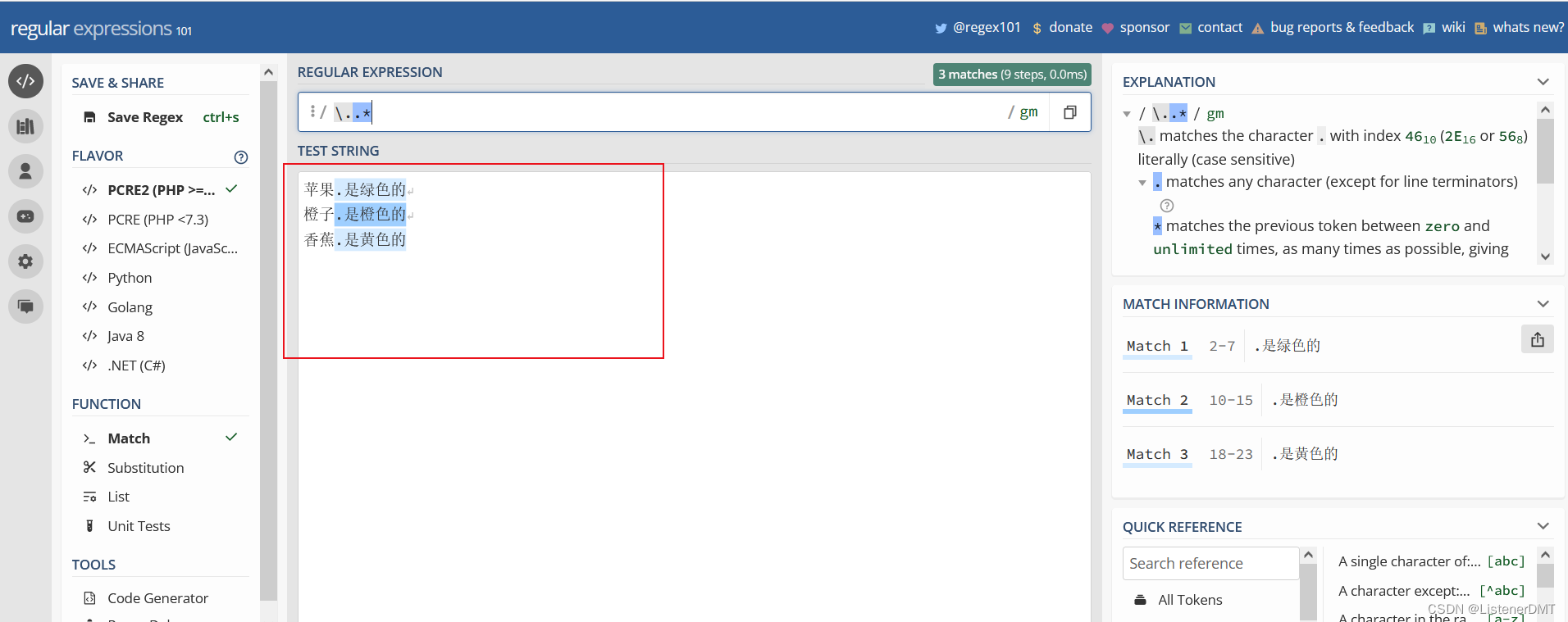
���������ʽ��, ��*��, ��+��, ��?�� ����̰����,ʹ������ʱ,�ᾡ���ܶ��ƥ������,
����, <.*> �е� �Ǻ�(��ʾ����������ظ�),һֱƥ�䵽�� �ַ������� </title> �����e��
����������,����Ҫʹ�÷�̰��ģʽ,Ҳ�������Ǻź������ ? ,������� <.*?>
?
7��ת���ַ�? ?\
8��ƥ��ij���ַ�����
��б�ܺ����һЩ�ַ�,��ʾƥ��
ij��������һ���ַ�������
\d ƥ��0-9֮������һ�������ַ�,�ȼ��ڱ���ʽ [0-9]
\D ƥ������һ������0-9֮��������ַ�,�ȼ��ڱ���ʽ [^0-9]
\s ƥ������һ���հ��ַ�,���� �ո�tab�����з���,�ȼ��ڱ���ʽ [\t\n\r\f\v]
\S ƥ������һ���ǿհ��ַ�,�ȼ��ڱ���ʽ [^ \t\n\r\f\v]
\w ƥ������һ�������ַ�,������Сд��ĸ�����֡��»���,�ȼ��ڱ���ʽ [a-zA-Z0-9_]
ȱʡ���Ҳ���� Unicode�����ַ�,���ָ�� ASCII ����,��ֻ����ASCII��ĸ
\W ƥ������һ���������ַ�,�ȼ��ڱ���ʽ [^a-zA-Z0-9_]
9��������? ?��ʾҪƥ�� ָ���ļ����ַ�֮һ
����
[abc]����ƥ�� a, b, ���� c ���������һ���ַ����ȼ���[a-c]��
[a-c]�м�� - ��ʾһ����Χ��a �� c���������ƥ�����е�Сд��ĸ,����ʹ��
[a-z]
һЩ Ԫ�ַ� �� �������� ʧȥ��ħ��, ��ú���ͨ�ַ�һ���ˡ�
����
[akm.]ƥ��a k m .��������һ���ַ�����
.���������治�ڱ�ʾ ƥ�������ַ���,�����DZ�ʾƥ��.��� �ַ�
����ڷ�������ʹ��
^, ��ʾ��������������ַ����ϡ�?
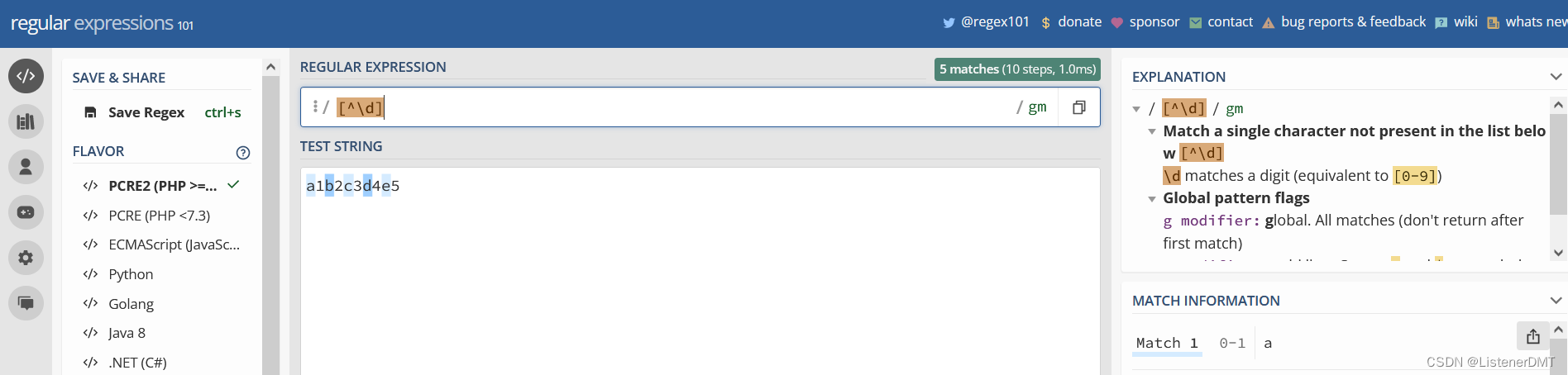
?10����ʼ����βλ�� �� ���С�����ģʽ
(1)��ʼλ�� ^
^��ʾƥ���ı�����ͷλ�á��������ʽ�����趨
����ģʽ������ģʽ�����
����ģʽ,��ʾƥ�������ı��Ŀ�ͷλ�á������
����ģʽ,��ʾƥ���ı�ÿ���Ŀ�ͷλ�á�����,������ı���,ÿ����ǰ������ֱ�ʾˮ���ı��,�������ֱ�ʾ�۸�
001-ƻ���۸�-60,
002-���Ӽ۸�-70,
003-�㽶�۸�-80,
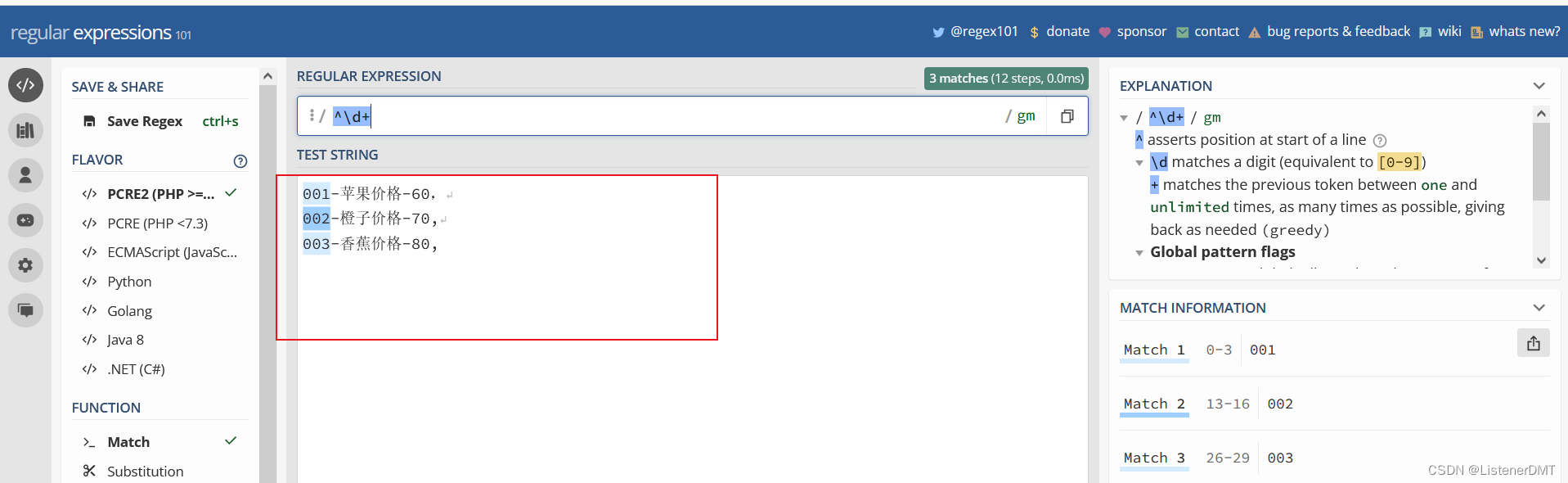
(2)�����? $
$��ʾƥ���ı�����βλ�á������
����ģʽ,��ʾƥ�������ı��Ľ�βλ�á������
����ģʽ,��ʾƥ���ı�ÿ���Ľ�βλ�á�����,������ı���,ÿ����ǰ������ֱ�ʾˮ���ı��,�������ֱ�ʾ�۸�
001-ƻ���۸�-60,
002-���Ӽ۸�-70,
003-�㽶�۸�-80,
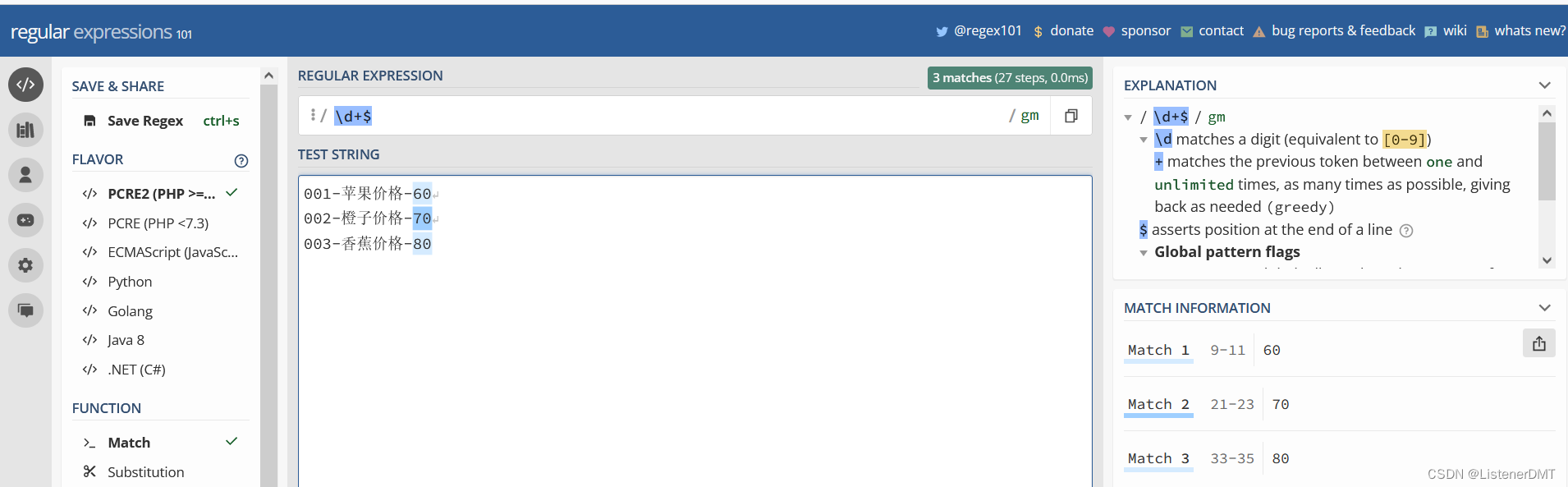
11�� ����?��ʾƥ������֮һ

12��()? ?���ŷ���
ΪʲôҪ����ĸ�����?��Ϊ����������Ҫ��ȡ�Ѿ�ƥ��� ��������� ijЩ���ֵ���Ϣ��
ǰ��,�����и�����,��������ı���,ѡ��ÿ�ж���ǰ�����ַ���,Ҳ
�������ű�����
ƻ��,ƻ������ɫ��
����,�����dz�ɫ��
�㽶,�㽶�ǻ�ɫ���Ϳ�������д�������ʽ
^.*,
����,�������Ҫ�� ��Ҫ�������� ��?
��Ȼ����ֱ�� ����д
^.*��Ϊ���Ķ��� �� ���� ����, ���ȥ����,��û���� ����ǰ����ˡ�
���ǰѶ��ŷ����������ʽ��,�ֻ�������š�
�������ķ�������ʹ�� ��ѡ��� : ���š�
��������д
^(.*),,�������
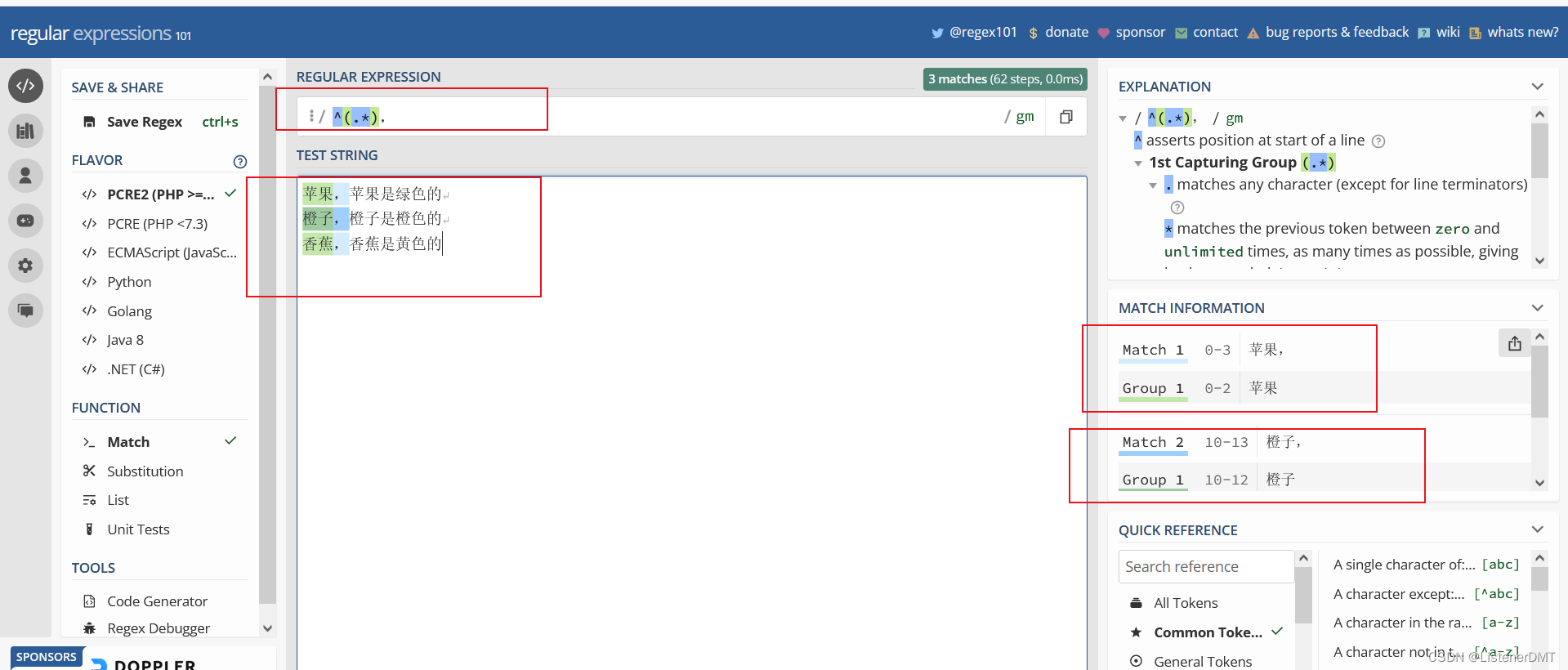
?�ڸ���һ���������:
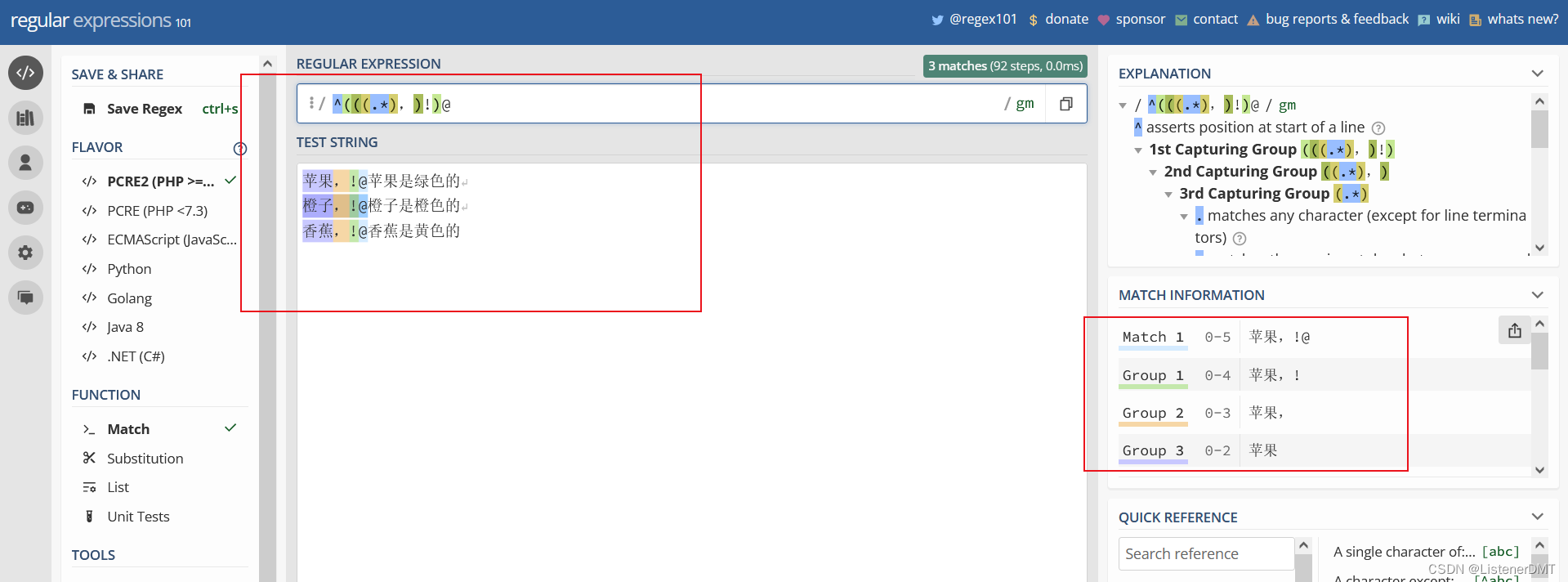
?ʹ�� ?P<������>? ?���Ը����������,���������ȡ

��������:
import re
content = """ƻ��,!@ƻ������ɫ��"""
# r �Ƿ�ֹת��
p = re.compile(r'^(?P<a>(?P<b>(?P<c>.*),)!)@')
for match in p.finditer(content):
print(match.group('a'))
print(match.group('b'))
print(match.group('c'))
����������:
D:\pythontest\plane\venv\Scripts\python.exe D:/pythontest/plane/�������ʽ/test1.py
ƻ��,!
ƻ��,
ƻ��13��һ����С����
���ı��¹���ȡ����
Python3 ����������ʦ �Ϻ����̽����Ƽ�����˾�Ϻ�-�ֶ�����2��/��02-18��Ա
���Կ�������ʦ(C++/python) �Ϻ�ī�d����Ƽ�����˾�Ϻ�-�ֶ�����2.5��/ÿ��02-18δ��Ա
Python3 ��������ʦ �Ϻ�������Ϣ�����ɷ�����˾�Ϻ�-�����1.3��/ÿ��02-18ʣ��11��
���Կ�������ʦ(Python) ������(�Ϻ�)��Ϣ�Ƽ�����˾�Ϻ�-�ֶ�����1.1��/ÿ��02-18ʣ��5��
����:
[\d.]+��\/ÿ?��
����:
[\d.]+��ʾ ƥ�� ���ֻ��ߵ�Ķ�γ��� ��Ϳ���ƥ����: 3 33 33.33 ������ ����
��/ÿ{0,1}���Ǻ�������ŵ�,���û�����,�ͻ�ƥ�䵽�������, ���� Python3 �����3������
ÿ{0,1}���ⲿ�ֱ�ʾƥ��ÿ��ÿ ����ֿ��Գ��� 0�λ���1�Ρ���������
ÿ?����Ϊ�ʺű�ʾ ǰ����ַ�ƥ��0�λ���1��

�����������ʽ��python��Ӧ��
1��findall? ���ص���һ��list
ƥ���ַ�����,���з������������
import re
lis = re.findall(r'\d+','�ҵĵ绰��:10086,�����ĵ绰��10010')
print(lis)���

?2��?finditer? ���ص���һ��������
ƥ���ַ��������е�����,���ص���һ��������,�ӵ��������õ�������Ҫ, .group()
import re
lis = re.finditer(r'\d+', '�ҵĵ绰��:10086,�����ĵ绰��10010')
for i in lis:
print(i.group())���:
D:\pythontest\plane\venv\Scripts\python.exe D:/pythontest/plane/�������ʽ/test2.py
10086
100103��search? ����match����
search? �ҵ�һ������ͷ���,���ص���match����,��������Ҫ.group()
import re
lis = re.search(r'\d+', '�ҵĵ绰��:10086,�����ĵ绰��10010')
print(lis.group())���
D:\pythontest\plane\venv\Scripts\python.exe D:/pythontest/plane/�������ʽ/test2.py
100864��match? Ĭ�ϴ�ͷƥ��
����
import re
lis = re.match(r'\d+', '�ҵĵ绰��:10086,�����ĵ绰��10010')
print(lis.group())���
D:\pythontest\plane\venv\Scripts\python.exe D:/pythontest/plane/�������ʽ/test2.py
Traceback (most recent call last):
File "D:\pythontest\plane\�������ʽ\test2.py", line 4, in <module>
print(lis.group())
AttributeError: 'NoneType' object has no attribute 'group'����
import re
lis = re.match(r'\d+', '10086,�����ĵ绰��10010')
print(lis.group())���
D:\pythontest\plane\venv\Scripts\python.exe D:/pythontest/plane/�������ʽ/test2.py
100865��Ԥ�����������ʽ
�Ѳ����ó�����ǰ��ֵ,����:
obi? =? re.compile(r'\d+')
ʹ��ʱֻ��? obj.find(���ݼ���)? ? ����ͬ��
?6��()����ȡhtml��ǩ�������
��������:
import re
content = '''<div class='jar'><span id='1'>����</span></div>
<div class='jarr'><span id='2'>����</span></div>
<div class='jarrr'><span id='3'>����</span></div>
<div class='jarrrr'><span id='4'>����</span></div>'''
# re.S ��.��ƥ�任�з�
obj = re.compile(r"<div class='(?P<a>.*?)'><span id='(?P<b>\d+)'>(?P<c>.*?)</span></div>", re.S)
result = obj.finditer(content)
for it in result:
print(it.group('c'))
�������:
D:\pythontest\plane\venv\Scripts\python.exe D:/pythontest/plane/�������ʽ/test2.py
����
����
����
����
