目录
前言????????
????????大家好,我是技术总监,最近项目很忙就很少分享自己的生活和每周收获,但作为csdn的忠实粉丝,每周都有去关注博主的优秀博客,最近看到龙叔一篇让我快速成为优秀博主的文章,让我受益匪浅。文章主要包括包装自己和包装文章结构。
????????哈哈哈,在这我就分享下我自己印象最深的吧。“图文并茂”、图文并茂”、图文并茂”。道理我都懂,那这么多合适的图哪里来啊。
????????可不我掏出了python把你们平时斗图写文章用到的表情包整理的好好的,分享给大家。(有兴趣的可以看下龙叔的这篇文章https://so.csdn.net/so/search?spm=1000.2115.3001.4498&q=%E9%80%80%E4%BC%91%E7%9A%84%E9%BE%99%E5%8F%94&t=&u=&urw=)

?一、整体构思
????????1、通过关键字来获取网上的表情包。
????????2、下载需要的表情包数量,并对表情包进行排序。
????????3、将表情包保存到本地,保存时可自己新建文件夹名称。
????????4、在下载时可查看下载进度。
????????5、将自己熟悉的热门编程表情包都分文件夹存放起来。
????????好啦,思路清晰,那我们就直接冲冲。工具只是实现你思想的傀儡,idea才是灵魂呀。

?
二、实现方法简介
????????我们还是用我们的三点定位法,效果图+源代码+总结。nice!
1、效果图:

热门语言表情包?

通用表情包(斗图)+文章结尾表情包(3连卑微表情包) +励志表情包(打鸡血)

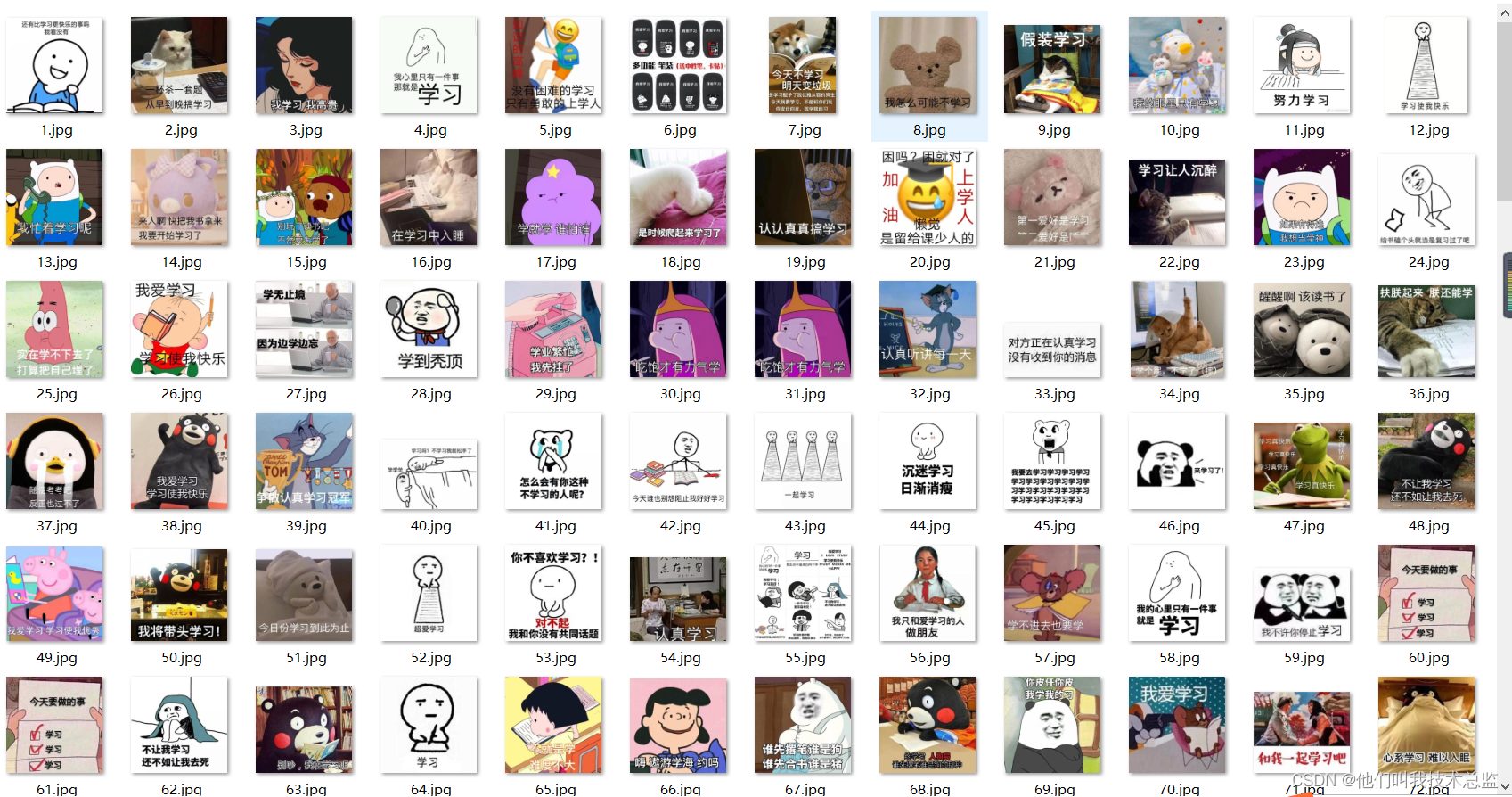 ?
?
 ?
?
点进去大概长这样?
2、python代码(推荐pycharm工具):
# -*- coding: UTF-8 -*-
import requests
import json
import os
import pprint
#存放表情包子文件夹名称
image_path_name=input("存放博客图片子文件夹名称:")
# 创建一个文件夹
path = 'D:/博客图片/'+image_path_name#列如输入python 就会生成D:/博客图片/python文件夹名称
if not os.path.exists(path):
os.mkdir(path)
# 导入一个请求头
header = {
# 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36'
}
# 用户(自己)输入信息指令
keyword = input('请输入你想下载的内容:')
page = input('请输入你想爬取的页数:')
page = int(page) + 1
n = 0
pn = 1
# pn代表从第几张图片开始获取,百度图片下滑时默认一次性显示30张
for m in range(1, page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': pn,
'rn': '30',
'gsm': '1e',
}
# 定义一个空列表,用于存放图片的URL
image_url = list()
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text
# 把字符串转换成json数据
data_s = json.loads(response)
a = data_s["data"] # 提取data里的数据
for i in range(len(a)-1): # 去掉最后一个空数据
data = a[i].get("thumbURL", "not exist") # 防止报错key error
image_url.append(data)
for image_src in image_url:
image_data = requests.get(url=image_src, headers=header).content # 提取图片内容数据
image_name = '{}'.format(n+1) + '.jpg' # 图片名
image_path = path + '/' + image_name # 图片保存路径
with open(image_path, 'wb') as f: # 保存数据
f.write(image_data)
print(image_name, '下载成功啦!!!')
f.close()
n += 1
pn += 29
3、总结?
????????整个代码大概80行左右,每个步骤都有详细注释。主要逻辑是通过百度图片加关键字来获取你需要的图片。如果出现被限制反爬虫,可以使用自己的user-agent信息就好。还有百度默认是一页加载是30个图片,根据自己的需要输入需要爬取的页数即可。默认会根据你获取的图片的顺序给图片从1到N重命名。

 ?
?
?三、写在最后
????????好的,下面直接上分享链接。如果上面的代码看不懂没关系。直接CV大法先试用,用了几次你也就会了。赶快拿去和你小伙伴斗图去吧,博主们也可以收藏用来写文章用,记得点赞、收藏、关注哦~。大家百度网盘链接自取哦~爱你?(^_-)。
链接:https://pan.baidu.com/s/1yJOOqEd7Cp7L1gQjnzg4KQ?
提取码:fb5x

?
?
?

