在keras中使用gpu加速训练模型,如何安装cuda,cudnn,解决cudnn_cnn_infer64_8.dll 不在path中,解决device_lib.list_local_devices()中无gpu,解决jupyter使用gpu训练总是挂掉的等问题
全网最全!!!亲自踩坑
首先打开任务管理器,查看自己电脑是否存在gpu
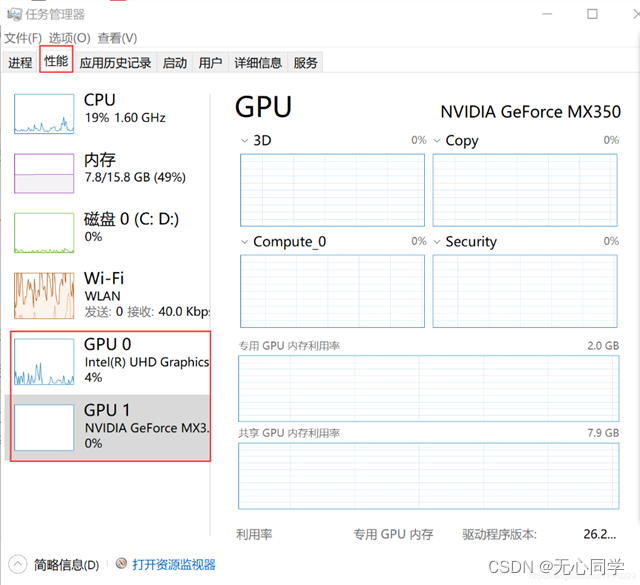
1、安装tensorflow-gpu
Pip install tensorflow-gpu==2.8.0 -i https://pypi.tuna.tsinghua.edu.cn/simple --user
注意,以前安装的tensorflow默认是cpu版的,所以我们下载这个是gpu版的,注意版本得和tensorflow一致(网上说要在tensorflow安装之后安装tensorflow-gpu)
2、安装keras (先安装keras的话,安装tensorflow会把karas安装到一致的版本)
3、安装CUDA
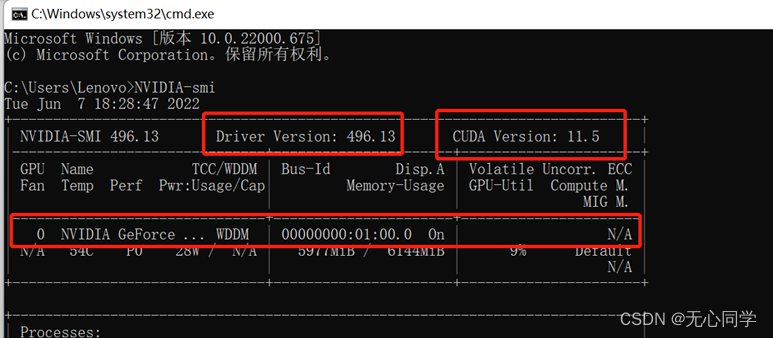
首先在命令行输入 NVIDIA-smi,查看自己的gpu,驱动版本,CUDA版本
打开网址 https://developer.nvidia.com/cuda-toolkit-archive
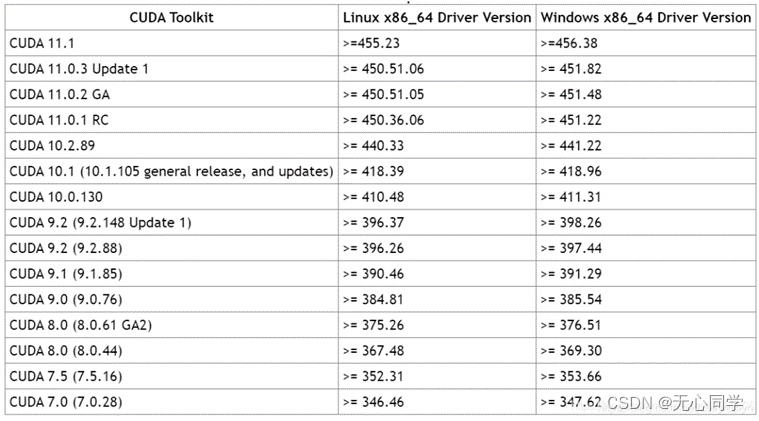
按照以下表格安装对应的CUDA版本(我的11.5是已经下载好的),下载exe
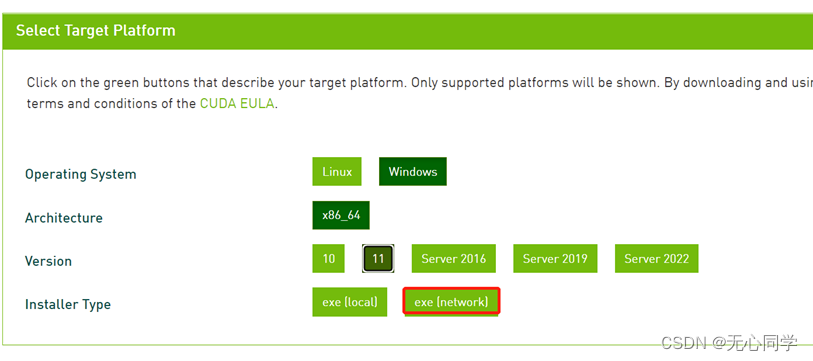
下载这个东西,然后双击下载好的东西
注意:在装CUDA时选择自定义安装,取消“Visual Studio”这一项就可以了(大概在第一个下面)
4、安装cudnn
在这个网址,下载对应的cudnn:[https://developer.nvidia.com/rdp/cudnn-archive](https://developer.nvidia.com/rdp/cudnn-archive)
比如我下载的就是这个
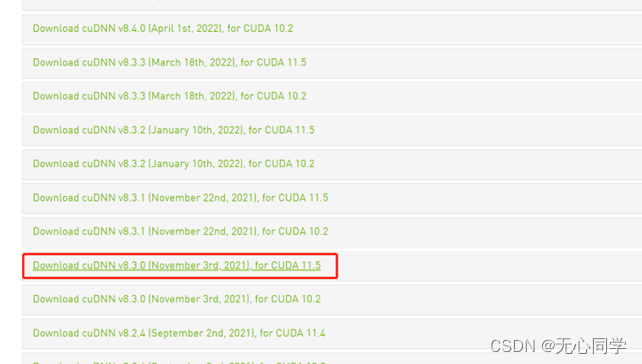
将下载好的压缩包解压,然后只需要把下载后的压缩文件解压缩,分别将cuda/include、cuda/lib、cuda/bin三个目录中的内容拷贝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5对应的include、lib、bin目录下即可。
5、添加环境变量
把安装的CUDA的bin目录和libnvvp加到path环境中

6、测试代码
首先用以下代码,查看自己的设备信息
from tensorflow.python.client import device_lib
def get_available_gpus():
local_device_protos = device_lib.list_local_devices()
print(local_device_protos)
return [x.name for x in local_device_protos if x.device_type == 'GPU']
get_available_gpus()
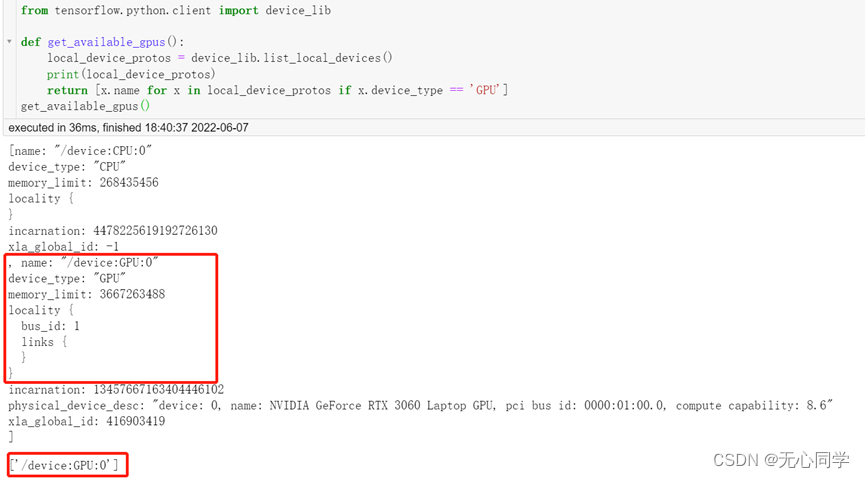
-
如果没有gpu说明安装的cuda版本不对,找不到电脑的gpu,需要在控制面板里面把CUDA开头的之前安装的版本的文件都卸载,再把C:\Program
Files\NVIDIA GPU Computing Toolkit全部删除,重复以上步骤安装对应的CUDA版本 -
如果以上代码运行发现有gpu了,说明版本没错,现在可以测试一下自己的代码了,通过一下代码指定使用gpu进行训练,直接开跑即可

如果弄好之后运行jupyter文件,每次都挂掉了,打开jupyter的命令行窗口查看,是否存在
Please make sure cudnn_cnn_infer64_8.dll is in your library path!
这句话,如果存在,首先检查自己的环境变量中是否在path中添加了这两个,没有的话添加进去

如果添加了还是这种情况,那么就是电脑中没有zlibwapi.dll文件。
打开这个网址
https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#install-zlib-windows

点击安装这个,解压下载的压缩包,打开dll_x64文件夹
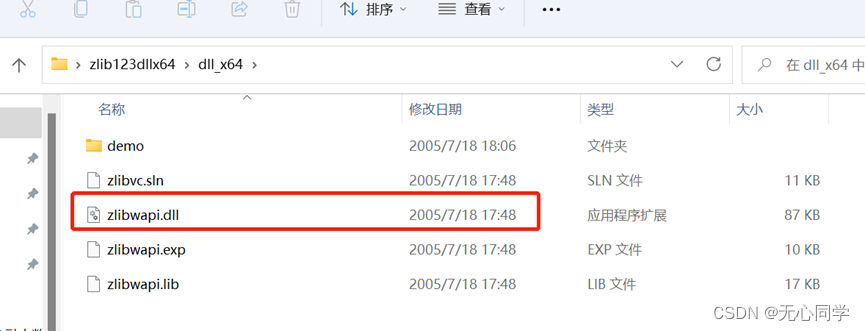
复制这个dll文件,将它复制到C:\Windows\System32目录下,重新启动jupyter,发现已经可以运行了
注意:multi_gpu_model这个方法是多个gpu运行才需要指定的,单个gpu直接开跑即可
参考文章:
https://blog.csdn.net/fun_always/article/details/103357840
https://www.jianshu.com/p/9bdeb033e765
https://blog.csdn.net/weixin_44704985/article/details/109500188
https://blog.csdn.net/qq_46126258/article/details/112708781