?拓展练习――911数据中不同月份不同类型的电话的次数的变化情况
现在我们有2015到2017年25万条911的紧急电话的数据,请统计出这些数据中不同类型的紧急情况的次数,如果我们还想统计出不同月份不同类型紧急电话的次数的变化情况,应该怎么做呢?
数据来源:https://www.kaggle.com/mchirico/montcoalert/data
?案例实操
首先,导入一些基础的数据分析包,读取数据信息,查看数据head和info()
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv("./911.csv")
print(df.head(3))
print(df.info())
>>> df.head()
lat lng desc \
0 40.297876 -75.581294 REINDEER CT & DEAD END; NEW HANOVER; Station ...
1 40.258061 -75.264680 BRIAR PATH & WHITEMARSH LN; HATFIELD TOWNSHIP...
2 40.121182 -75.351975 HAWS AVE; NORRISTOWN; 2015-12-10 @ 14:39:21-St...
zip title timeStamp twp \
0 19525.0 EMS: BACK PAINS/INJURY 2015-12-10 17:10:52 NEW HANOVER
1 19446.0 EMS: DIABETIC EMERGENCY 2015-12-10 17:29:21 HATFIELD TOWNSHIP
2 19401.0 Fire: GAS-ODOR/LEAK 2015-12-10 14:39:21 NORRISTOWN
addr e
0 REINDEER CT & DEAD END 1
1 BRIAR PATH & WHITEMARSH LN 1
2 HAWS AVE 1
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 249737 entries, 0 to 249736
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 lat 249737 non-null float64
1 lng 249737 non-null float64
2 desc 249737 non-null object
3 zip 219391 non-null float64
4 title 249737 non-null object
5 timeStamp 249737 non-null object
6 twp 249644 non-null object
7 addr 249737 non-null object
8 e 249737 non-null int64
dtypes: float64(3), int64(1), object(5)
memory usage: 17.1+ MB?问题描述一:统计出这些数据中不同类型的紧急情况的次数。
?我们需要将title里面的内容进行切割操作,提取出[EMS,Fire,Traffic]的内容。
data_1 = df["title"].str.split(":").tolist()
data_1[0:5]
>>>
[['EMS', ' BACK PAINS/INJURY'],
['EMS', ' DIABETIC EMERGENCY'],
['Fire', ' GAS-ODOR/LEAK'],
['EMS', ' CARDIAC EMERGENCY'],
['EMS', ' DIZZINESS']]?接下来我我们提取data_1中category的信息。
cate_list = list(set(i[0] for i in data_1))
cate_list
>>>
['Fire', 'EMS', 'Traffic']?这个时候我们有几种方法来统计出不同类型的紧急情况的次数。
方案一:set方法
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(cate_list))),columns=cate_list)
for cate in cate_list:
zeros_df[cate][df["title"].str.contains(cate)] = 1
# break
print(zeros_df)
sum_ret = zeros_df.sum(axis=0)
print(sum_ret)
>>>
Fire EMS Traffic
0 0.0 1.0 0.0
1 0.0 1.0 0.0
2 1.0 0.0 0.0
3 0.0 1.0 0.0
4 0.0 1.0 0.0
... ... ... ...
249732 0.0 1.0 0.0
249733 0.0 1.0 0.0
249734 0.0 1.0 0.0
249735 1.0 0.0 0.0
249736 0.0 0.0 1.0
[249737 rows x 3 columns]
Fire 37432.0
EMS 124844.0
Traffic 87465.0
dtype: float6?然后sum一下就好了。
zeros_df.sum(axis = 0)
>>>
Fire 37432.0
EMS 124844.0
Traffic 87465.0
dtype: float64方案二:for遍历整个DataFrame
直接遍历所有列表,这种方式相当的慢。
for i in range(df.shape[0]):
zeros_df.loc[i,data_1[i][0]] =1
pass
print(zeros_df)
>>>
Fire EMS Traffic
0 0.0 1.0 0.0
1 0.0 1.0 0.0
2 1.0 0.0 0.0
3 0.0 1.0 0.0
4 0.0 1.0 0.0
... ... ... ...
249732 0.0 1.0 0.0
249733 0.0 1.0 0.0
249734 0.0 1.0 0.0
249735 1.0 0.0 0.0
249736 0.0 0.0 1.0
[249737 rows x 3 columns]
zeros_df.sum(axis = 0)
zeros_df.sum(axis = 0)方案三:添加一列,然后分类Groupby
添加一列,然后groupby,最后count计数一下。
?
cate_list = [i[0] for i in data_1]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
print(df.groupby(by="cate").count()["title"])
>>>
cate
EMS 124840
Fire 37432
Traffic 87465
Name: title, dtype: int64
问题描述二:统计不同月份,不同类型紧急电话的变化情况。
这个就涉及到时间序列分析。
在pandas中处理时间序列是非常简单的
时间序列分析
(一)生成一段时间范围
pd.date_range(start=None, end=None, periods=None, freq='D')
start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
start和periods以及freq配合能够生成从start开始的频率为freq的periods个时间索引
?four parameters: start, end, periods, and freq, exactly three must be specified
四个参数,必须要至少指定其中的三个。
import pandas as pd
pd.date_range(start="20170909",end = "20180908",freq = "M")
>>>
DatetimeIndex(['2017-09-30', '2017-10-31', '2017-11-30', '2017-12-31',
'2018-01-31', '2018-02-28', '2018-03-31', '2018-04-30',
'2018-05-31', '2018-06-30', '2018-07-31', '2018-08-31'],
dtype='datetime64[ns]', freq='M')pd.date_range(start="20170909",periods = 5,freq = "D")
>>>
DatetimeIndex(['2017-09-09', '2017-09-10', '2017-09-11', '2017-09-12',
'2017-09-13'],
dtype='datetime64[ns]', freq='D')
?freq:就是时间出现的频率。
关于频率的更多缩写

(二)在DataFrame中使用时间序列
import numpy as np
index=pd.date_range("20170101",periods=10)
df = pd.DataFrame(np.random.rand(10),index=index)
df
>>>
0
2017-01-01 0.090949
2017-01-02 0.996337
2017-01-03 0.737334
2017-01-04 0.405381
2017-01-05 0.743721
2017-01-06 0.681303
2017-01-07 0.606283
2017-01-08 0.917397
2017-01-09 0.167316
2017-01-10 0.155164回到最开始的911数据的案例中,我们可以使用pandas提供的方法把时间字符串转化为时间序列
df["timeStamp"] = pd.to_datetime(df["timeStamp"],format="")format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文。
那么问题来了:
我们现在要统计每个月或者每个季度的次数怎么办呢?
(三)pandas重采样
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样。pandas提供了一个resample的方法来帮助我们实现频率转化
1.统计出911数据中不同月份电话次数的变化情况。
2.统计出911数据中不同月份不同类型的电话的次数的变化情况。
pandas.DataFrame.resample
?pandas.DataFrame.resample()这个函数主要是用来对时间序列做频率转换,函数原型如下:
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start', kind=None, loffset=None, limit=None, base=0, on=None, level=None)
?
?降采样(高频数据到低频数据):
import pandas as pd
import numpy as np
index=pd.date_range('20190115','20190125',freq='D')
data1=pd.Series(np.arange(len(index)),index=index)
data1
>>>
2019-01-15 0
2019-01-16 1
2019-01-17 2
2019-01-18 3
2019-01-19 4
2019-01-20 5
2019-01-21 6
2019-01-22 7
2019-01-23 8
2019-01-24 9
2019-01-25 10
Freq: D, dtype: int64data1.resample(rule='3D').sum() >>> 2019-01-15 3 2019-01-18 12 2019-01-21 21 2019-01-24 19 Freq: 3D, dtype: int64 data1.resample(rule='3D').mean() >>> 2019-01-15 1.0 2019-01-18 4.0 2019-01-21 7.0 2019-01-24 9.5 Freq: 3D, dtype: float64
?label这个参数控制了分组后聚合标签的取值。在label为right的情况下,将取分箱右侧的值作为新的标签。
升采样(低频数据到高频数据)
上面演示了降采样的过程,下面我们演示升采样的过程,根据升采样的定义,我们只需在resample函数中改变频率即可,但与降采样不同的是升采样后新增频率的数为空值,为此resample也提供了3种方式进行填充,下面我们通过代码来演示:
三种填充方式分别为:
ffill(取前面的值)
bfill(取后面的值)
interpolate(线性取值)
data1.resample(rule='12H').asfreq()
>>>
2019-01-15 00:00:00 0.0
2019-01-15 12:00:00 NaN
2019-01-16 00:00:00 1.0
2019-01-16 12:00:00 NaN
2019-01-17 00:00:00 2.0
2019-01-17 12:00:00 NaN
2019-01-18 00:00:00 3.0
2019-01-18 12:00:00 NaN
2019-01-19 00:00:00 4.0
2019-01-19 12:00:00 NaN
2019-01-20 00:00:00 5.0
2019-01-20 12:00:00 NaN
2019-01-21 00:00:00 6.0
2019-01-21 12:00:00 NaN
2019-01-22 00:00:00 7.0
2019-01-22 12:00:00 NaN
2019-01-23 00:00:00 8.0
2019-01-23 12:00:00 NaN
2019-01-24 00:00:00 9.0
2019-01-24 12:00:00 NaN
2019-01-25 00:00:00 10.0
Freq: 12H, dtype: float64
将原来的按日的数据进行升采样为6小时时,会产生很多空值,对于这种空值resample提供了3种方式,分别为ffill(取前面的值)、bfill(取后面的值)、interpolate(线性取值),这里我们分别进行测试,如下:
(1)在ffill中不传入任何参数的时候,所有的NAN被填充了,这里我们可以输入个数,从而指定要填充的空值个数。
data1.resample(rule='12H').ffill()
# 前向填充,取NAN前面的值来进行填充
2019-01-15 00:00:00 0
2019-01-15 12:00:00 0
2019-01-16 00:00:00 1
2019-01-16 12:00:00 1
2019-01-17 00:00:00 2
2019-01-17 12:00:00 2
2019-01-18 00:00:00 3
2019-01-18 12:00:00 3
2019-01-19 00:00:00 4
2019-01-19 12:00:00 4
2019-01-20 00:00:00 5
2019-01-20 12:00:00 5
2019-01-21 00:00:00 6
2019-01-21 12:00:00 6
2019-01-22 00:00:00 7
2019-01-22 12:00:00 7
2019-01-23 00:00:00 8
2019-01-23 12:00:00 8
2019-01-24 00:00:00 9
2019-01-24 12:00:00 9
2019-01-25 00:00:00 10
Freq: 12H, dtype: int64
data1.resample(rule='12H').ffill(2)
>>>
2019-01-15 00:00:00 0
2019-01-15 12:00:00 1
2019-01-16 00:00:00 1
2019-01-16 12:00:00 2
2019-01-17 00:00:00 2
2019-01-17 12:00:00 3
2019-01-18 00:00:00 3
2019-01-18 12:00:00 4
2019-01-19 00:00:00 4
2019-01-19 12:00:00 5
2019-01-20 00:00:00 5
2019-01-20 12:00:00 6
2019-01-21 00:00:00 6
2019-01-21 12:00:00 7
2019-01-22 00:00:00 7
2019-01-22 12:00:00 8
2019-01-23 00:00:00 8
2019-01-23 12:00:00 9
2019-01-24 00:00:00 9
2019-01-24 12:00:00 10
2019-01-25 00:00:00 10
Freq: 12H, dtype: int64
data1.resample(rule='12H').bfill()
>>>
2019-01-15 00:00:00 0
2019-01-15 12:00:00 1
2019-01-16 00:00:00 1
2019-01-16 12:00:00 2
2019-01-17 00:00:00 2
2019-01-17 12:00:00 3
2019-01-18 00:00:00 3
2019-01-18 12:00:00 4
2019-01-19 00:00:00 4
2019-01-19 12:00:00 5
2019-01-20 00:00:00 5
2019-01-20 12:00:00 6
2019-01-21 00:00:00 6
2019-01-21 12:00:00 7
2019-01-22 00:00:00 7
2019-01-22 12:00:00 8
2019-01-23 00:00:00 8
2019-01-23 12:00:00 9
2019-01-24 00:00:00 9
2019-01-24 12:00:00 10
2019-01-25 00:00:00 10
Freq: 12H, dtype: int64
data1.resample(rule='12H').interpolate()
# 线性填充
>>>
2019-01-15 00:00:00 0.0
2019-01-15 12:00:00 0.5
2019-01-16 00:00:00 1.0
2019-01-16 12:00:00 1.5
2019-01-17 00:00:00 2.0
2019-01-17 12:00:00 2.5
2019-01-18 00:00:00 3.0
2019-01-18 12:00:00 3.5
2019-01-19 00:00:00 4.0
2019-01-19 12:00:00 4.5
2019-01-20 00:00:00 5.0
2019-01-20 12:00:00 5.5
2019-01-21 00:00:00 6.0
2019-01-21 12:00:00 6.5
2019-01-22 00:00:00 7.0
2019-01-22 12:00:00 7.5
2019-01-23 00:00:00 8.0
2019-01-23 12:00:00 8.5
2019-01-24 00:00:00 9.0
2019-01-24 12:00:00 9.5
2019-01-25 00:00:00 10.0
Freq: 12H, dtype: float64
(一)数据初始化操作:
??????????? 将原始数据的索引设置为时间索引值,进行如下操作。
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df.set_index("timeStamp",inplace=True)
df
>>>

(二) 统计出911数据中不同月份电话次数
count_by_month = df.resample("M").count()["title"]
print(count_by_month)
>>>
timeStamp
2015-12-31 7916
2016-01-31 13096
2016-02-29 11396
2016-03-31 11059
2016-04-30 11287
2016-05-31 11374
2016-06-30 11732
2016-07-31 12088
2016-08-31 11904
2016-09-30 11669
2016-10-31 12502
2016-11-30 12091
2016-12-31 12162
2017-01-31 11605
2017-02-28 10267
2017-03-31 11684
2017-04-30 11056
2017-05-31 11719
2017-06-30 12333
2017-07-31 11768
2017-08-31 11753
2017-09-30 7276
Freq: M, Name: title, dtype: int64
?
(三)可视化分析――画图
#画图
_x = count_by_month.index
_y = count_by_month.values
_x = [i.strftime("%Y%m%d") for i in _x]
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.show()

?拓展练习――911数据中不同月份不同类型的电话的次数的变化情况
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#把时间字符串转为时间类型设置为索引
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
#添加列,表示分类
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
# print(np.array(cate_list).reshape((df.shape[0],1)))
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
df.set_index("timeStamp",inplace=True)
print(df.head(1))
plt.figure(figsize=(20, 8), dpi=80)
#分组
for group_name,group_data in df.groupby(by="cate"):
#对不同的分类都进行绘图
count_by_month = group_data.resample("M").count()["title"]
# 画图
_x = count_by_month.index
print(_x)
_y = count_by_month.values
_x = [i.strftime("%Y%m%d") for i in _x]
plt.plot(range(len(_x)), _y, label=group_name)
plt.xticks(range(len(_x)), _x, rotation=45)
plt.legend(loc="best")
plt.show()
>>>
lat lng \
timeStamp
2015-12-10 17:10:52 40.297876 -75.581294
desc \
timeStamp
2015-12-10 17:10:52 REINDEER CT & DEAD END; NEW HANOVER; Station ...
zip title twp \
timeStamp
2015-12-10 17:10:52 19525.0 EMS: BACK PAINS/INJURY NEW HANOVER
addr e cate
timeStamp
2015-12-10 17:10:52 REINDEER CT & DEAD END 1 EMS
DatetimeIndex(['2015-12-31', '2016-01-31', '2016-02-29', '2016-03-31',
'2016-04-30', '2016-05-31', '2016-06-30', '2016-07-31',
'2016-08-31', '2016-09-30', '2016-10-31', '2016-11-30',
'2016-12-31', '2017-01-31', '2017-02-28', '2017-03-31',
'2017-04-30', '2017-05-31', '2017-06-30', '2017-07-31',
'2017-08-31', '2017-09-30'],
dtype='datetime64[ns]', name='timeStamp', freq='M')
DatetimeIndex(['2015-12-31', '2016-01-31', '2016-02-29', '2016-03-31',
'2016-04-30', '2016-05-31', '2016-06-30', '2016-07-31',
'2016-08-31', '2016-09-30', '2016-10-31', '2016-11-30',
'2016-12-31', '2017-01-31', '2017-02-28', '2017-03-31',
'2017-04-30', '2017-05-31', '2017-06-30', '2017-07-31',
'2017-08-31', '2017-09-30'],
dtype='datetime64[ns]', name='timeStamp', freq='M')
DatetimeIndex(['2015-12-31', '2016-01-31', '2016-02-29', '2016-03-31',
'2016-04-30', '2016-05-31', '2016-06-30', '2016-07-31',
'2016-08-31', '2016-09-30', '2016-10-31', '2016-11-30',
'2016-12-31', '2017-01-31', '2017-02-28', '2017-03-31',
'2017-04-30', '2017-05-31', '2017-06-30', '2017-07-31',
'2017-08-31', '2017-09-30'],
dtype='datetime64[ns]', name='timeStamp', freq='M')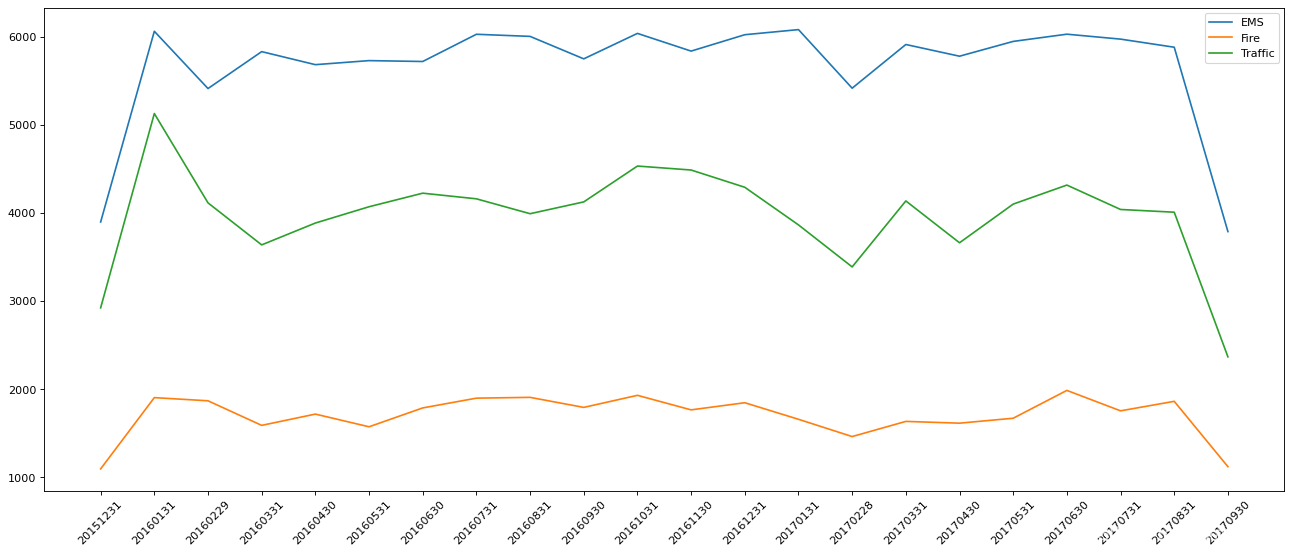
?关于PM2.5的Demo
# coding=utf-8
import pandas as pd
from matplotlib import pyplot as plt
file_path = "./PM2.5/BeijingPM20100101_20151231.csv"
df = pd.read_csv(file_path)
#把分开的时间字符串通过periodIndex的方法转化为pandas的时间类型
period = pd.PeriodIndex(year=df["year"],month=df["month"],day=df["day"],hour=df["hour"],freq="H")
df["datetime"] = period
# print(df.head(10))
#把datetime 设置为索引
df.set_index("datetime",inplace=True)
#进行降采样
df = df.resample("7D").mean()
print(df.head())
#处理缺失数据,删除缺失数据
# print(df["PM_US Post"])
data =df["PM_US Post"]
data_china = df["PM_Nongzhanguan"]
print(data_china.head(100))
#画图
_x = data.index
_x = [i.strftime("%Y%m%d") for i in _x]
_x_china = [i.strftime("%Y%m%d") for i in data_china.index]
print(len(_x_china),len(_x_china))
_y = data.values
_y_china = data_china.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y,label="US_POST",alpha=0.7)
plt.plot(range(len(_x_china)),_y_china,label="CN_POST",alpha=0.7)
plt.xticks(range(0,len(_x_china),10),list(_x_china)[::10],rotation=45)
plt.legend(loc="best")
plt.show()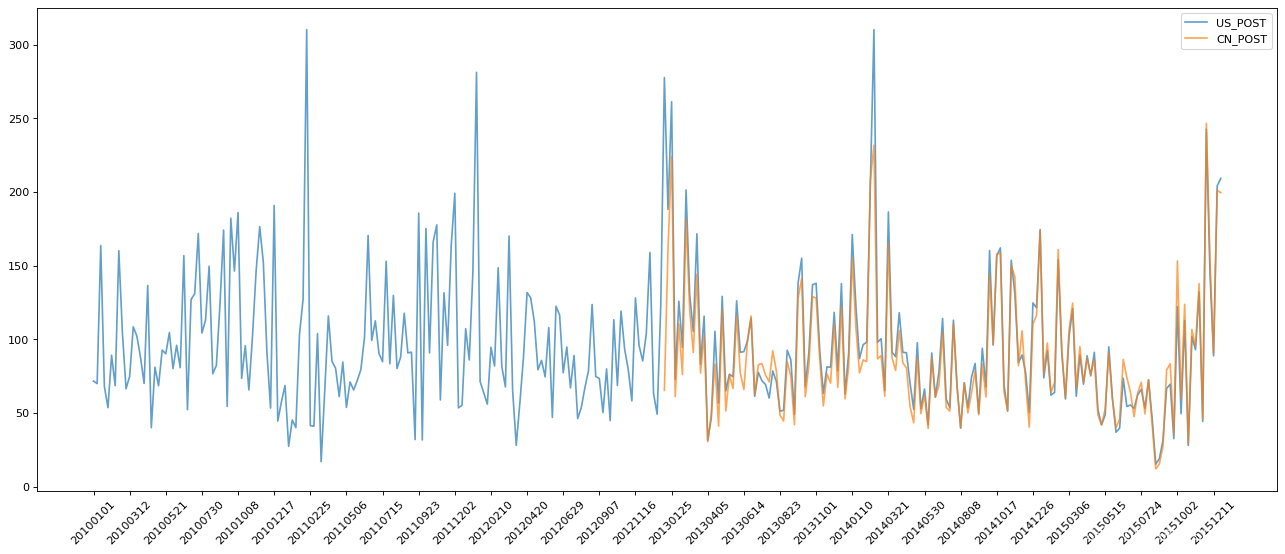
注意点:
分开的时间字符串通过periodIndex的方法转化为pandas的时间类型
period=pd.PeriodIndex(year=df["year"],month=df["month"],day=df["day"],hour=df["hour"],freq="H") df["datetime"] = period
?关于重采样的部分内容参考: