±≥ΨΑ «‘ΎΙΛΉς÷–,–η“ΣΗχ“ΒΈώΖΫΧαΙ©“ΜΕ―ΟςœΗ ΐΨί,¥” ΐΨίΩβάο»Γ≥ωά¥ΒΡΟςœΗ ΐΨί≥§ΙΐcsvΈΡΦΰ¥ρΩΣΒΡ…œœόΝΥ,“ΒΈώΖΫΟΜΖ®”Ο,Υυ“‘ΨΆ–η“ΣΕ‘ΤδΫχ––≤πΖ÷
pythonΕΝ–¥csvΈΡΦΰ≤β ‘
œ»≈δ÷ΟœύΙΊΑϋ≤ΔΕ®“ε“ΜΗωΫαΙϊΈΡΦΰΒΡ¥φ¥Δ¬ΖΨΕ
import csv
import os
#¥¥Ϋ®csvΈΡΦΰ≤Δ–¥»κ÷ΗΕ®ΡΎ»ί
#Ε®“εΫαΙϊΈΡΦΰΒΡ…ζ≥…¬ΖΨΕ
result_path = 'D:\Python_Project\CSVΈΡΦΰ≤πΖ÷\ΫαΙϊΈΡΦΰ'
ΆυcsvΈΡΦΰ–¥»κ ΐΨίΒΡ ±Κρ”–ΝΫ÷÷ΖΫ Ϋ,writerowΚΆwriterows
#writerow
with open(result_path + '\»ΐΙζ.csv','w', newline='') as file:
writer = csv.writer(file) # csv.writer()Κ· ΐ”Ο”Ύ¥¥Ϋ®“ΜΗωwriterΕ‘œσ
writer.writerow(["Νθ±Η", "–ΰΒ¬", " ώ"]) # writer.writerow()»ΜΚσ Ι”ΟΗΟΚ· ΐΫΪΒΞ–––¥»κ CSV ΈΡΦΰ
writer.writerow(["≤ή≤Ό", "ΟœΒ¬", "ΈΚ"])
writer.writerow(["Υο»®", "÷ΌΡ±", "Έβ"])
writer.writerow(["Ε≠ΉΩ", "÷Ό”±", "ΤδΥϋ"])
“Μ––“Μ––ΒΡΆυάοΟφΧμΦ”,ΫαΙϊ»γœ¬ΆΦ
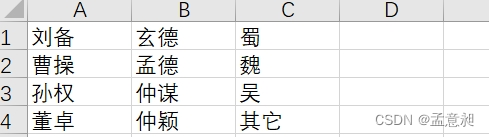
#writerows
list = [["ΙΊ”π", "‘Τ≥Λ", " ώ"],
["œΡΚνêΣ", "‘Σ»Ο", "ΈΚ"],
["Η Ρΰ", "–ΥΑ‘", "Έβ"],
["¬ά≤Φ", "Ζνœ»", "ΤδΥϊ"]]
with open(result_path + '\»ΐΙζ.csv','a', newline='') as file: #a±μ ΨΉΖΦ”ΡΎ»ί
writer = csv.writer(file)
writer.writerows(list)
writerows‘ρ «ΉΦ±Η“ΜΗωΝ–±μ,“Μ¥Έ÷±Ϋ”≤ε»κ,ΫαΙϊ»γœ¬ΆΦ
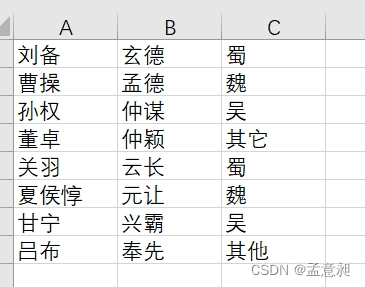
ΉΦ±Η“ΜΗω–η“Σ«–Ζ÷ΒΡcsvΈΡΦΰ
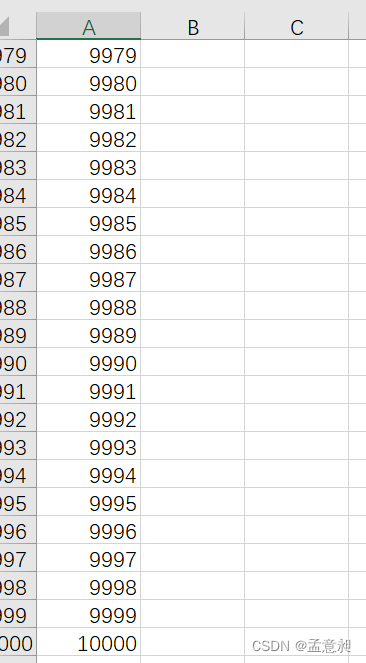
–¬Ϋ®“ΜΗωcsvΈΡΦΰ,≤Δ÷±Ϋ”ΉΦ±Η10000––,Κσ–χΟΩ1000––≤πΖ÷1¥Έ
»ΖΕ® δ»κΈΡΦΰ¬ΖΨΕΚΆ δ≥ωΈΡΦΰ¬ΖΨΕ,Τδ÷–i «ΈΡΦΰΒΡΒΎi––,j «”Οά¥±μ ΨΒΎjΗω δ≥ωΒΡΈΡΦΰ
#ΉΦ±Η10000––ΒΡcsvΉςΈΣ―υάΐ,Ϋχ––≤πΖ÷
example_path = 'D:\Python_Project\CSVΈΡΦΰ≤πΖ÷\example.csv' # –η“Σ≤πΖ÷ΈΡΦΰΒΡ¬ΖΨΕ
example_result_dir = 'D:\Python_Project\CSVΈΡΦΰ≤πΖ÷' # ≤πΖ÷ΚσΈΡΦΰΒΡ¬ΖΨΕ
with open(example_path, 'r', newline='') as example_file:
example = csv.reader(example_file)
i = j = 1
for row in example:
print(row)
print(f'i Β»”Ύ {i}, j Β»”Ύ {j}')
# ΟΩ1000ΗωΨΆjΦ”1, »ΜΚσΨΆ”–“ΜΗω–¬ΒΡΈΡΦΰΟϊ
if i % 1000 == 0:
j += 1
print(f'ΒΎ{j}ΗωΈΡΦΰ…ζ≥…Άξ≥…')
example_result_path = example_result_dir + '\example_result' + str(j) + '.csv'
print(example_result_path)
Ε‘”ΎΟΜ”– δ≥ωΈΡΦΰΒΡ«ιΩω,ΨΆ–¬¥¥Ϋ®“ΜΗω
# ≤Μ¥φ‘Ύ¥ΥΈΡΦΰΒΡ ±Κρ,ΨΆ¥¥Ϋ®
if not os.path.exists(example_result_path):
with open(example_result_path, 'w', newline='') as file:
csvwriter = csv.writer(file)
csvwriter.writerow(['’β «“ΜΗω±μΆΖ'])
csvwriter.writerow(row)
i += 1
»γΙϊ¥φ‘Ύ δ≥ωΈΡΦΰΒΡΜΑ,‘ρ÷±Ϋ”ΉΖΦ”ΡΎ»ί
# ¥φ‘ΎΒΡ ±ΚρΨΆΆυάοΟφΧμΦ”
else:
with open(example_result_path, 'a', newline='') as file:
csvwriter = csv.writer(file)
csvwriter.writerow(row)
i += 1
δ≥ωΫαΙϊ»γœ¬
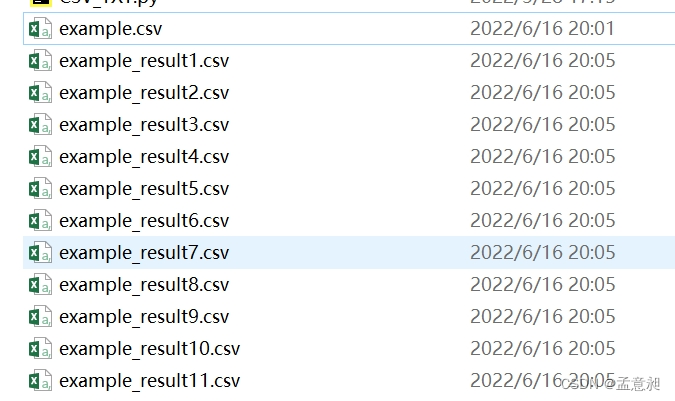
Άξ’ϊ¥ζ¬κ»γœ¬:
import csv
import os
#¥¥Ϋ®csvΈΡΦΰ≤Δ–¥»κ÷ΗΕ®ΡΎ»ί
#Ε®“εΫαΙϊΈΡΦΰΒΡ…ζ≥…¬ΖΨΕ
result_path = 'D:\Python_Project\CSVΈΡΦΰ≤πΖ÷\ΫαΙϊΈΡΦΰ'
#writerow
with open(result_path + '\»ΐΙζ.csv','w', newline='') as file:
writer = csv.writer(file) # csv.writer()Κ· ΐ”Ο”Ύ¥¥Ϋ®“ΜΗωwriterΕ‘œσ
writer.writerow(["Νθ±Η", "–ΰΒ¬", " ώ"]) # writer.writerow()»ΜΚσ Ι”ΟΗΟΚ· ΐΫΪΒΞ–––¥»κ CSV ΈΡΦΰ
writer.writerow(["≤ή≤Ό", "ΟœΒ¬", "ΈΚ"])
writer.writerow(["Υο»®", "÷ΌΡ±", "Έβ"])
writer.writerow(["Ε≠ΉΩ", "÷Ό”±", "ΤδΥϋ"])
#writerows
list = [["ΙΊ”π", "‘Τ≥Λ", " ώ"],
["œΡΚνêΣ", "‘Σ»Ο", "ΈΚ"],
["Η Ρΰ", "–ΥΑ‘", "Έβ"],
["¬ά≤Φ", "Ζνœ»", "ΤδΥϊ"]]
with open(result_path + '\»ΐΙζ.csv','a', newline='') as file: #a±μ ΨΉΖΦ”ΡΎ»ί
writer = csv.writer(file)
writer.writerows(list)
#ΉΦ±Η10000––ΒΡcsvΉςΈΣ―υάΐ,Ϋχ––≤πΖ÷
example_path = 'D:\Python_Project\CSVΈΡΦΰ≤πΖ÷\example.csv' # –η“Σ≤πΖ÷ΈΡΦΰΒΡ¬ΖΨΕ
example_result_dir = 'D:\Python_Project\CSVΈΡΦΰ≤πΖ÷' # ≤πΖ÷ΚσΈΡΦΰΒΡ¬ΖΨΕ
with open(example_path, 'r', newline='') as example_file:
example = csv.reader(example_file)
i = j = 1
for row in example:
print(row)
print(f'i Β»”Ύ {i}, j Β»”Ύ {j}')
# ΟΩ1000ΗωΨΆjΦ”1, »ΜΚσΨΆ”–“ΜΗω–¬ΒΡΈΡΦΰΟϊ
if i % 1000 == 0:
j += 1
print(f'ΒΎ{j}ΗωΈΡΦΰ…ζ≥…Άξ≥…')
example_result_path = example_result_dir + '\example_result' + str(j) + '.csv'
print(example_result_path)
# ≤Μ¥φ‘Ύ¥ΥΈΡΦΰΒΡ ±Κρ,ΨΆ¥¥Ϋ®
if not os.path.exists(example_result_path):
with open(example_result_path, 'w', newline='') as file:
csvwriter = csv.writer(file)
csvwriter.writerow(['’β «“ΜΗω±μΆΖ'])
csvwriter.writerow(row)
i += 1
# ¥φ‘ΎΒΡ ±ΚρΨΆΆυάοΟφΧμΦ”
else:
with open(example_result_path, 'a', newline='') as file:
csvwriter = csv.writer(file)
csvwriter.writerow(row)
i += 1