目录
- 非多线程爬取
- 源码
- 遇到的问题及解决方案
- 一个段子在HTML源码中被标签br分割,导致xpath解析时,一个段子变成多个列表元素
- 遇到一个Python与C/C++的地方:
- 爬取👍数,👎数,及收藏数时,另辟蹊径
- 写入csv文件时,在pycharm中打开中文可见,外部打开中文变为乱码
- pycharm调试不熟练,导致每次调试,都是不同的数据
- 在使用上一个问题第一个解决方法时遇到报错问题:lxml.etree.XMLSyntaxError: Opening and ending tag mismatch.....
- 要把多个数据列表放到一个元组中
- 以元组的第三个元素为key对元组进行排序,并且需要转`int`
- 写入csv文件后,发现每个记录中间都以一个空行为间隔
- 多线程爬取
非多线程爬取
源码
目标网站:www.xiaohua.com
import requests
from lxml import etree
import csv
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/101.0.4951.64 Safari/537.36 '
}
collection = []
hds = ("support", "nosupport", "collect", "joke")
def parse_page(link):
resp = requests.get(link, headers=headers)
text = resp.text
html = etree.HTML(text)
jokes = html.xpath("//div[@class='one-cont']/p//text()")
supportNums = html.xpath("//div[@class='one-cont']/ul/li/i[@class='support']/following-sibling::span[1]/text()")
nosupportNums = html.xpath("//div[@class='one-cont']/ul/li/i[@class='nosupport']/following-sibling::span[1]/text()")
collectNums = html.xpath("//div[@class='one-cont']/ul/li/i[@class='collect']/following-sibling::span[1]/text()")
realJokes = []
reStr = ''
idx = 0
while idx < len(jokes):
while not jokes[idx].startswith("\r\n"):
reStr += jokes[idx]
idx += 1
if jokes[idx].startswith("\r\n") and reStr != '':
realJokes.append(reStr)
reStr = ''
idx += 1
for i in range(len(realJokes)):
collection.append((supportNums[i], nosupportNums[i], collectNums[i], realJokes[i]))
def inCSV():
collection.sort(key=lambda x: int(x[2]), reverse=True)
with open("jokes.csv", 'w', encoding='utf-8-sig', newline='') as fp:
writer = csv.writer(fp)
writer.writerow(hds)
writer.writerows(collection)
def main():
for i in range(1, 10):
url = f"https://www.xiaohua.com/duanzi?page={i}"
parse_page(url)
inCSV()
if __name__ == '__main__':
main()
遇到的问题及解决方案
一个段子在HTML源码中被标签br分割,导致xpath解析时,一个段子变成多个列表元素
解决方法:
-
将
//div[@class='one-cont']/p/a/text()改成//div[@class='one-cont']/p//text()这样会使一个段子被“\r\n ”分割。
然后将将分开的段子合成一个。 -
进入每一个段子的链接,再合并,效率低于第一种方法
遇到一个Python与C/C++的地方:
在for循环中,idx += 1,影响不了for语句上的idx,与C/C++不同。
for idx in range(10):
print(idx, end=' ') # 0 1 2 3 4 5 6 7 8 9
idx += 1
于是我改用成while循环了。
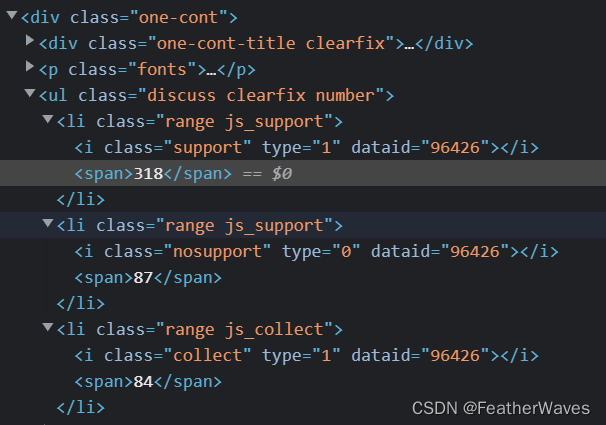
爬取👍数,👎数,及收藏数时,另辟蹊径
本来可以从div -> ul -> 不同的li -> span -> 数据。
但是我使用了一个函数following-sibling::span[1], div -> ul -> i -> 函数 -> 数据。
写入csv文件时,在pycharm中打开中文可见,外部打开中文变为乱码
把encoding=utf-8改成utf-8-sig就可以了
原因:
-
utf-8是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序问题,因此它不需要BOM,所以当用"utf-8"编码方式读取带有BOM的文件时,它会把BOM当做是文件内容来处理, 也就会发生类似上边的错误。 -
uft-8-sig中sig全拼为 signature也就是"带有签名的utf-8”, 因此"utf-8-sig"读取带有BOM的"utf-8文件时"会把BOM单独处理,与文本内容隔离开,也是我们期望的结果。
pycharm调试不熟练,导致每次调试,都是不同的数据
在调试解决第一个问题的代码时,遇到了第二个问题,导致需要调试解决。调试时,才看到爬取到的数据,这时需要打个条件断点,跳至特定的地方,因为不熟悉pycharm的调试,不会从一个断点跳至另一个断点。
解决方法:
- 将源码copy下来,进行固定数据的调试。(
html = etree.parse("文件")) - 按F9,从一个断点跳至另一个断点。
在使用上一个问题第一个解决方法时遇到报错问题:lxml.etree.XMLSyntaxError: Opening and ending tag mismatch…
使用lxml.etree.parse()解析html文件,该方法默认使用的是XML解析器,所以如果碰到不规范的html文件时就会解析错误。
解决方法:自己写一个解析器:parser = etree.parser(encoding='utf-8')
加入到解析函数中html = etree.parse("文件", parser=parser)
要把多个数据列表放到一个元组中
talk is cheap, show you the code
for i in range(len(realJokes)):
collection.append((supportNums[i], nosupportNums[i], collectNums[i], realJokes[i]))
以元组的第三个元素为key对元组进行排序,并且需要转int
因为之前需要以其中一个元素中的元素进行sort的时候,只碰到过字典的情况,这次是对元组有要求。
并且,由于原来的数据元素类型是:<class 'lxml.etree._ElementUnicodeResult'> ,而非int。所以需要注意转int。
解决方法:
- 转成字典进行排序,然后写入到csv中
collection.sort(key=lambda x: int(x[2]), reverse=True)
写入csv文件后,发现每个记录中间都以一个空行为间隔
解决方法: 加上newline=''即可
多线程爬取
源码
from lxml import etree
import threading
import requests
from queue import Queue
import csv
class Producer(threading.Thread):
headers = {
'User_Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/101.0.4951.64 Safari/537.36 '
}
def __init__(self, page_queue, joke_queue, *args, **kwargs):
super(Producer, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.joke_queue = joke_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, link):
resp = requests.get(link, headers=self.headers)
text = resp.text
html = etree.HTML(text)
jokes = html.xpath("//div[@class='one-cont']/p//text()")
supportNums = html.xpath(
"//div[@class='one-cont']/ul/li/i[@class='support']/following-sibling::span[1]/text()")
nosupportNums = html.xpath(
"//div[@class='one-cont']/ul/li/i[@class='nosupport']/following-sibling::span[1]/text()")
collectNums = html.xpath(
"//div[@class='one-cont']/ul/li/i[@class='collect']/following-sibling::span[1]/text()")
realJokes = []
reStr = ''
idx = 0
while idx < len(jokes):
while not jokes[idx].startswith("\r\n"):
reStr += jokes[idx]
idx += 1
if jokes[idx].startswith("\r\n") and reStr != '':
realJokes.append(reStr)
reStr = ''
idx += 1
for i in range(len(realJokes)):
self.joke_queue.put((supportNums[i], nosupportNums[i], collectNums[i], realJokes[i]))
class Consumer(threading.Thread):
def __init__(self, joke_queue, writer, lock, *args, **kwargs):
super(Consumer, self).__init__(*args, **kwargs)
self.joke_queue = joke_queue
self.writer = writer
self.lock = lock
def run(self):
while True:
try:
joke_info = self.joke_queue.get(timeout=40)
self.lock.acquire()
self.writer.writerow(joke_info)
self.lock.release()
except:
break
def main():
page_queue = Queue(10)
joke_queue = Queue(500)
gLock = threading.Lock()
fp = open("jokes.csv", "a", encoding='utf-8-sig', newline='')
writer = csv.writer(fp)
writer.writerow(("support", "nosupport", "collect", "joke"))
for i in range(1, 11):
url = f"https://www.xiaohua.com/duanzi?page={i}"
page_queue.put(url)
for i in range(3):
t = Producer(page_queue, joke_queue)
t.start()
for i in range(5):
t = Consumer(joke_queue, writer, gLock)
t.start()
if __name__ == '__main__':
main()
排序的取舍
在非多线程爬取过程中,我采用了按照收藏量进行从大到小(逆序)排序。再写入csv文件,但是在多线程爬取中,由于多线程不能保证上述的有序性,所以我选择摒弃排序的操作。
爬取结果


