前言
呜呜呜,最近真的好久没有更新了,真的各种大作业,小唐都快要被自己整吐,到时候我期末大作业都会一一开源的,一个是基于python人脸识别app的搭建(Spring
boot+微信小程序+python),另外一个是垃圾识别(Spring
boot+微信小程序+python)换汤不换药,只是改变了python的识别啊哈哈哈哈哈,但是由于垃圾分类的准确率只有80%左右,加卷积和全链接又会欠拟合,所以在这里,我不得不重新去爬一些数据,今天就来说说吧!
小小炫耀一下啊哈哈哈哈哈
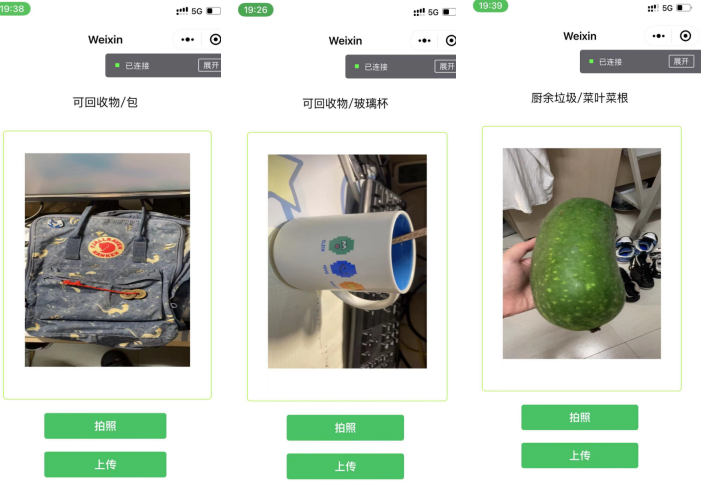
分析某平台网络结构
某平台链接:图像搜索
看过我之前静态网站的同学,应该都知道,对于静态网站是如何获取了的,就是去找我们的节点,一层一层的去分析和覆盖,然后提取类容,然后手动模拟换页 忘记了的看这里那对于动态的呢?
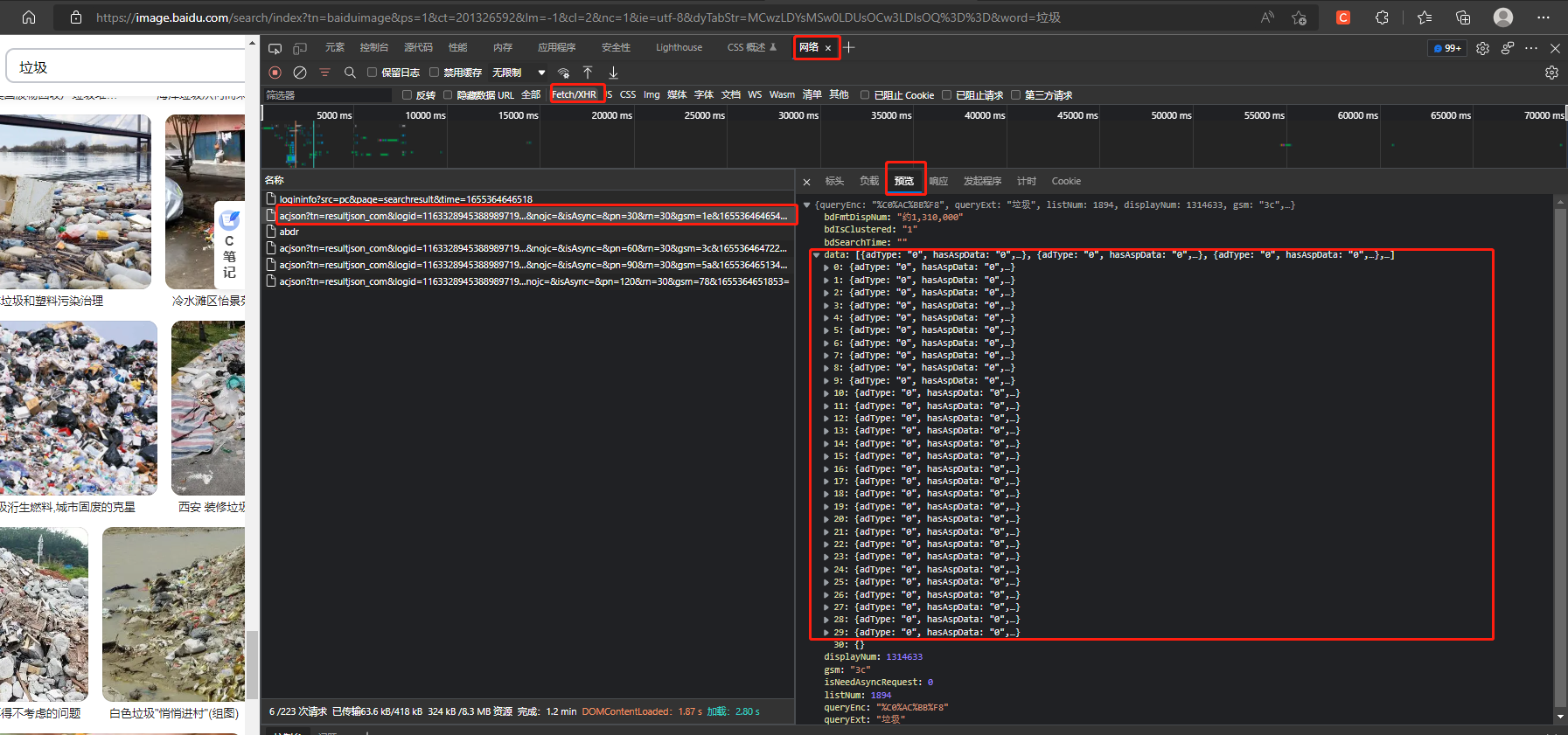
其实原理还是一样的,我们直接去看他的请求文件就可以了,我们直接F12打开我们的元素检查
这个时候,你会发现,喔嚯霍,代码是真的短,那么他所有的数据不说百分百,至少80,90都是请求来的
对于请求的数据,很简单
直接抓包分析,打开我们的网诺(一开始的时候是不记录的)
然后在我们页面那里往下面滑动,你会看到会有几个这样的文件随着我们滑动在增加
点击预览
这里存放的就是我们所有的图片数据啦!!!
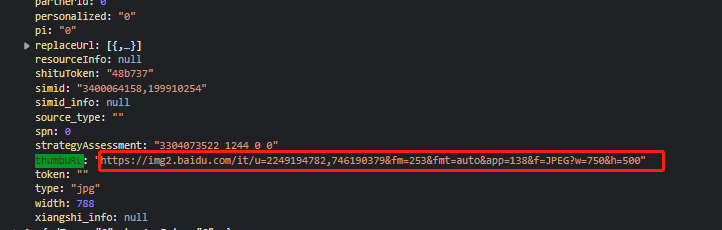
里面的thumburl就是我们图片的网诺地址,到时候一个正则就搞下来了再去观察观察,每一个什么什么acjson的文件
他是不是
30,60,90,120的在增加,很明显就是每30请求一次
简化一下,是不是
https://image.baidu.com/search/acjson?tn=resultjson_com&word={text}&pn=
后面的pn就是我们请求的页面数,前面的text就是我们需要查找的内容,做到这里,恭喜你已经学会了


代码
import os.path
import fake_useragent
import requests
import re
import uuid#用于随机生成不唯一的id(存储图片的时候用),你可以用雪花算法
#规范请求头
headers = {"User-agent": fake_useragent.UserAgent().random, # 随机生成一个代理请求
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Connection": "keep-alive"}
img_re=re.compile('"thumbURL":"(.*?)"')#用于定位图片位置
#解析保存图片
def TO_img(img_url,path):
img_resp=requests.get(img_url,headers=headers)
uuid_str = uuid.uuid4().hex#随机生成不唯一的id
path_name=path+"/"+uuid_str+".jpg"#通过路劲以及不唯一的文件名,手动加后缀,jpg
with open(path_name,'wb') as f:
f.write(img_resp.content)#content 字节码写入
f.close()
#提取每一页网页的图片
def get_img_list(url,page,path):
for i in range(1,int(page+1)):
url=url+str(i*30)
resp=requests.get(url,headers=headers)
if resp.status_code==200:#判断请求状态
img_list_url=img_re.findall(resp.text)#获取就是那个scjson的文件,并提取图片内容,findall是让他以列表返回
for img_url in img_list_url:
TO_img(img_url,path)
if __name__ == '__main__':
indexs =['其他垃圾 一次性快餐盒','其他垃圾 污损塑料','其他垃圾 烟蒂','其他垃圾 牙签','其他垃圾 破碎花盆及碟碗','其他垃圾 竹筷','厨余垃圾 剩饭剩菜',
'厨余垃圾 大骨头','厨余垃圾 水果果皮','厨余垃圾 水果果肉','厨余垃圾 茶叶渣','厨余垃圾 菜叶菜根','厨余垃圾 蛋壳','厨余垃圾 鱼骨','可回收物 充电宝','可回收物 包',
'可回收物 化妆品瓶','可回收物 塑料玩具','可回收物 塑料碗盆','可回收物 塑料衣架','可回收物 快递纸袋','可回收物 插头电线','可回收物 旧衣服','可回收物 易拉罐',
'可回收物 枕头','可回收物 毛绒玩具','可回收物 洗发水瓶','可回收物 玻璃杯','可回收物 皮鞋','可回收物 砧板','可回收物 纸板箱','可回收物 调料瓶','可回收物 酒瓶',
'可回收物 金属食品罐','可回收物 锅','可回收物 食用油桶','可回收物 饮料瓶','有害垃圾 干电池','有害垃圾 软膏','有害垃圾 过期药物']
path=r"D:\新建文件夹"
for index in indexs:
path_dir=os.path.join(path,index)#拼接文件夹
print("目前下载 "+str(index))
if not os.path.isdir(path_dir):#先看看文件夹在不在,不在就创建一个
os.makedirs(path_dir)
url = "https://image.baidu.com/search/acjson?tn=resultjson_com&word={text}&pn=".format(text=str(index.split()[1]))#读者需要修改的也就是这个,直接修改text的内容即可
get_img_list(url,15,path_dir)#三个参数分别为:需要请求的网址,请求多少页,保存路劲
最后来看看效果吧
你问为什么这么少?【手动狗头】
当然测试一下,就给别人啦!!!
啊哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈