文章目录
django_实现朴素/基本模糊拼写候选/纠错
这只是一个粗糙的
玩具,不具备智能性
使用到的拼写数据库支持(一角)
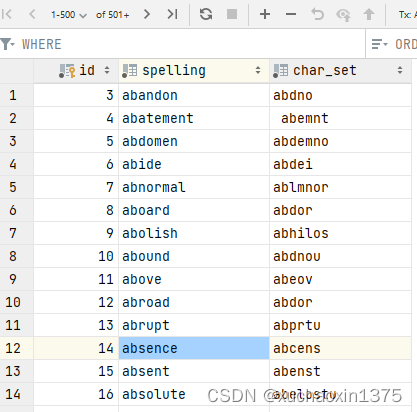
数据库模型
from django.db.models.functions import Length
CharField.register_lookup(Length)
class WordMatcher(models.Model):
"""词典升级的时候,模糊匹配的词典也需要一并升级!!!!"""
spelling = models.CharField(max_length=255)
char_set = models.CharField(max_length=26)
# word_length = models.IntegerField(default=0)
# django提供了类似的Length的数据库函数,长度子字段可以不需要存储(本身也不是一个好主意)
def __str__(self):
return str([self.spelling,self.char_set])
Words词典
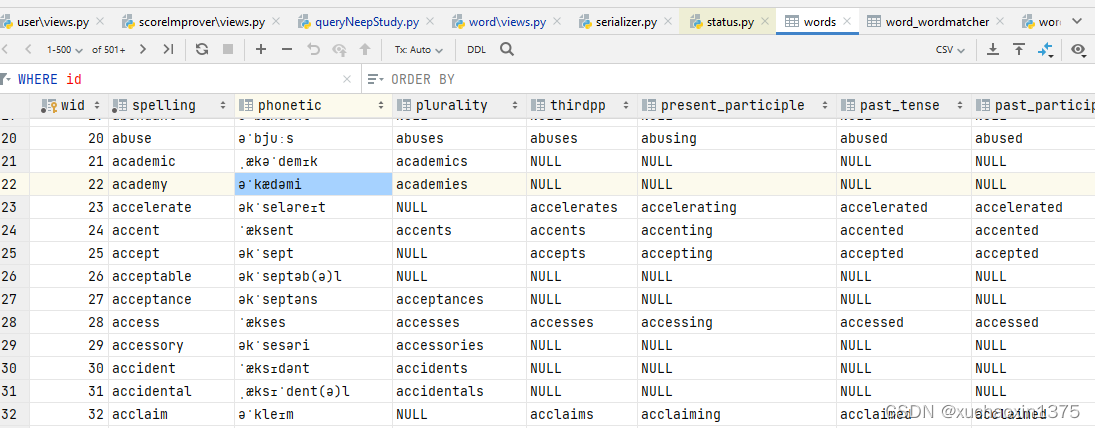
char_set字段的计算(数据库的产生)
wob = Word.objects
class UpdateWordMatcher:
# 填充单词模糊匹配数据库支持(模糊推荐算法)
# 测试两个例子
def update(self):
# sub_dict_set = wob.all()
sub_dict_set = wob.all()[:2]
for item in sub_dict_set:
# print(item)
char_set = set(item.spelling)
chars = list(char_set)
chars.sort()
chars_str = "".join(chars)
# return chars_str
print(chars_str)
d = {"spelling": item.spelling, "char_set": chars_str}
wmob.create(**d)
# chars=list(char_set).sort()
# print(chars)
序列化器
class WordMatcherModelSerializer(ModelSerializer):
class Meta:
model=WordMatcher
fields = "__all__"
参考代码
Serialzier部分是使用了Django_DRF框架的序列化器
class WordMatcherViewSet(ModelViewSet):
""" 模糊匹配数据库"""
wmob = WordMatcher.objects
queryset = wmob.all()
serializer_class = WordMatcherModelSerializer
#filter_fields = ['spelling', 'char_set']
def fuzzy_match(self, req, spelling, start_with=0):
"""
:param req:
:type req:
:param spelling:
:type spelling:
:param start_with:匹配开头的字符串长度 (default: {0},表示没有被强制规定)
:type start_with:
:return:
:rtype: Response
"""
spelling_len = len(spelling)
# 根据模糊拼写的长度,选择一个较为合适的start_with
if(start_with==0):
#没有被强制设值
# 启用内部判断取值
if(spelling_len>4):
start_with=2
else:
start_with=1
# 获得模糊拼写的字母集合
spelling_char_set = set(spelling)
# 获取模糊拼写的字母集列表(字母集合去重后转换为列表)
spelling_char_list = list(spelling_char_set)
# 对字母集合转成的列表进行排序
spelling_char_list.sort()
spelling_char_set_str = "".join(spelling_char_set)
spelling_char_set_len = len(spelling_char_set)
# print("@spelling_chars:", spelling_char_set_str)
# 定义匹配的单词的长度范围
left_len = spelling_len * 0.70
# right_len = spelling_len * 1.25
right_len = spelling_len * 1.4
if spelling_len >= 4:
right_len = spelling_len * 2
# 模糊匹配
# queryset = self.get_queryset().filter(spelling__length__gte=left_len) & self.get_queryset().filter(
# spelling__length__lte=right_len) & self.queryset.filter(char_set__contains=spelling_chars)
"""限制单词长度"""
queryset = self.queryset.filter(spelling__length__gte=left_len) & self.queryset.filter(
spelling__length__lte=right_len)
# 匹配开头(严格模式)(可以额外设置变量,追加if)
# print(queryset)
# 匹配发音:mysql中有一个soundx函数,
queryset = queryset.filter(spelling__startswith=spelling[:start_with])
"""限制单词字符集规模的差异"""
# 10:14(5:7);
# 10:16(5:8);
queryset = queryset.filter(char_set__length__lte=1.25 * spelling_char_set_len)
# 3:5;
# 4:5
queryset = queryset.filter(char_set__length__gte=0.6 * spelling_char_set_len)
"""匹配字符组成(最后一步)"""
# 方案0:使用icontains函数来匹配(无法匹配到替换了个别字母的形近词!
## 可以引入随机剔除字符操作
# 方案1:双向包含(或运算)(比上衣种情况稍好,但还是无法满足需求)
# 方案2:差集(限制差集中的元素个数)(容错个别字母(种类)的不同)
# queryin = queryset.filter(char_set__in=spelling_chars)
# print("@queryin:", queryin)
# queryset = queryset.filter(Q(char_set__contains=spelling_chars) | Q(char_set__in=spelling_chars))
items = []
for item in queryset:
item_char_set_len = len(item.char_set)
item_spelling_len = len(item.spelling)
intersection = set(item.char_set) & set(spelling_char_set)
intersection_len = len(intersection)
# if (item.spelling == "dad"):
# print("dad", diff, len(diff), item, spelling_chars_len * 0.5)
# # print()
if (spelling_len >= 5):
if (intersection_len >= spelling_char_set_len * 0.8 and intersection_len >= item_char_set_len * 0.8):
# if (item.spelling == "dad"):
# print(item, diff)
items.append(item)
elif (intersection == spelling_char_set):
# 长度小于5的输入,我们只需要检查是否包含全部字符即可
# else:
print("@intersection", intersection)
print("@spelling_char_set", spelling_char_set)
print(item, intersection, spelling_char_set_len)
if (item_spelling_len == spelling_len):
items.append(item)
# print(queryset)
items.sort(key=lambda x:x.spelling)
print(len(items))
return Res(self.serializer_class(instance=items, many=True).data)
# return Res(self.serializer_class(instance=queryset, many=True).data)
def fuzzy_match_simple(self, req, spelling):
return self.fuzzy_match(req, spelling)
路由
path('fuzzy/<str:spelling>/', views.WordMatcherViewSet.as_view({
"get": "fuzzy_match_simple"
})),
path('fuzzy/<str:spelling>/<int:start_with>/', views.WordMatcherViewSet.as_view({
"get": "fuzzy_match"
})),
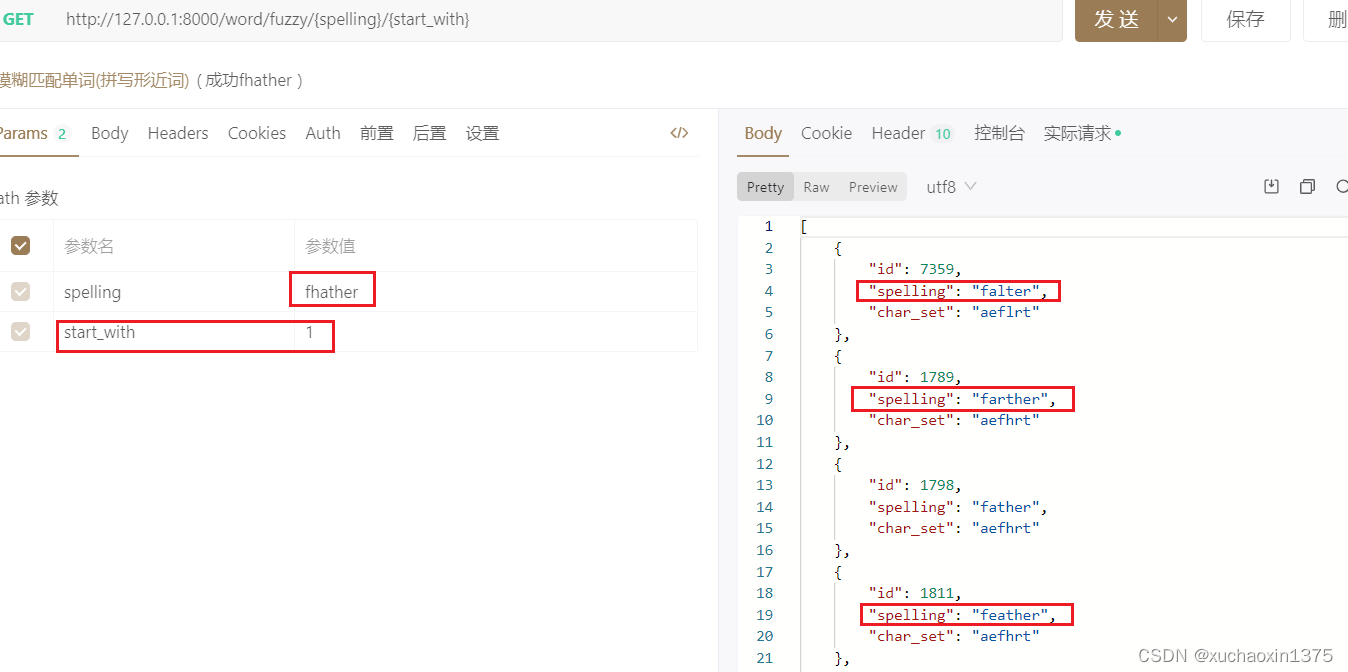
api基本效果
eg0:
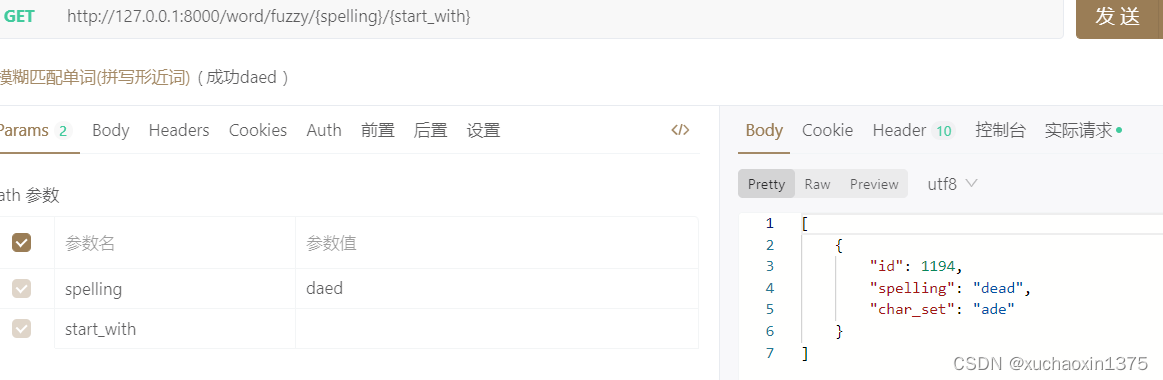
eg1:
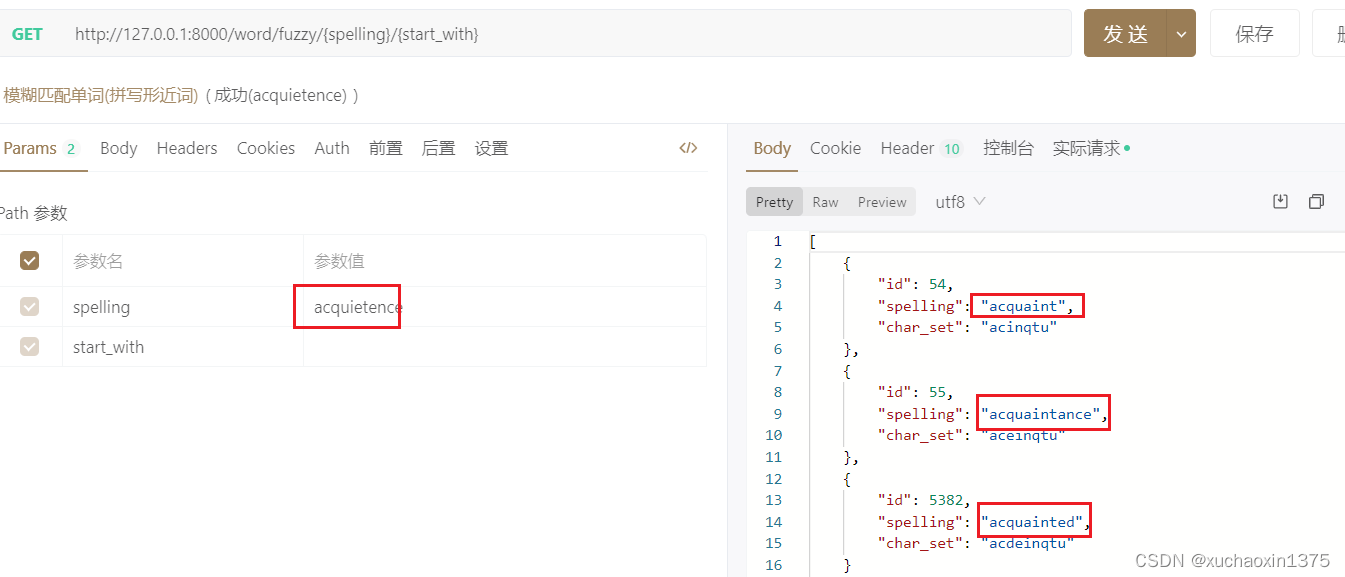
eg2
GEThttp://127.0.0.1:8000/word/fuzzy/fhather/1