Ŀ¼
����
��������֪��������������,ѡ��ֽ�C>���������ѧ�����רC>�ij�ȫ��ģʽ�C>�������ҳ������ȨC>��ȡ�����ڵ����ֺͶ�Ӧ�����
��Ҫ������,��������pip install��������,���鷳���������Ҫȥ���ظ���Ӧ�汾��chromedriver.exe����,�ŵ�python����Anaconda���ļ���Ŀ¼��,Ȼ�����ӻ�������(�ⲿ�ֱ��������аٶȼ���,�����������鷳��)
ע��time.sleep()�DZ�Ҫ��,һ��Ϊ�˱���Ƶ�����������������,���������粻�õ����������ҳ������ȫ,���ᵼ�±���
һ����Ҫͼ��,Ŀǰ����8s�������һ�μ���������¼��,��ʦ���ҵ�Ҫ����700������,Ҳ�����и�һ�����Сʱ
��֮�л��������������,�ڴ����ע����Ҳ��д����
����ģ�����
����ģ�����������
# �����������������
def openUrl(url):
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
return driver
ֻ��Ҫִ��һ�εIJ���
xpath��λ�ȡ�ٶ�һ�¼���
# ֻ����һ��,�����ظ�����Ӱ��Ч��
def onceClick(driver):
#ѡ��ֽ��
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div/ul[1]/li[4]/a').click()
time.sleep(2)
#���������ѧ������
driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/label/input').click()
time.sleep(1)
#����Ϊȫ��ģʽ
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/div[1]').click()
time.sleep(2)
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/div[1]/div[2]/ul/li[5]').click()
time.sleep(2)
��Ҫ����ִ�е��ظ���������
�ⲿ����Ҫ��֪��ҳ��Ľ�������������,�������˺ü������ڽ����
��һ�μ�����ʱ�����ҳ���ǹ��ŵ�
�ڶ����ֱ���˲���,�������Ҫ��ȡ������Ҫ���������ļ�,���������flag(�����������)
try-except��Ϊ�˷�ֹ����������������,��Ϊ��Щ�ؼ��ʳ��ֵú���,�Ͳ���Ҫ�����ͼ�����,�����try���ͻᱨ����ֹ����
# ����ؼ��ʲ����,ѭ������
def send_and_click(driver,kw,np,flag):
#���������
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/input').send_keys(kw)
time.sleep(0.5)
#���뱨ֽ����
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[3]/div[2]/input').send_keys(np)
time.sleep(0.5)
#�������
driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/input').click()
time.sleep(1.5)
if flag==True:
#��һ�μ���ʱ��Ҫչ��������ȴ����
driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dt').click()
time.sleep(2)
if flag==False:
#�ڶ��ο�ʼ,������Ƚ���С,û���ջص������,����չ�����������С��ҳ��,
#ʹ��try-except��Ϊ�˷�ֹ����������������,Ӱ��������
try:
driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dd/div/a').click()
time.sleep(1)
except:
pass
#����С�ļ���ҳ
driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[2]/a[2]').click()
time.sleep(0.5)
#���ԭ������
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/input').clear()
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[3]/div[2]/input').clear()
time.sleep(1)
��ȡ��ҳ����
���������Ҫ���Ǹ����Լ���������,������Ƿ����б�
# ��ȡ���ݲ����������б�
def getData_and_print(driver,tw,dp):
cntDict={}
for index in range(1,13):
try:
text1=driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dd/div/ul/li['+str(index)+']').text
cntDict[text1[:4]]=text1[5:-1]
except:
continue
for i in years:
if i not in cntDict.keys():
cntDict[i]='0'
cnttuplelist=[]
cntlist=[]
for i in sorted (cntDict,reverse=False):
if int(i)>=2011 and int(i)<=2018:
cnttuplelist.append((i, cntDict[i]))
cntlist.append(cntDict[i])
else:
continue
for ct1,ct2 in cnttuplelist:
print(dp+'\t\t\t'+ct1+'\t'+tw+'\t\t'+ct2)
return cntlist
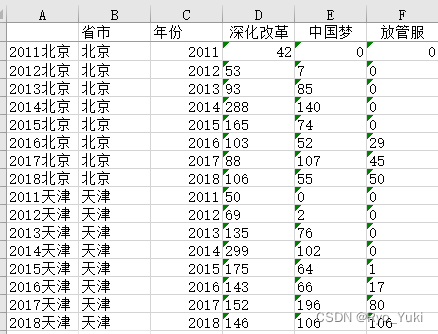
¼��excel
�������Ҳ�Ǹ����Լ���������,��Ҫ�������ݵ�¼�����
#���ز�������д��excelָ��λ��
def load_into_excel(datalist,indexi,indexj):
wb=openpyxl.load_workbook('data.xlsx')
ws=wb['Sheet1']
for i in range(len(datalist)):
ws.cell(row=i+8*indexi+2,column=4+indexj).value=datalist[i]
wb.save("data.xlsx")
������
#������
if __name__ =='__main__':
driver=openUrl('https://kns.cnki.net/kns8/AdvSearch?dbprefix=CFLS&&crossDbcodes=CJFQ%2CCDMD%2CCIPD%2CCCND%2CCISD%2CSNAD%2CBDZK%2CCCJD%2CCCVD%2CCJFN')
onceClick(driver)
flag=True
for indexi,dp in enumerate(dailyPapers):#��ֽΪ��
for indexj,tw in enumerate(topicWords):#�ؼ���Ϊ��
send_and_click(driver,tw,dp,flag)
flag=False #���е�һ�κ�,���flagΪFalse
cntlist=getData_and_print(driver,tw,dp)
load_into_excel(cntlist,indexi,indexj)
driver.close()
�����ļ��ṹ
ֻ��Ҫ��data.xlsx�ʹ����ļ���һ��,�����þ���·��Ҳ��

data.xlsxҪ���������Ȱ��Լ���Ҫ������,����ֻ��������
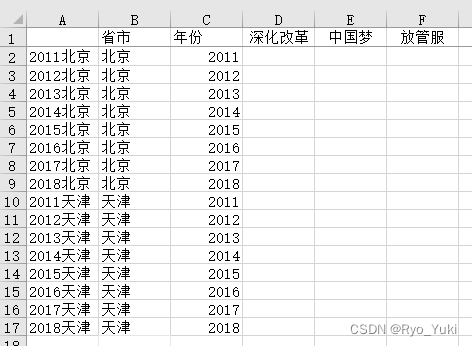
ȫ������
from selenium import webdriver
import time
import openpyxl
#�Զ�������
topicWords=['��ĸ�','�й���','�Źܷ�']
dailyPapers=['�����ձ�','����ձ�']
years='2022','2021','2020','2019','2018','2017','2016','2015','2014','2013','2012','2011']
# �����������������
def openUrl(url):
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
return driver
# ֻ����һ��,�����ظ�����Ӱ��Ч��
def onceClick(driver):
#ѡ��ֽ��
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div/ul[1]/li[4]/a').click()
time.sleep(2)
#���������ѧ������
driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/label/input').click()
time.sleep(1)
#����Ϊȫ��ģʽ
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/div[1]').click()
time.sleep(2)
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/div[1]/div[2]/ul/li[5]').click()
time.sleep(2)
# ����ؼ��ʲ����,ѭ������
def send_and_click(driver,kw,np,flag):
#���������
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/input').send_keys(kw)
time.sleep(0.5)
#���뱨ֽ����
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[3]/div[2]/input').send_keys(np)
time.sleep(0.5)
#�������
driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/input').click()
time.sleep(1.5)
if flag==True:
#��һ�μ���ʱ��Ҫչ��������ȴ����
driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dt').click()
time.sleep(2)
if flag==False:
#�ڶ��ο�ʼ,������Ƚ���С,û���ջص������,����չ�����������С��ҳ��,
#ʹ��try-except��Ϊ�˷�ֹ����������������,Ӱ��������
try:
driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dd/div/a').click()
time.sleep(1)
except:
pass
#����С�ļ���ҳ
driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[2]/a[2]').click()
time.sleep(0.5)
#���ԭ������
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/input').clear()
driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[3]/div[2]/input').clear()
time.sleep(1)
# ��ȡ���ݲ����������б�
def getData_and_print(driver,tw,dp):
cntDict={}
for index in range(1,13):
try:
text1=driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dd/div/ul/li['+str(index)+']').text
cntDict[text1[:4]]=text1[5:-1]
except:
continue
for i in years:
if i not in cntDict.keys():
cntDict[i]='0'
cnttuplelist=[]
cntlist=[]
for i in sorted (cntDict,reverse=False):
if int(i)>=2011 and int(i)<=2018:
cnttuplelist.append((i, cntDict[i]))
cntlist.append(cntDict[i])
else:
continue
for ct1,ct2 in cnttuplelist:
print(dp+'\t\t\t'+ct1+'\t'+tw+'\t\t'+ct2)
return cntlist
#���ز�������д��excelָ��λ��
def load_into_excel(datalist,indexi,indexj):
wb=openpyxl.load_workbook('data.xlsx')
ws=wb['Sheet1']
for i in range(len(datalist)):
ws.cell(row=i+8*indexi+2,column=4+indexj).value=datalist[i]
wb.save("data.xlsx")
#������
if __name__ =='__main__':
driver=openUrl('https://kns.cnki.net/kns8/AdvSearch?dbprefix=CFLS&&crossDbcodes=CJFQ%2CCDMD%2CCIPD%2CCCND%2CCISD%2CSNAD%2CBDZK%2CCCJD%2CCCVD%2CCJFN')
onceClick(driver)
flag=True
for indexi,dp in enumerate(dailyPapers):#��ֽΪ��
for indexj,tw in enumerate(topicWords):#�ؼ���Ϊ��
send_and_click(driver,tw,dp,flag)
flag=False #���е�һ�κ�,���flagΪFalse
cntlist=getData_and_print(driver,tw,dp)
load_into_excel(cntlist,indexi,indexj)
driver.close()
���Ԥ��
����̨
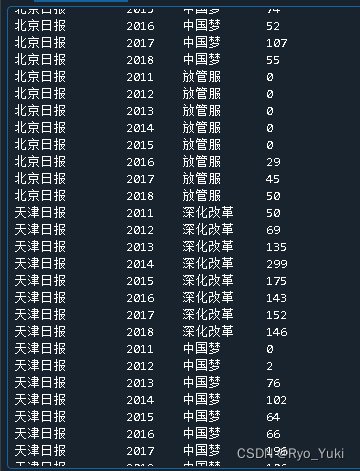
�ļ�