
�����н����Ŵ�ҵ��һ��,���÷���credit riskҲ����ҵ�������ٵ�����Ҫ����,�ر�����С��ҵ������С��ҵ�Ŵ�ҵ���Ѹ�ٷ�չ,�ͻ�Ⱥ��IJ�������,��������ҵ(���,�ڴ�,st���й�˾)����,�����ڴ�������ǰ���ڿͻ���������ˮƽ�İ��ձ��Խ��Խ����.��ο�ѧ,���ٵ�ʶ����˿ͻ�����ҵ�ͻ����÷���,��ΪС����ҵ�����,������չ����Ҫǰ�ᡣ
���÷��ռ���ģ�Ϳ�������������������,��ҵ����������������������������������һϵ������ģ�����,������A��(�������ֿ�)��B��(��Ϊģ��)��C��(����ģ��)��F��(����թģ��)�� ��������չʾ���Ǹ�����������ģ�͵Ŀ�������,���ݲ���kaggle��֪����give me some credit���ݼ���
give me some credit���ݼ����õ��ǹ���������ʵ�����Ŵ�����,�������������Ŵ����ڷ��ա�give me some credit���ݼ���������,ֻ��ʮ���,��ÿ���������ܾ���,ֵ�����������о���
һ����ģ����
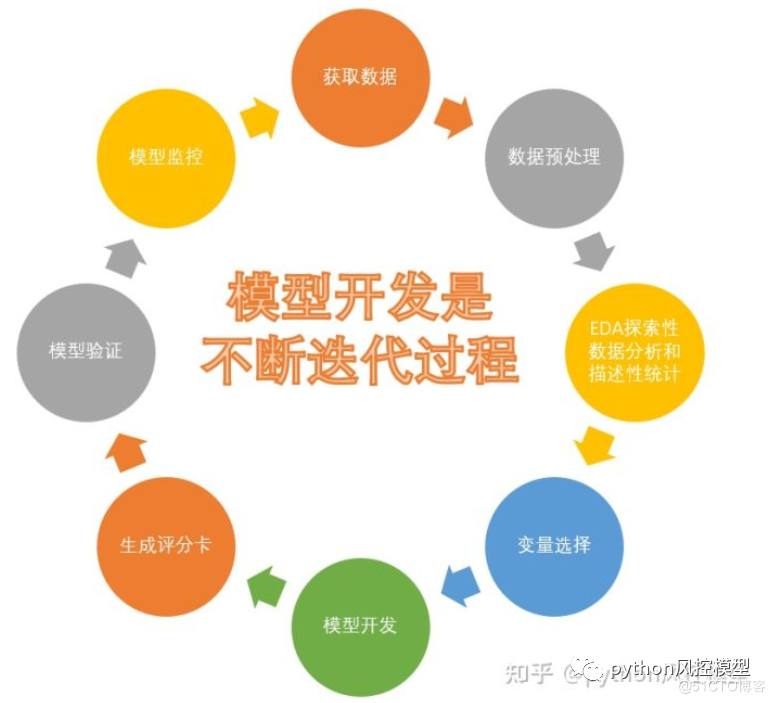
���͵��������ֿ�ģ����ͼ1-1��ʾ�����÷�������ģ�͵���Ҫ������������:
(1) ��ȡ����,�����������ͻ������ݡ����ݰ����ͻ�����ά��,��������,�Ա�,����,ְҵ,��������,ס�����,�������,ծ��ȵȡ�
(2) ����Ԥ����,��Ҫ��������������ϴ��ȱʧֵ�������쳣ֵ��������������ת���ȵȡ�������Ҫ��ԭʼ���ݲ��ת��Ϊ�ɽ�ģ���ݡ�
(3) EDA̽�������ݷ�����������ͳ��,����ͳ��������������С,�û��ͻ�ռ��,������������Щ,����ȱʧ��,����Ƶ�ʷ���ֱ��ͼ���ӻ�,����ͼ���ӻ�,��������Կ��ӻ��ȡ�
(4) ����ѡ��,ͨ��ͳ��ѧ�ͻ���ѧϰ�ķ���,ɸѡ����ΥԼ״̬Ӱ���������ı�������������ѡ���ܶ�,����iv,feature importance,����ȵ� ������ȱʧ��̫�ߵı���Ҳ����ɾ������ҵ������Ա�����û�м�ֵ����Ҳ����ɾ�����������ݼ���������й¶����,����ģ�������ܻ�ӽ�����,��Ҫ�߳�����й¶������
(5) ģ�Ϳ���,���ֿ���ģ��Ҫ�ѵ���woe����,��������,����ϵ�����㡣����woe���������ֿ����ѵ����ѵ�,��Ҫ�ḻͳ��ѧ֪ʶ��ҵ���顣Ŀǰ�����㷨���50����,û��ͳһ���,һ�����Ȼ����Զ�����,Ȼ�����ֶ���������,�������ģ���������,����ѡȡ���ŷ����㷨��
(6) ģ����֤,��ʵģ�͵�����������Ԥ���������ȶ��ԡ����������ȵ�,���γ�ģ����������,�ó�ģ���Ƿ����ʹ�õĽ��ۡ�ģ����֤����һ�������,���ǵ���ģ��,ģ������ǰ,ģ�����ߺ�����֤��ģ�Ϳ�����ά����һ��ѭ������,����һ����ɡ�
(7) �������ֿ�,�������ع�ı���ϵ����WOEֵ���������ֿ������ֿ�����ҵ�����,��ʹ�ü�ʮ��,�dz��ȶ�,���ܽ�����ҵϲ�����䷽�����ǽ�Logisticģ���ʷ�ת��Ϊ300-900�ֵı����ֵ���ʽ��
(8) �������ֿ�ģ��ϵͳ,�����������ֿ�����,����������Զ����û�����ϵͳ��������ͳ��ƷFICO�����ƹ���,FICO�ײ�������Java��Ŀǰ����Java,python��R�������Թ������ֿ��Զ���ģ��ϵͳ��
(9)ģ�ͼ��,��ʱ������,ģ����������,����ks,auc�����½�,ģ���ȶ���Ҳ�ᷢ��ƫ�ơ�������Ҫרҵģ�ͼ���Ŷ�,����ص�ģ�����������½�������ģ���ȶ��Է����ϴ�ƫ��ʱ,������Ҫ���¿���ģ��,����ģ�͡�ģ�ͼ���Ŷ�Ӧ��ÿ�հ�ʱ�ʼ�����ģ�ͼ�ر���������Ŷ�,�ر��ǿ����ŶӺ�ҵ���Ŷӡ�
��. ��ȡ����
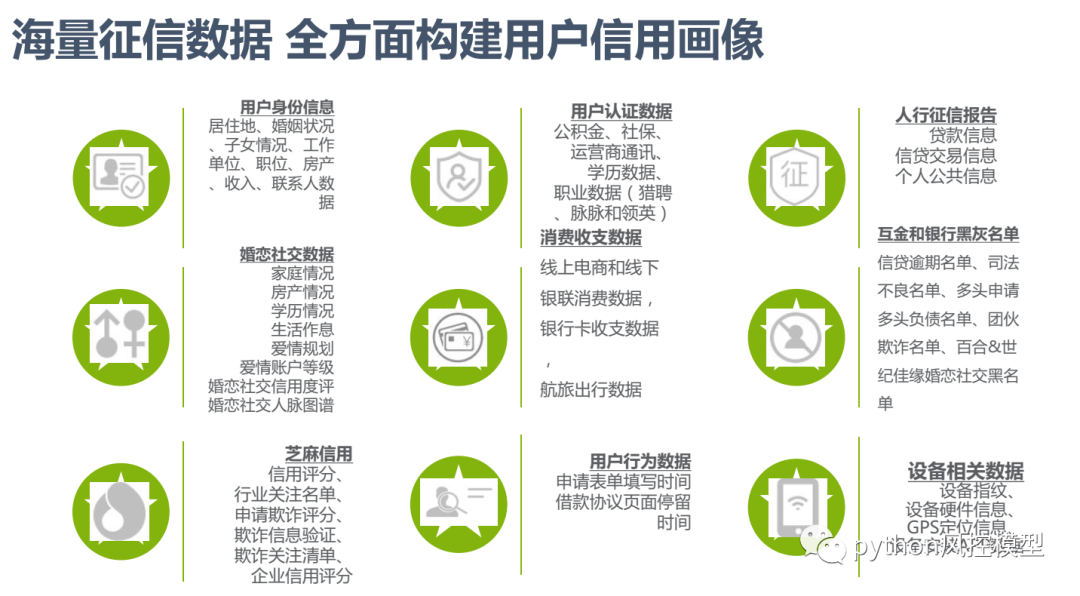
��ģ���ݷ�����������������д�Ļ�������,ͨѶ¼,ͨ����¼��������Ӫ������,�Լ�������������ƽ̨�ṩ�ĺ��������������ƽ̨�����������,��appץȡ���ֻ�����,��Щ��������������,�籣��������������ˮ,�������ѵ�����,��Բ�ͬ��ȺͿ�Ⱥ��Ҫ�û���д����Ȩ�����ϲ�һ�����ռ���Ҫ�����ݺ�,ͨ��SQL��ȡ��ر����������콨ģ�õĿ��������彨ģ��Ϣ����ͼ��
python���ֿ���ģʵս���ݼ�
֮ǰ�ҽ�������German credit�¹��������ݼ�����python�������ֿ�ģ��,�����ݼ�������������С,�Լ����Ӳ��Ҫ��,��������ײ�ѧԱѧϰ�Ͳ��ԡ�

���������㷨��ΥԼ���ʽ��в²�,����������ȷ���Ƿ�Ӧ�������ķ������������ڸ������������,ͨ��Ԥ��ij����δ���������������������Ŀ�����,����������ֵ�����ˮƽ��
�������г������з�����������Ҫ�����á����Ǿ���˭���Ի���ʽ��Լ���ʲô��������ʽ�,���ҿ�������Ͷ�ʾ�����ֹͶ�ʾ�����Ϊ�����г�����ᷢ������,���˺�˾��Ҫ����Ŵ���
give me some credit��15����������,������������д��ͽ��ڻ���ʵս����,���ӽӽ�������ҵ��Ŀʵս�������ݼ�ͨ��Ԥ��ij����δ�������������������ѵĿ�����,����������ֵ�ˮƽ��

������������,�����ٶ���,����Ϊ��ģ�IJο�

���Ƕ�������������,��Ҫ��Ϊ:
�C ��������:�����˽���˵�ʱ�����䡣
�C ��ծ����:�����˽���˵Ŀ��ö�ȱ�ֵ�������롢��ծ���ʡ�
�C ������ʷ:������35-59�����ڴ�����������60-89�����ڴ�����������90
������90�����ڵĴ�����
�C �Ʋ�״��:�����˿���ʽ�Ŵ��ʹ����������������������������
�C ��������:����˵ļ�������(��������������)
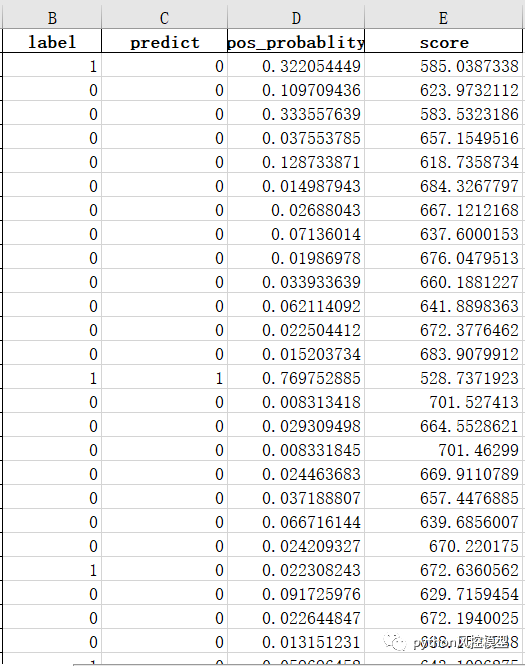
kaggleģ�;�����,����5000����,ģ������ָ��ΪAUC��
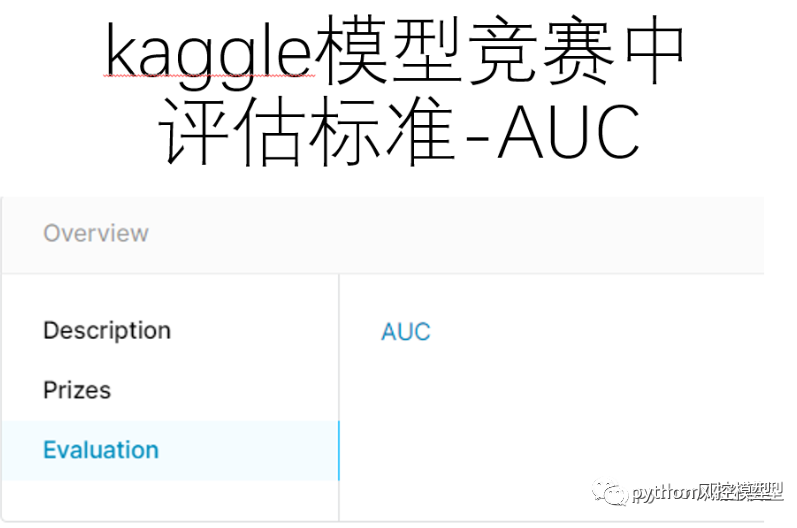
�������Ϲ��������give me some credit���ݼ�AUC�÷���ѱ���Ϊ0.85.
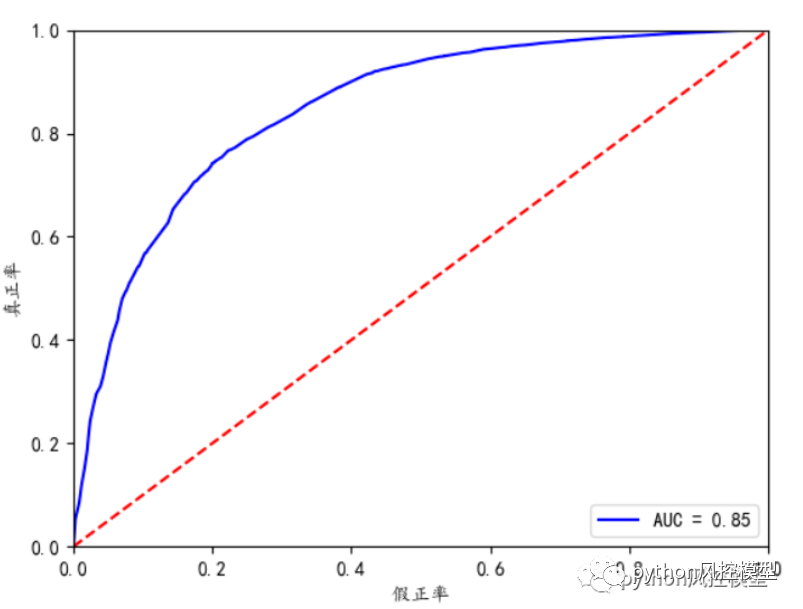
���ҷ���python�������ֿ���ģ(������)���̳���AUC���Դﵽ0.929,���κ�AUC���Ը���,Զ���ڻ�������give me some credit���ĵ�ģ������AUC=0.85�����������Ĺ��ڽ�ģ�����кܶ������,��ʵ���ϲ���ȷ�����ۡ�
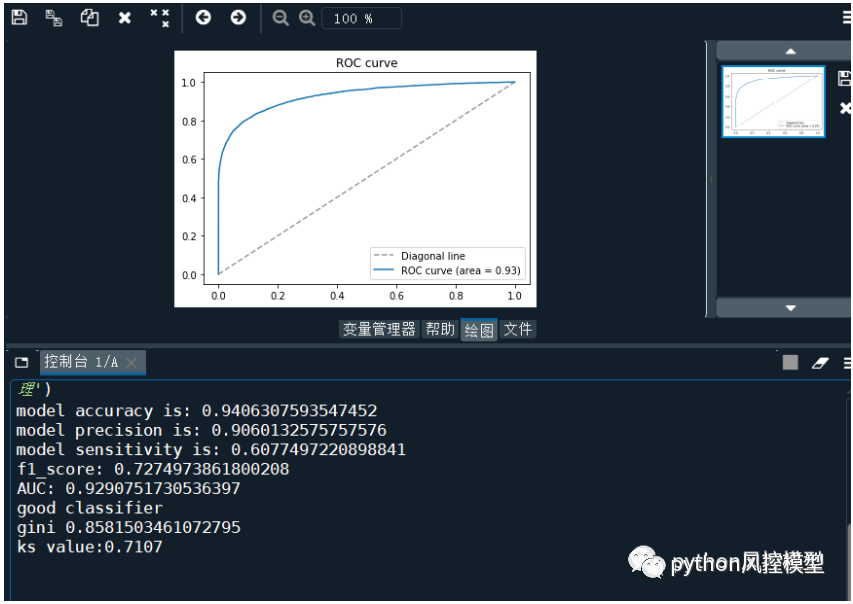
���������ҷ���ν�give me some credit���ݼ�AUC�ﵽ0.929,�ɲο��̳���python�������ֿ���ģ(������)��
��python�������ֿ���ģ(������)����give me some credit���ݼ�һ����
��������Ԥ����
����Ԥ����,��Ҫ��������������ϴ��ȱʧֵ�������쳣ֵ��������������ת���ȵȡ�������Ҫ��ԭʼ���ݲ��ת��Ϊ�ɽ�ģ���ݡ�
3.1 ȱʧֵ����
give me some credit���ݼ�ȱʧ���ݲ�������,ֻ������������ȱʧֵ,ȱʧ��Ϊ2%��19.8%��
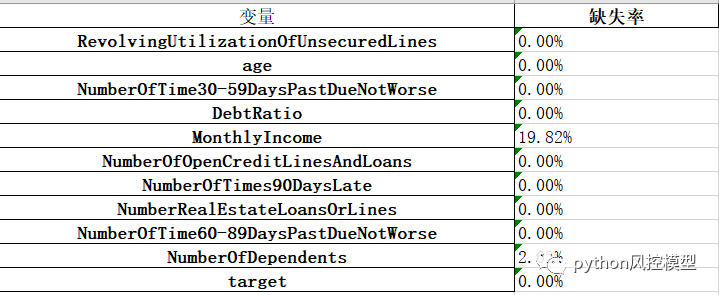
��ʵ�����ݴ��ڴ���ȱʧֵ�Ƿdz��ձ顣�������źܶ����ȱʧ�ʿ��Ըߴ�99%��ȱʧֵ�ᵼ��һЩ���ݷ����ͽ�ģ�����⡣ͨ�������÷������ֿ�ģ�Ϳ����ĵ�һ�����Ǿ�Ҫ����ȱʧֵ������ȱʧֵ�����ķ���,�������¼��֡�
(1) ֱ��ɾ������ȱʧֵ��������
(2) �ȱʧֵ��
(3) �������ǡ�
# �����ɭ�ֶ�ȱʧֵԤ����亯��
def set_missing(df):
# �����е���ֵ������ȡ����
process_df = df.ix[:,[5,0,1,2,3,4,6,7,8,9]]
# �ֳ���֪��������δ֪������������
known = process_df[process_df.MonthlyIncome.notnull()].as_matrix()
unknown = process_df[process_df.MonthlyIncome.isnull()].as_matrix()
# XΪ��������ֵ
X = known[:, 1:]
# yΪ�����ǩֵ
y = known[:, 0]
# fit��RandomForestRegressor֮��
rfr = RandomForestRegressor(random_state=0,
n_estimators=200,max_depth=3,n_jobs=-1)
rfr.fit(X,y)
# �õõ���ģ�ͽ���δ֪����ֵԤ��
predicted = rfr.predict(unknown[:, 1:]).round(0)
print(predicted)
# �õõ���Ԥ�����ԭȱʧ����
df.loc[(df.MonthlyIncome.isnull()), 'MonthlyIncome'] = predicted
return df
3.2 �쳣ֵ����
ȱʧֵ������,������Ҫ�����쳣ֵ���顣�쳣ֵ��Ϊͳ��ѧ���쳣ֵ��ҵ�����쳣ֵ��ͳ��ѧ�쳣ֵͨ��������ͼ���ж�,����ͼ��
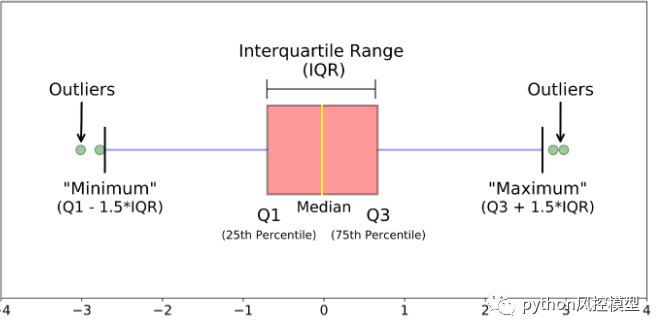
ҵ�����쳣ֵ�Ǹ���ҵ���߶Ա�������ͳ�ʶ���жϸ������Ƿ����������give me some credit���ݼ����и��˿ͻ�������Ϊ0,���ճ���,������Ϊ��ֵΪ�쳣ֵ���ĸ����˾���Ǯ�������Ϊ0���û�?
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-VREOZt7u-1655519142398)(https://mmbiz.qpic.cn/mmbiz_png/WtYjVK9Gib5dGcpQZ3FajMfH4CLwrDj4lodbd06JJpUwU01VFRXma0I0AfydodXMLpDWXBQPmWuKqVS2HLJVOBQ/640?wx_fmt=png)]
3.3 ���ݻ���
���ǽ���ģ�ͺ�һ������������������,underfittingǷ���,just right��Ϻ���,overfitting������ϡ�
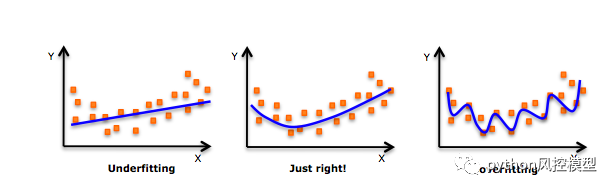
Ϊ����֤ģ�͵�����,������Ҫ�����ݼ����л��֡�
���Ȱ��������ݷֳ�x���ݺ�y����(targetĿ�����)��
Ȼ���x���ݺ�y���ݷֳ�ѵ�����Ͳ��Լ�,�������ĸ�����train_x,test_x,train_y,test_y.

�ġ�EDA̽�������ݷ�����������ͳ��
�����˴��Ե������ṹ,���˶����ֲ�����,�����ݿ��ӻ��Դ���������Ѻá���������ݿ��ӻ���Ҫ��,Ҳ�������쵼����߲�㱨������
EDA̽�������ݷ�����������ͳ�ư���ͳ��������������С,�û��ͻ�ռ��,������������Щ,����ȱʧ��,����Ƶ�ʷ���ֱ��ͼ���ӻ�,����ͼ���ӻ�,��������Կ��ӻ��ȡ�EDA��Exploratory Data Analysis��д,��������Ϊ̽�������ݷ�����̽�������ݷ��������ܶೣ������:histֱ��ͼ��scaterɢ��ͼ,boxer����ͼ,heat����ͼ,pairplot���ͼ��
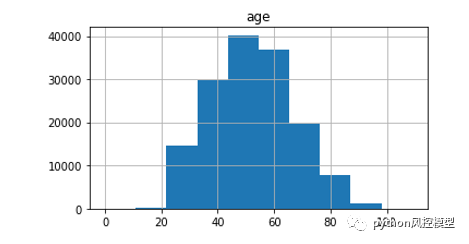
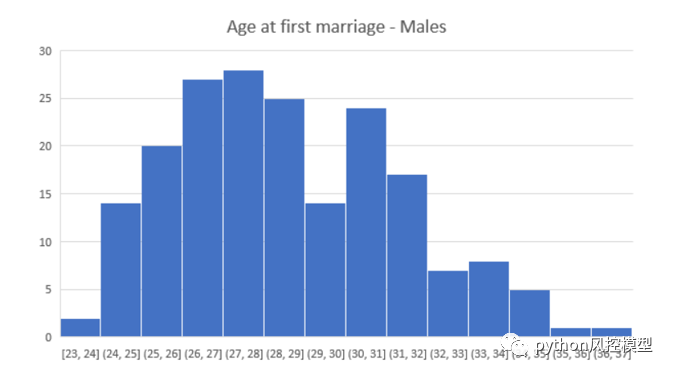
give me some credit���ݼ���age�������ֱ��ͼ
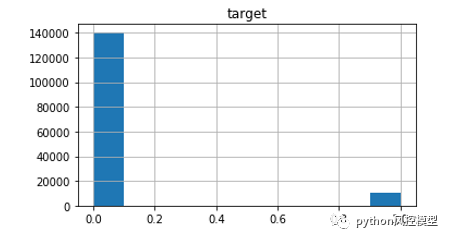
give me some credit���ݼ���targetĿ�����ֱ��ͼ,���Է��ֺû��ͻ�ռ�ȷdz���ƽ�⡣�ÿͻ���������ǻ��ͻ�����15�����ҡ�
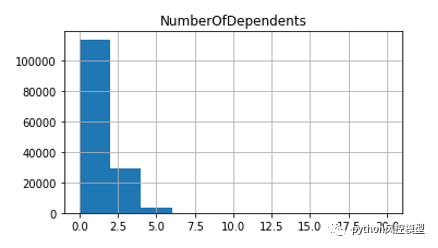
give me some credit���ݼ��ļ�ͥ��Ա��������ֱ��ͼ
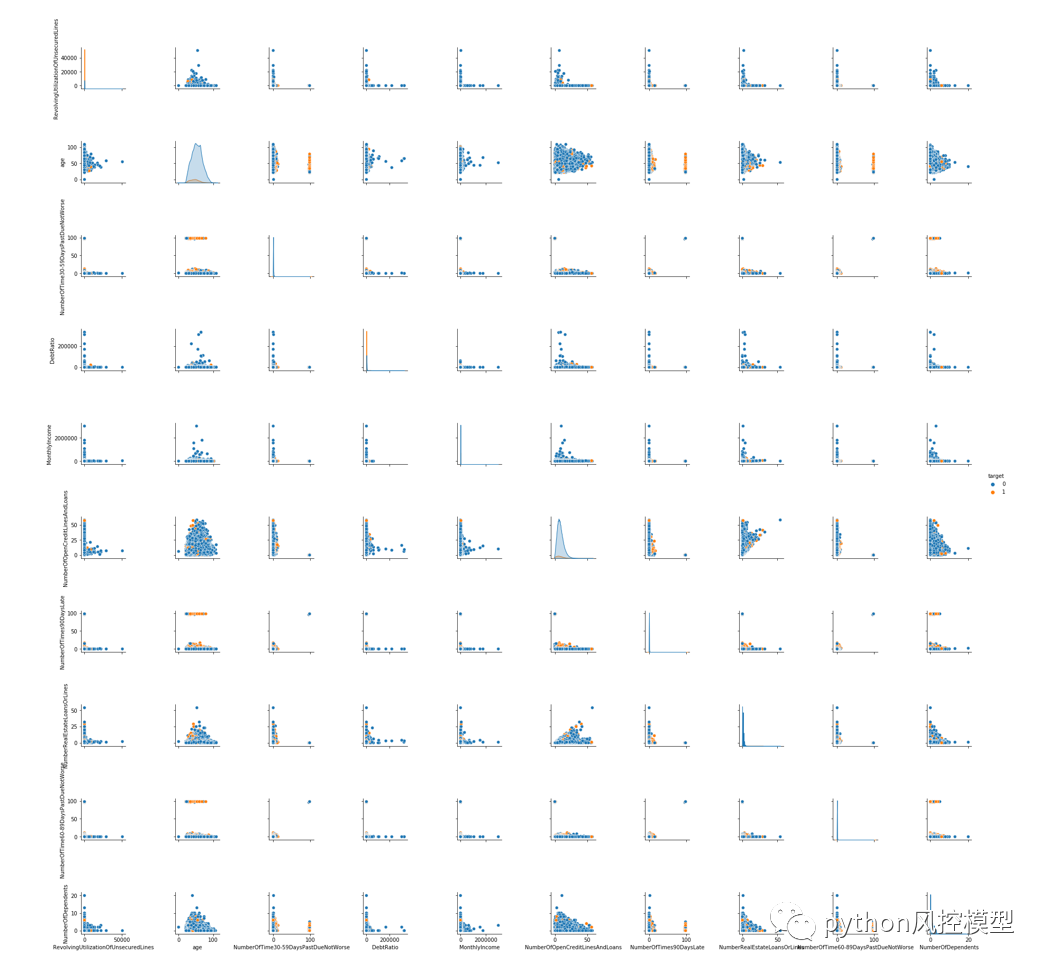
give me some credit���ݼ����б�����pairplot���ͼ,������ϢһĿ��Ȼ��
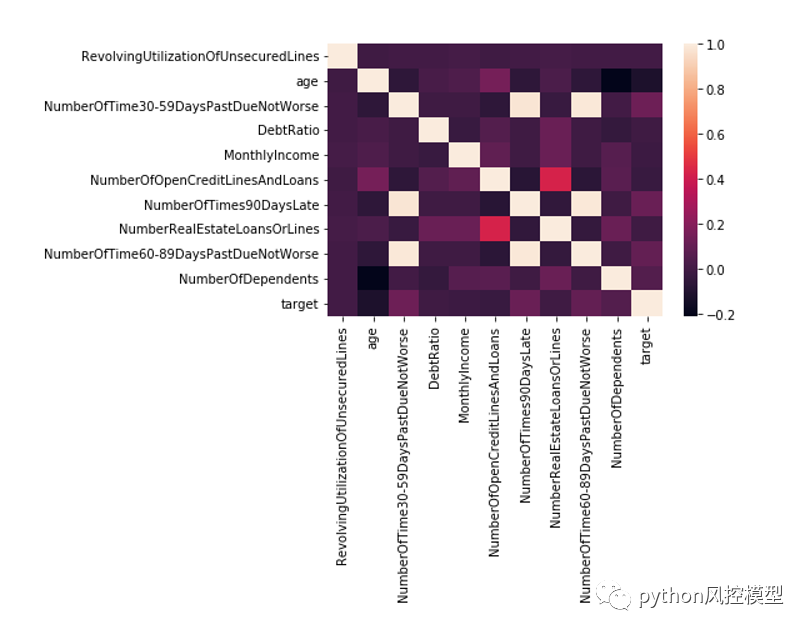
give me some credit���ݼ����б�������Ե�����ͼ,���Է�������6�Ա�������Էdz���,����ɸѡʱ����Ҫע�⡣
corr = data.corr()#����������������ϵ��
xticks = ['x0','x1','x2','x3','x4','x5','x6','x7','x8','x9','x10']#x���ǩ
yticks = list(corr.index)#y���ǩ
fig = plt.figure()
ax1 = fig.add_subplot(1, 1, 1)
sns.heatmap(corr, annot=True, cmap='rainbow', ax=ax1, annot_kws={'size': 9, 'weight': 'bold', 'color': 'blue'})#���������ϵ������ͼ
ax1.set_xticklabels(xticks, rotation=0, fontsize=10)
ax1.set_yticklabels(yticks, rotation=0, fontsize=10)
plt.show()
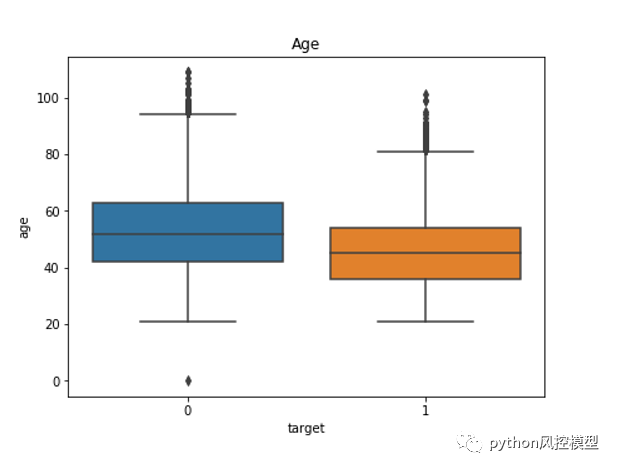
give me some credit���ݼ�age����������ںû��ͻ��ķ�������ͼͳ�ơ����ǿ��Կ����ÿͻ�������λ��Ҫ���ڻ��ͻ�������λ����
�塢����ѡ��
����ѡ��,ͨ��ͳ��ѧ�ͻ���ѧϰ�ķ���,ɸѡ����ΥԼ״̬Ӱ���������ı�������������ѡ���ܶ�,����iv,feature importance,����ȵ� ������ȱʧ��̫�ߵı���Ҳ����ɾ������ҵ������Ա�����û�м�ֵ����Ҳ����ɾ����
��python�������ֿ���ģ(������)���̳��м������㷨catboost��feature importance���ӻ�ͼ,���ǿ������Կ���RevolvingUtilizationOfUnsecuredLines���ö�ȱ�ֵ��������Ҫ����ߡ�ͼ����ɫ��Խ��,��Ҫ��Խ��,��֮��Ȼ��
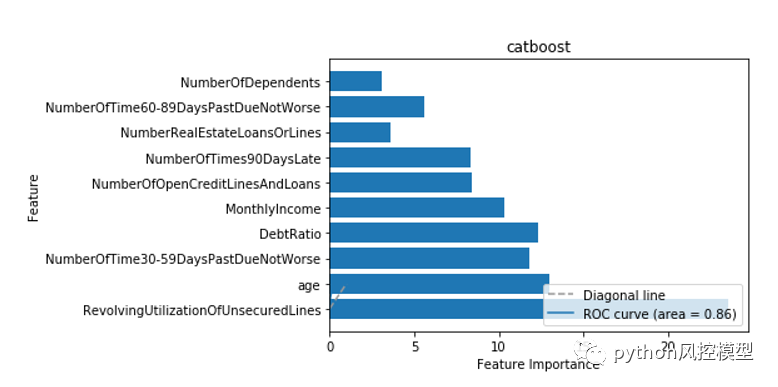
��python�������ֿ���ģ(������)���̳��б���ivֵ����������,������������RevolvingUtilizationOfUnsecuredLines���ö�ȱ�ֵ������iv��ߡ�

ͨ��feature importance��ivֵ�������Ƕ��õ�ͬ������:RevolvingUtilizationOfUnsecuredLines���ö�ȱ�ֵ����������Ҫ�ġ�
����й¶
����й¶��һ��ר������,��ʾ����ģ������targetĿ��������ü�������,��������ģ����ǰ֪��Ԥ����,��������,ģ�ͱ��ֽӽ�����,����ͼ��
���DZ���ɸѡ������Ҫ�����Ƿ��������й¶������
���ҷ����ܶ�,��÷����ǿ���������ԡ�����й©������targetĿ���������Ի�ӽ�1

�ڶ��ַ�����ģ�ͷ�,ͨ��������Ҫ�����۲�����й©����������ͼlightgbm������й©�۲���Ч������catboost��lightgbm������Ҫ��������,ÿ������Ȩ�ض��ῼ�����ƽ�⡣catboost������Ҫ�Ի�ͻ����Ҫ����,�����������ҳ�����й©������
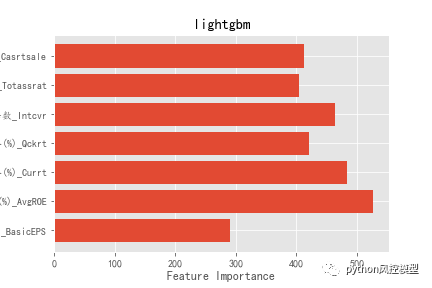
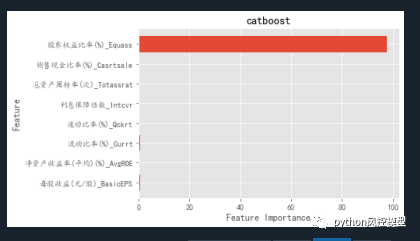
�ҷ���python��ؽ�ģʵսlendingClub���̳����ص������catboost�㷨ϸ������,����Ȥ���ѿ�ǰ���˽⡣
??????????????????????????????����ģ�Ϳ���??????????????????????????????
��ͼ�ǽ���������ģ�͵ij����㷨,ģ����֤������ģ�ͼ�����ݽṹ��չʾ
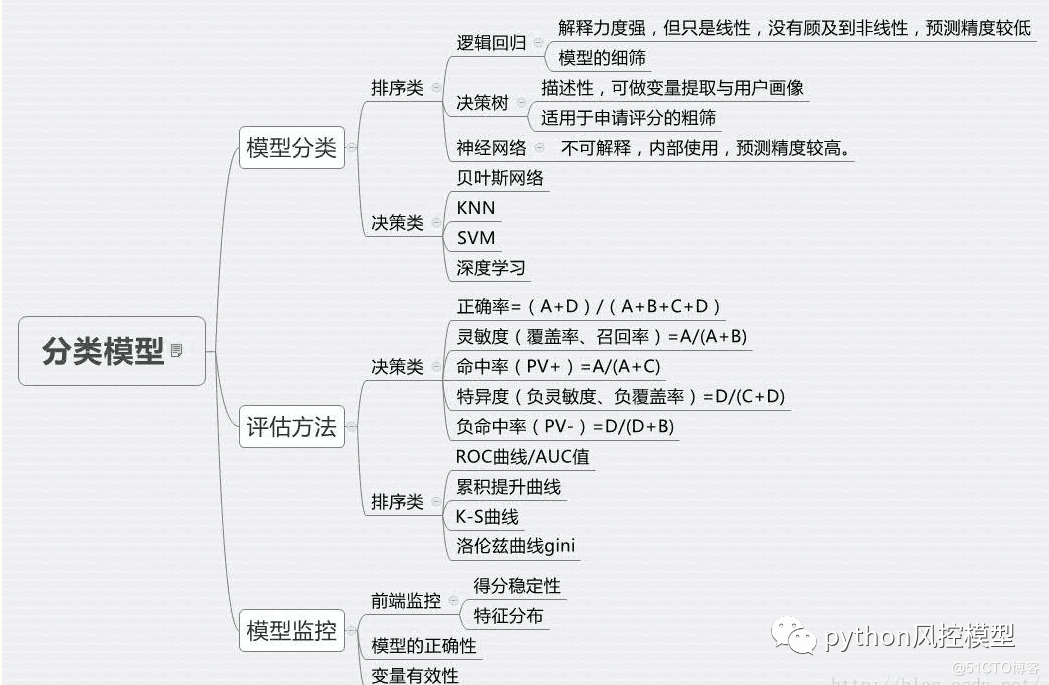
���ع�,������,���ɭ�ֲ�ͬ�㷨�ĶԱ�����ͼ
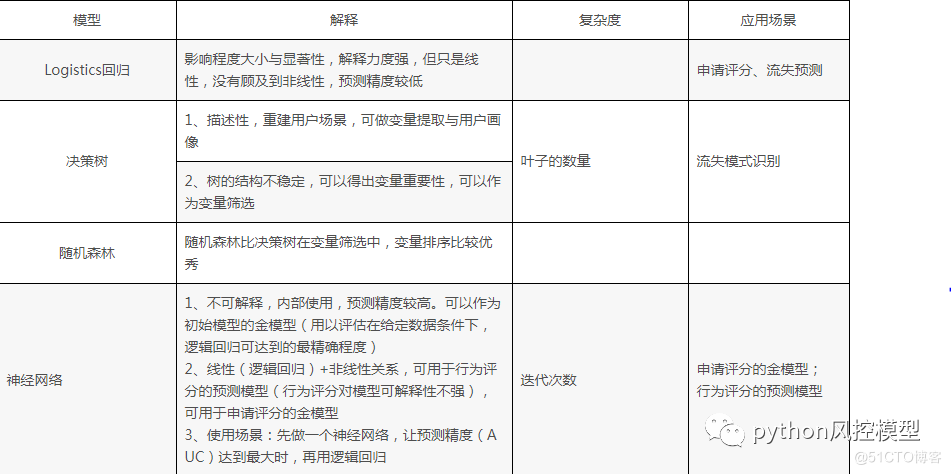
���ع������:
�����Ͽ��Է�Ϊ,
1. ��Ԫ���ع顪���������Ԫ���,���ǻ��
2. ���� Logistic �ع� - �����������,��һ�ȡ����Ⱥ����Ȼ���ѧλ
3.�������ع顪����������������ڶ������ع顣
���ֿ�ģ�Ϳ����õ������ع顣���ع��һ���ѵ���sigmoid����,���Ǽ���һ��sigmoid���������ع��ϵ��
Logit ������ Sigmoid ���� - Logistic �ع�:
���ع���Ա�ʾΪ,
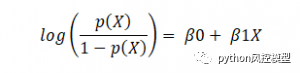
���� p(x)/(1-p(x)) ��Ϊ����,����Ϊ logit �� log-odds �����������dzɹ�������ʧ�ܼ��ʵı�ֵ�����,�����ع���,�����������ϱ�ת��Ϊ log(odds),���Ϊ 1��
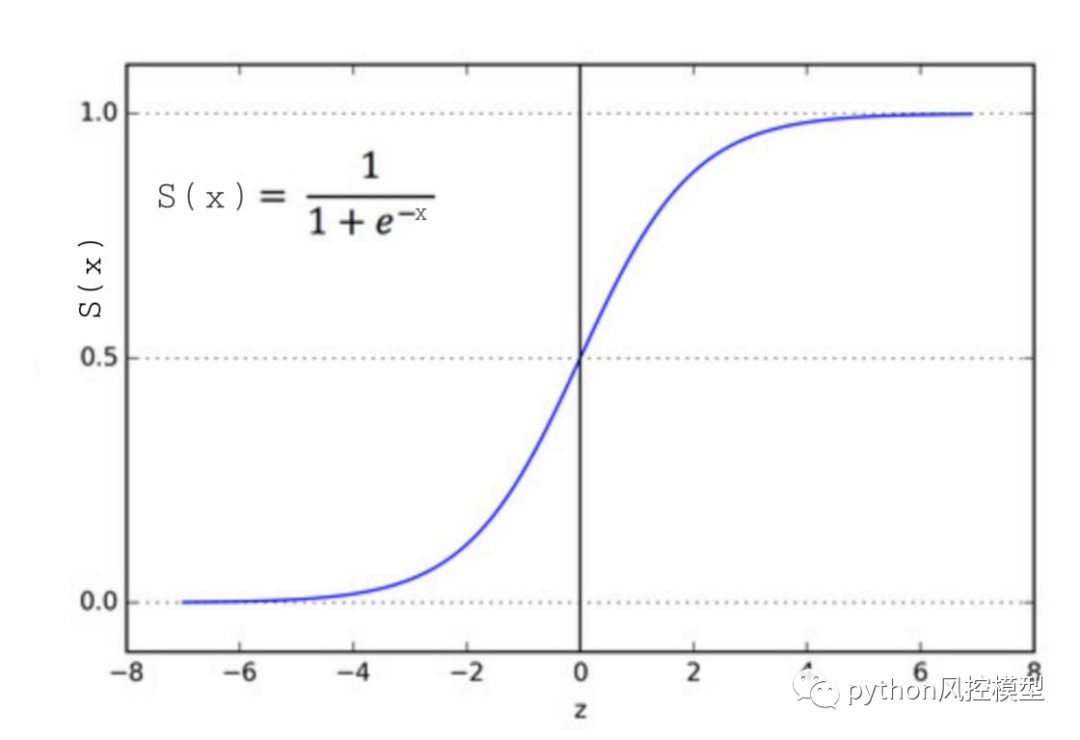
���������������ķ�����
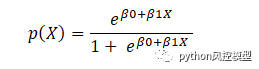
���� Sigmoid ����,������ S �����ߡ������Ƿ���һ������ 0 �� 1 ֮��ĸ���ֵ��Sigmoid �������ڽ�����ֵת��Ϊ���ʡ��ú������κ�ʵ��ת��Ϊ 0 �� 1 ֮������֡��������� sigmoid ��Ԥ��ת��Ϊ����ѧϰ�еĸ��ʡ�
��ѧ�ϵ� sigmoid ����������,
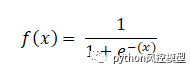
ģ�Ϳ���,���ֿ���ģ��Ҫ�ѵ���woe����,��������,����ϵ�����㡣����woe���������ֿ����ѵ����ѵ�,��Ҫ�ḻͳ��ѧ֪ʶ��ҵ���顣Ŀǰ�����㷨���50����,û��ͳһ���,һ�����Ȼ����Զ�����,Ȼ�����ֶ���������,�������ģ���������,����ѡȡ���ŷ����㷨��
��python�������ֿ���ģ(������)������Kmeans,��Ƶ���䡢�Ⱦ����,��������,�����������㷨ԭ����pythonʵ�ַ�����롣��python�������ֿ���ģ(������)�������������ѡ����䷽��?�ڲ�ͬ������,ѡ������ʷ��䷽����
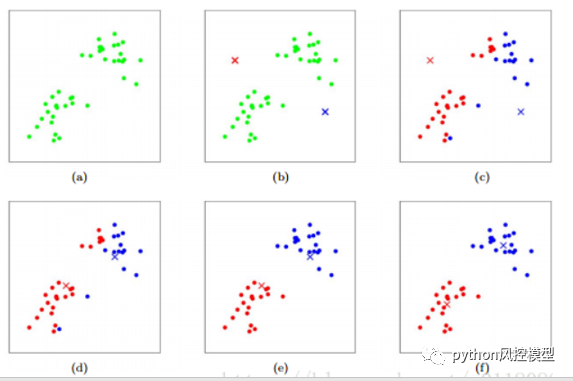
������Ҫ��Ϊ�мල�������ල������k��ֵ�����㷨(k-means clustering algorithm)��һ�ֵ������ľ�������㷨,�䲽����,Ԥ�����ݷ�ΪK��,�����ѡȡK��������Ϊ��ʼ�ľ�������,Ȼ�����ÿ��������������Ӿ�������֮��ľ���,��ÿ��������������������ľ������ġ����������Լ���������ǵĶ���ʹ���һ�����ࡣÿ����һ������,����ľ������Ļ���ݾ��������еĶ������¼��㡣������̽������ظ�ֱ������ij����ֹ��������ֹ����������û��(����С��Ŀ)�������·������ͬ�ľ���,û��(����С��Ŀ)���������ٷ����仯,���ƽ���;ֲ���С����ͼ��Kmeans�����㷨ԭ����
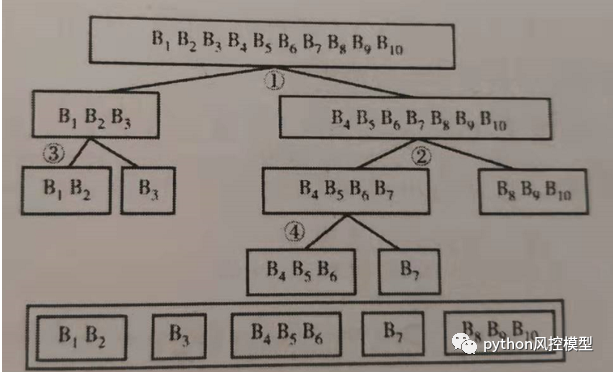
��˵�е����ŷ�����Ǿ��������䡣
�����������㷨����Ϊ:
���� 1:����,��ʹ��������Ҫ��ɢ���ı�����ѵ��һ���������(2��3 �� 4)�ľ�������Ԥ��Ŀ�ꡣ
_�� 2 ��:_Ȼ��ԭʼ����ֵ�滻Ϊ�����صĸ��ʡ����� bin �ڵ����й۲�ֵ�ĸ�����ͬ,����ø����滻�൱�ڽ������������Ľ�ֵֹ�ڵĹ۲�ֵ���顣
�����������㷨�ô���ȱ����:
�ô� :
-
����Ԥ�ⷵ�صľ�������Ŀ�굥����ء�
-
�µ� bin ��ʾ�����ٵ���,����ÿ��Ͱ/Ͱ�ڵĹ۲����������Լ������ƶ�,����������Ͱ/Ͱ�Ĺ۲�����
-
�����Զ��ҵ������䡣
ȱ��:
-
���ܻᵼ�¹����
-
����Ҫ����,������Ҫ������������һЩ�����Ի����ѷָ�(����,��ȡ�һ�������е���С��������������������С��Ϣ����)������ܺܺ�ʱ��
(������������ӻ�)
�Ⱦ�������������age����ı�����
������ɺ�,�Ͱѷ�������ת��Ϊwoe����,��������ع��㷨��ģ��
����ļ���
# �����Զ����亯��
def mono_bin(Y, X, n = 20):
r = 0
good=Y.sum()
bad=Y.count()-good
while np.abs(r) < 1:
d1 = pd.DataFrame({"X": X, "Y": Y, "Bucket": pd.qcut(X, n)})
d2 = d1.groupby('Bucket', as_index = True)
r, p = stats.spearmanr(d2.mean().X, d2.mean().Y)
n = n - 1
d3 = pd.DataFrame(d2.X.min(), columns = ['min'])
d3['min']=d2.min().X
d3['max'] = d2.max().X
d3['sum'] = d2.sum().Y
d3['total'] = d2.count().Y
d3['rate'] = d2.mean().Y
d3['woe']=np.log((d3['rate']/(1-d3['rate']))/(good/bad))
d4 = (d3.sort_index(by = 'min')).reset_index(drop=True)
print("=" * 60)
print(d4)
return d4
�ߡ�ģ����֤
���ع��㷨��ģ��,������Ҫģ����֤��ģ����֤�Ǻ�ʵģ�͵�����������Ԥ���������ȶ��ԡ�����������ָ���Ƿ�ϸ�,���γ�ģ����������,�ó�ģ���Ƿ����ʹ�õĽ��ۡ�ģ����֤����һ�������,���ǵ���ģ��,ģ������ǰ,ģ�����ߺ�����֤��ģ�Ϳ�����ά����һ��ѭ������,����һ����ɡ�
��ʱ������,ģ����������,����ks,auc�����½�,ģ���ȶ���Ҳ�ᷢ��ƫ�ơ���ģ�����������½�������ģ���ȶ��Է����ϴ�ƫ��ʱ,������Ҫ���¿���ģ��,����ģ�͡�
ģ����ָ֤���漰���ű���Ҫ����sklearn��metrics,����ָ������:
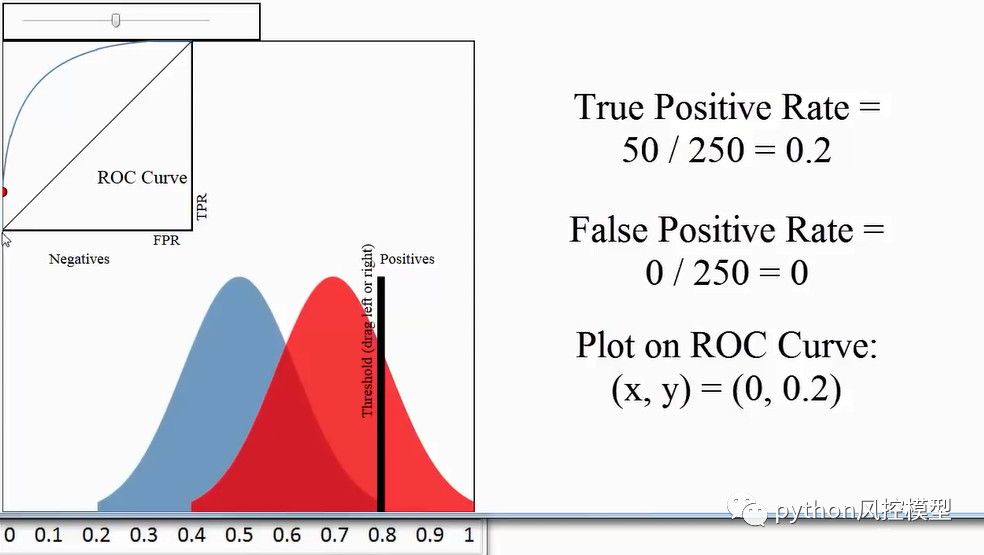
��������������ROCָ��:
�ܶ�ͳ��ָ����Դ��ս����ROC��������Ӣ���״�ֱ����¹��ɻ��ĸ��ʡ���ս�ڼ��״����ڷ����״���Ч�ԡ�����Щʱ���״�,��ʱ���Ѵӷɻ��Ϸֱ��һֻ��Ӣ��������ʹ�� ROC �������Ż����������״�����б�ķ�ʽ����Ϯ�ĵ¹��ɻ�������֮�䡣
AUC(area under the curve)�ǻ���ѧϰ������һ�ֳ�������Ҫ��ģ������ָ��,���ڼ����Ԫ������Ч�ʵķ�����AUC��ʾROC(receiver operator characteristic)�����µ����,��AUC = ROC �����������
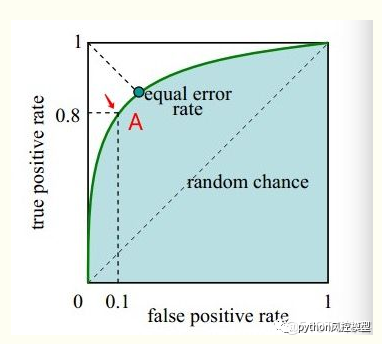
sensitivity=��ɫ�����ұߺ�ɫ�������/��ɫ���������
false positive=��ɫ�����ұ���ɫ�������/��ɫ���������
�����ǶԲ�ͬ����ֵ���б���ʱ,������ (������, ������) �����Ҳ�Ϳ�������ROC����,����������������AUC��
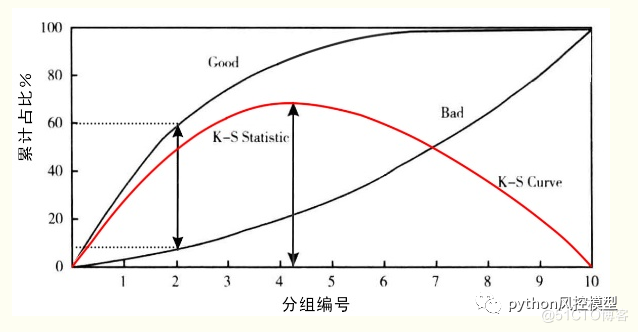
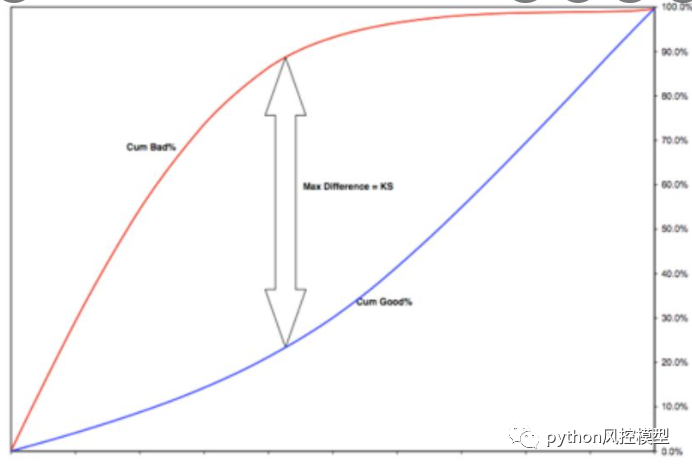
K-Sֵ
�����һ��ģ�ͺ�,������ģ�͵�����ƽ���ֳ�10��,�Ժ�����ռ�Ƚ�������ҽ�������,���е�һ��ĺ�����ռ�����,������ռ����С����KS����Ӧ������������ģ����Ҫ��Ϊ����֤ģ�Ͷ�ΥԼ�������������,ͨ������ģ��Ԥ��ȫ���������������ֺ�,��ȫ��������ΥԼ���ΥԼ��Ϊ������,Ȼ����KSͳ���������������������������ֵķֲ��Ƿ����������졣
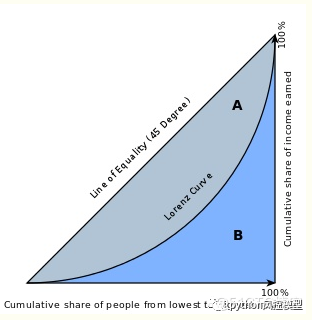
GINIϵ��
ʹ�����״�����,��������Ԥ��ΥԼ�ͻ��ķֲ���
����ϵ��������ͳ�ƺ�۾��õ�ƶ����ࡣ���罫һ���������е��˿ڰ���ƶ���н�������,�����������ۼ�,��Щ�˿���ӵ�еIJƸ��ı���Ҳ�����ӵ�100%,����������õ�ͼ�е�����,��Ϊ���������ߡ�����ϵ������ͼ��A/B�ı��������Կ���,�������������е���Ⱥ��ռ����Խ��IJƸ�,ƶ�����Խ��,��ô���״����߾ͻ�Խ����,����ϵ����Խ��
����ϵ����ʾ���Ǻÿͻ��ı���(�ۼ�),���������пͻ�������ʾ��ģ�������ģ����Ⱦ��и��÷��������ij̶ȡ���Ҳ����Ϊ����ָ��������ϵ������ȡ-1 ��1 ֮���ֵ����ֵ��Ӧ�ڷ��������෴��ģ�͡�
���濴����ϵ���ļ��㲽��:
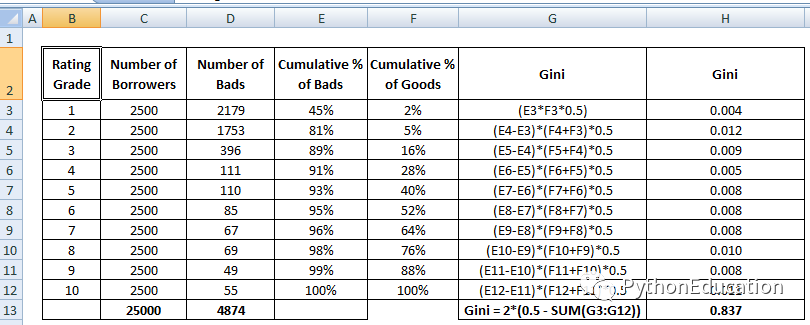
��ROCͼ��,GINI=A/(A+B)=A/C=(A+C)/C-1=AUC/C-1
����,C=1/2 ����,GINI=2AUC-1
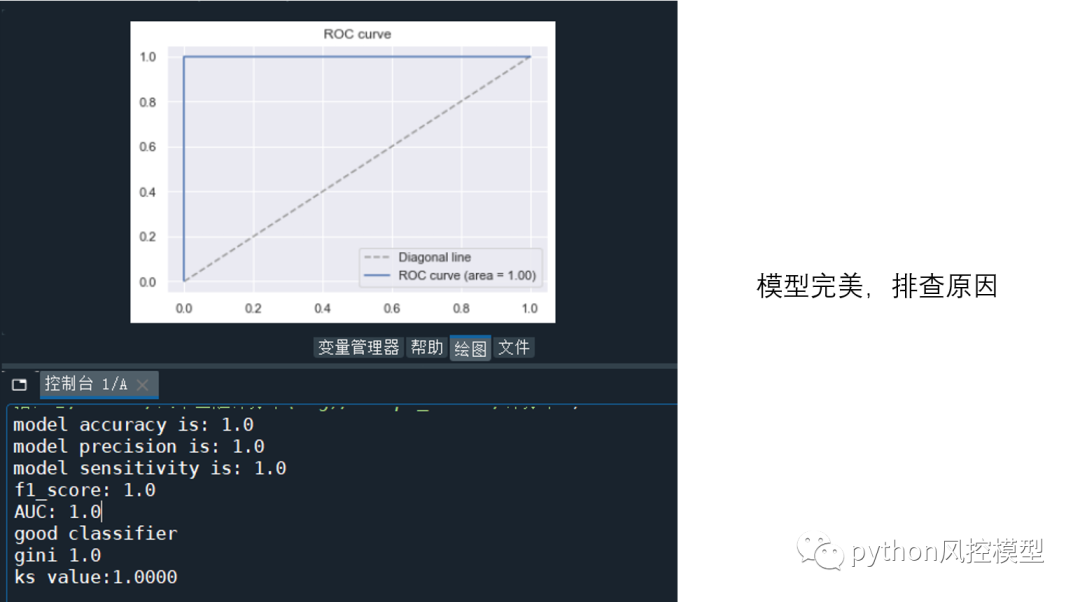
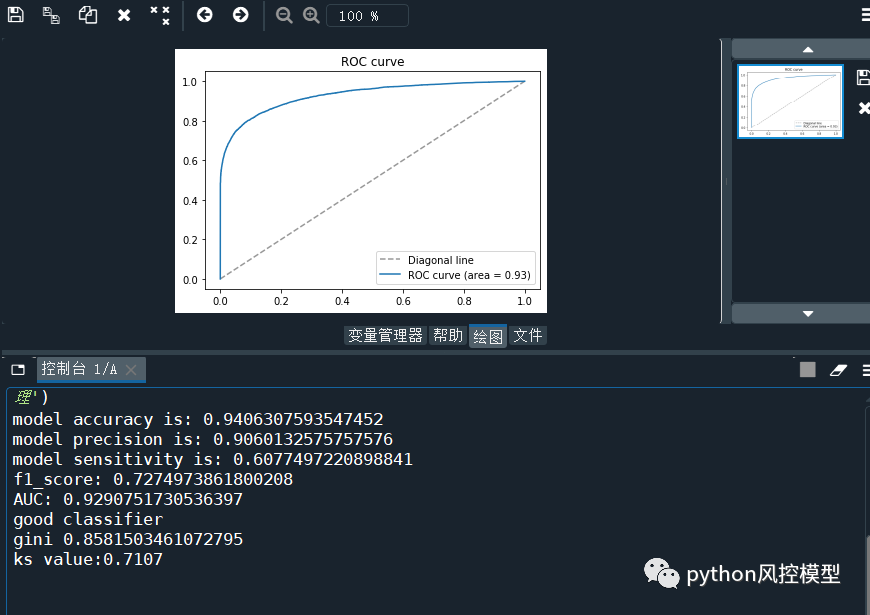
��python�������ֿ���ģ(������)���̳���ѵ��ģ��AUCΪ0.929,����ģ����������:
model accuracy is: 0.9406307593547452
model precision is: 0.9060132575757576
model sensitivity is: 0.6077497220898841
f1_score: 0.7274973861800208
AUC: 0.9290751730536397
good classifier
gini 0.8581503461072795
ks value:0.7107
Զ��������give me some credit���ݼ���ģ���ĵ�ģ������AUC 0.85��
���ع����
��ģ����֤��,���ǻ�Ҫ����ģ�Ͳ����Ƿ���ѡ����ع���û����Ҫ�����Ļ������������������кܶ����,���������������������������Ի�ø��õĽ��,
����(�ͷ�)��ʱ����������ġ�
�ͷ� - {��l1��, ��l2��, ��elasticnet��, ��none��}, default=��l2��
�ͷ�ǿ���� C ��������,����ܺ����á�
C �C������,Ĭ��ֵ = 1.0
ʹ�ò�ͬ�������,����ʱ���ܻ�۲쵽���õ����ܻ������仯��
����� - {��newton-cg��, ��lbfgs��, ��liblinear��, ��sag��, ��saga��}, default=��lbfgs��
ע��:Ҫʹ�õ��㷨�ɳͷ�����:�����֧�ֵijͷ�:
1. ��newton-cg�� �C [��l2��, ��none��]
2. ��lbfgs�� �C [��l2��, ��none��]
3.��liblinear�� - [��l1��, ��l2��]
4. ��sag�� �C [��l2��, ��none��]
5. ��saga�� �C [��elasticnet��, ��l1��, ��l2��, ��none��]
�ˡ����ֿ�����
===
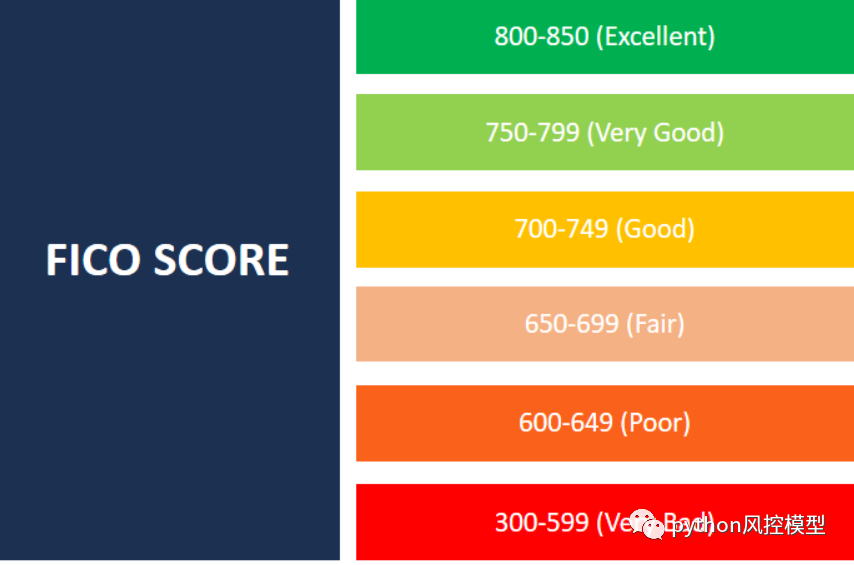
ģ�������ع�ı���ϵ����WOEֵ���������ֿ������ֿ�����ҵ�����,��ʹ�ü�ʮ��,�dz��ȶ�,���ܽ�����ҵϲ�����䷽�����ǽ�Logisticģ���ʷ�ת��Ϊ300-900�ֵı����ֵ���ʽ�����ھ�������������ֿ���Ч�µ�����FICO������
FICO ����Ϊ 800 �����ϵĸ��˾�����������ü�¼���������ָߵ��˺ܿ��ܶ�����ӵ�ж������ö�ȡ�����û�г����κ����ö��,����ʱ����������ծ��
�и� 700 �ֵ� FICO �����Dz����ķ������÷��ڴ˷�Χ�ڵĸ������ǵؽ�������Ѳ���ʱ�����Щ��,���� 800 �����ϵ���,������������Ŵ�,����ͨ��֧��������Ҫ�͵öࡣ
����ķ������� 650 �� 750 ֮�䡣��Ȼ�����ڴ˷�Χ�ڵĸ��������൱��,�����ǿ��ܻ��ӳٸ����Щ��ͨ��������ѻ�ô������,���ǿ�����Ҫ֧���Ըߵ����ʡ�
���һ��Ҫ���ǵ�ʵ�ʷ�Χ�� 599 ����͵ķ��������DZ���Ϊ�������ֲ���,ͨ�������ڶ���ӳٸ��δ�ܳ���ծ�����ת���տ������ծ�����¡�ӵ�д��� FICO �����ĸ���ͨ������(������Dz����ܵĻ�)����κ���ʽ�����á�
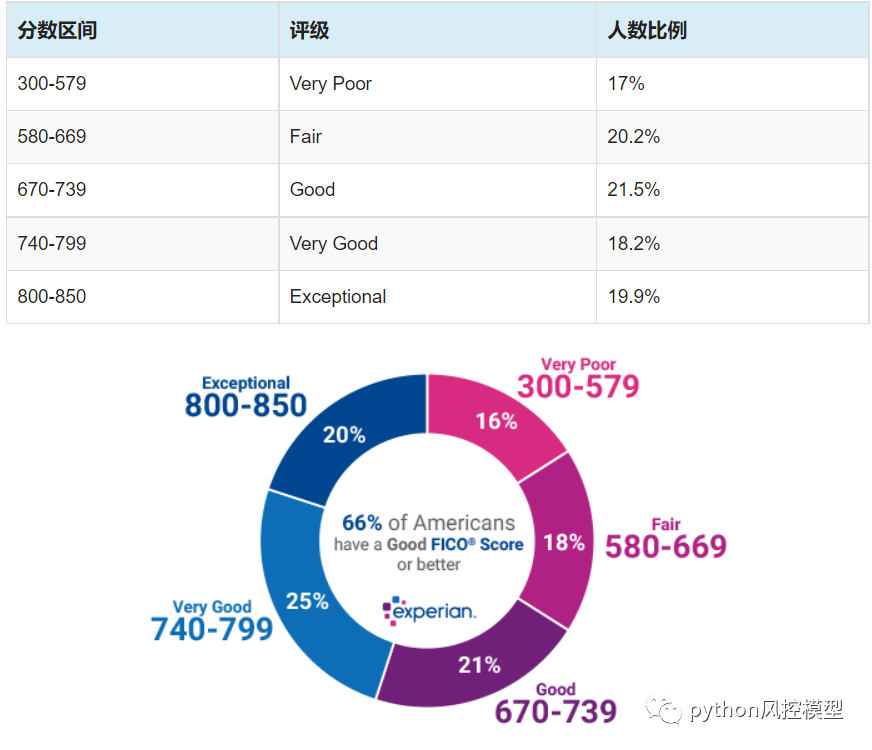
����ͼ, FICO���÷���very poor300-579�ֵ�ռ�����,ֻ��17%;good670-739�ֵ�ռ�����,�ﵽ21.5%��
��python�������ֿ���ģ(������)�������ֿ���������ϸ�½ڽ���,����PDO,theta0,P0,A,B,odds,woe,iv��רҵ��������ȫ�����
��.���ֿ��Զ�����ϵͳ
����ͨ���������,���������Զ�������ϵͳ,��ÿ�����뵥�û����ɺû��ͻ���ʵ��ǩ,�û��ͻ�Ԥ���ǩ,���ͻ�����ֵ,�������֡�
�����������ֿ�����,���ǿ��Խ���������Զ����û�����ϵͳ��������ͳ��ƷFICO�����ƹ���,FICO�ײ�������Java��Ŀǰ����Java,python��R�������Թ������ֿ��Զ���ģ��ϵͳ�������������,�����Զ����û�����ϵͳ��������,��Ҫרҵ�ŶӲ��ϲ��Ժ��¡�python��R�ǿ�Դ����,����������,���û��רҵ�Ŷ�ά��,��ϵͳ�ڽ���������������⡣
ʮ.ģ�ͼ��
��ʱ������,ģ����������,����ks,auc�����½�,ģ���ȶ���Ҳ�ᷢ��ƫ�ơ�������Ҫרҵģ�ͼ���Ŷ�,����ص�ģ�����������½�������ģ���ȶ��Է����ϴ�ƫ��ʱ,������Ҫ���¿���ģ��,����ģ�͡�ģ�ͼ���Ŷ�Ӧ��ÿ�հ�ʱ�ʼ�����ģ�ͼ�ر���������Ŷ�,�ر��ǿ����ŶӺ�ҵ���Ŷӡ�
ģ�ͼ�ص�ksָ��,��ģ��ks����0.2ʱ,ģ�����ֺû��ͻ���������û������,��Ҫ���µ���ģ�͡�
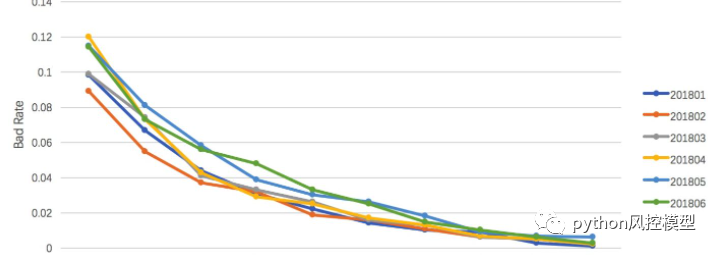
ģ�ͼ�ص�bad rateָ��,��bad rateͻȻ����ʱ,�쵼��dz�����,����ζ�Ŵ��������ղ��سɱ���
ģ�ͼ�ص�PSIָ��,��PSI����0.25ʱ,��ʾģ�ͼ����ȶ�,��Ҫ���µ�����
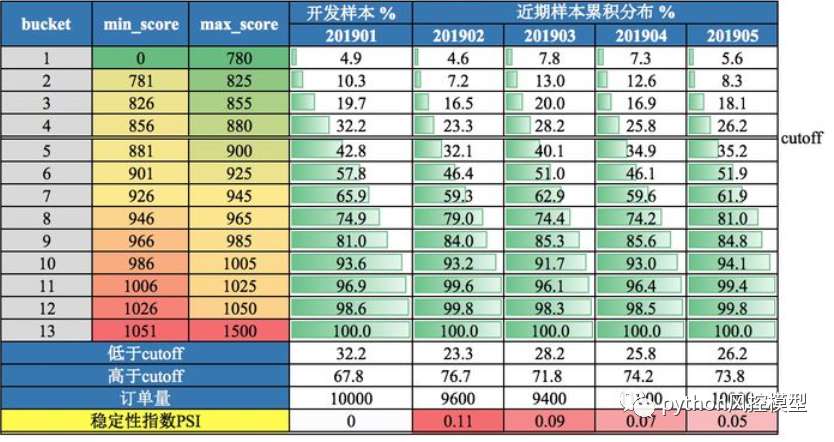
ģ�ͼ����ģ��Ч������һ��,Ҳ�Ǵ���������ȥ���,һ����Ч��,��Ҫ�����������ں��������ڱ���,�������ڲ���Ҫ�ͽ�ģ������ô�ϸ�,���Է���һЩ�������ȶ���,ͬ���DZ����ȶ��Ժ�ģ���ȶ���,����ķ�ʽ��ģ��Ч�����۲������ơ������Է�Ϊǰ�ˡ���˼�ء�
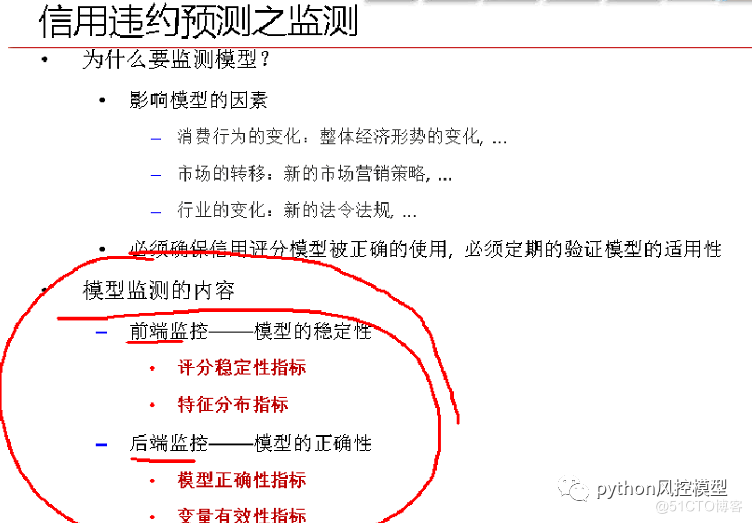
(1)ǰ�˼��,����֮ǰ,��Ŀͻ�����,���ģ���ܲ�����?
����ʹ�õ�ģ��,���еı���һ�����ܲ����Խϴ�
����,�������ָ��,��Ȼ����Ҫ,���Dz����Ժܴ�,���ʺ����ڳ��ڽ�ģ�����С����ӲҪ������ŵ�ģ��֮��,���Ըij�����İٷ�λ��(����)��
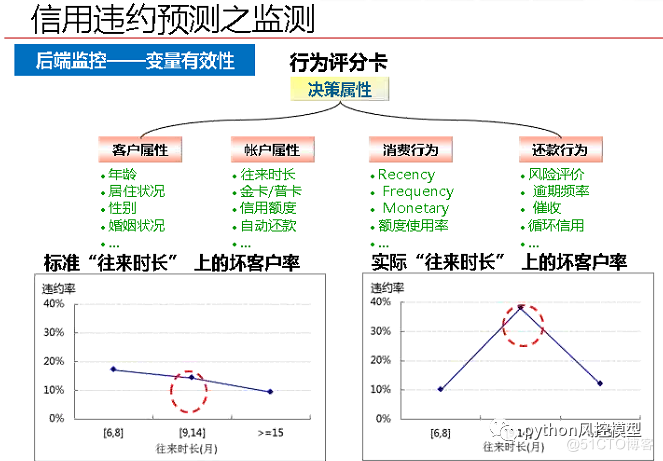
(2)��˼��,��ģ����֮��,���˷���,����һ��֮��,�����Ƿ����˸ı䡣
��Ҫ���ģ�͵���ȷ���Լ�����ѡ�����Ч�ԡ������˲�ƽ��������,��Ҫ���¿���
�ܽ�
����Python���������ֿ�ģ����Ҫ���̾�Ϊ��ҽ��ܵ�����,��ʵ�����ֿ���ģ���кܶ�ϸ��,�������϶���Щϸ���������ڲ�����������ȷ���������ȱʧ�ʴﵽ80%-90%��Ӧ��ֱ��ɾ���ñ�����?��������Ըߴ�0.8�Ϳ���ȥ����?����ḻ��ģ��Ա��Ҫ����ѧ����,ҵ����ʵ������,��������Խ���ȶ���ҵ�ƽ���,������ֻ��һ���Ƕ�˼�����⡣�������ḻ���ҽ������һ����ȫ��ѭ�̿�������ۡ�ͳ��ѧ,����ѧϰ,�˹����ܵ��������кܶ�����ط�,��������ȫͳһ��ʶ����λ��ѧϰʱҪ���ֶ���˼������,�������ܲ����Ż����ݿ�ѧ֪ʶ��
����Python���������ֿ�ģ��-give me some credit��Ϊ��ҽ��ܵ�������,��ӭ��λͬѧ����<python���ڷ�����ֿ�ģ�ͺ����ݷ���רҵ��>,ѧϰ�������֪ʶ��
��Ȩ����:�������Թ��ں�(python���ģ��),δ������,���ó�Ϯ����ѭCC 4.0 BY-SA��ȨЭ��,ת���븽��ԭ�ij������Ӽ���������