使用Python的pandas库操作Excel
最近因需要用Excel电子表格处理数据,使用了其它一些方式处理Excel文件数据,这是学习笔记的整理。
Excel2003及以前版:列数最大256(2的8次方)列,行数最大65536(2的16次方)行;Excel2007及以后版:列数最大16384(2的14次方),行数最大1048576(2的20次方);
获取Excel最大行和最大列的方法:
启动Excel后通过快捷键Ctrl+方向键(←↑↓→),可以定位到最左、最上、最下、最右的单元格,从而可以看到行和列的最大值。
Python中有很多库可以操作Excel,像pandas、xlrd、xlwt、xlutils、openpyxl?等。
xlrd 库:读取 Excel 文件
xlwt 库:写入 Excel 文件
xlutils 库:操作 Excel 文件的实用工具,如复制、分割、筛选等
xlrd、xlwt、xlutils 库可以读写操作后缀为xls的excel文件。
openpyxl库?:操作xlsx后缀的excel文件,还要用到这个库。
本文主要介绍pandas。特别提示:
pandas 库是基于numpy库 的软件库,因此安装Pandas 之前需要先安装numpy库。默认的pandas不能直接读写excel文件,需要安装读、写库即xlrd、xlwt才可以实现xls后缀的excel文件的读写,要想正常读写xlsx后缀的excel文件,还需要安装openpyxl库 。
pandas库简介
pandas官网 https://pandas.pydata.org/
pandas 中文教程 https://www.gairuo.com/p/pandas-tutorial
pandas库是一个Python的核心数据分析支持库,它提供了强大的一维数组和二维数组处理能力,其非常擅长与处理二维表结构,带行列标签的矩阵数据,时间序列数据。pandas提供的两个主要数据结构一维数组(Series)和二维数组(DataFrame)强力的支撑着当今金融、统计、社会科学、工程等诸多领域的数据分析工作。通过pandas我们可以方便的操作数据的增、查、改、删、合并、重塑、分组、统计分析,此外pandas还提供了非常成熟的I/O工具,用于读取文本文件,excel文件,数据库等不同来源数据,利用超快的HDF5格式保存/加载数据。
Series是 pandas 常用的数据结构之一,它是一种类似于一维数组的结构,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系。
Series 可以保存任何数据类型,比如整数、字符串、浮点数、Python 对象等,它的标签默认为整数,从 0 开始依次递增。Series 的结构图,如下所示:

DataFrame (数据帧)一个表格型的数据结构,既有行标签(index),又有列标签(columns),它也被称异构数据表,所谓异构,指的是表格中每列的数据类型可以不同,比如可以是字符串、整型或者浮点型等。其结构图示意图,如下所示:
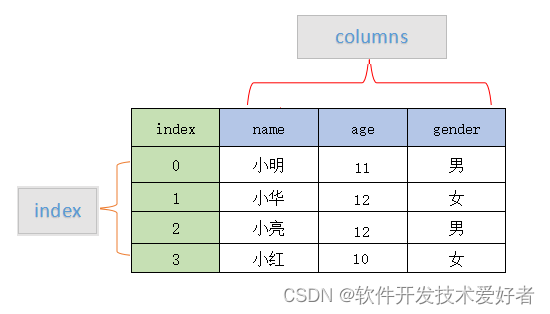
pandas中的数据结构和Excel文档属性的对应关系
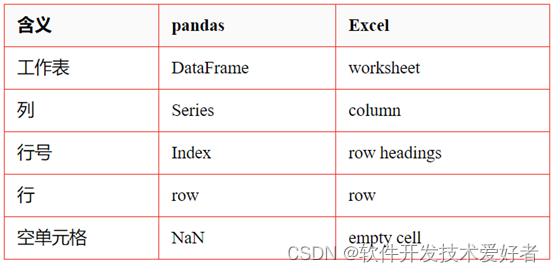
☆ pandas 中的 DataFrame 类似于 Excel 的工作表。但是Excel 工作簿可以包含多个工作表,而 pandas DataFrame 是独立存在的。
☆ Series 表示 DataFrame 的一列数据结构,使用Series类似于引用电子表格的一列。
每个 DataFrame 和 Series 都有一个Index,它是数据行上的标签。
☆ 在 pandas 中,如果未指定索引,则默认使用 RangeIndex(第一行 = 0,第二行 = 1,依此类推),类似于电子表格中的行号(数字)。
pandas 也可以将索引设置为一个(或多个)唯一值,这就像在工作表中拥有一个用作行标识符的列。
索引值是固定的,所以如果对 DataFrame 中的行重新排序,行的标签也不会改变。
pandas库的安装
Python模块(库、包)安装命令格式:
[py -X.Y -m] pip install [-i 镜像网址] 模块(库、包)名
其中[]部分表示可先的
若安装了多个python版本,为指定Python版本安装模块(库、包),X.Y代表Python版本,多余的部分舍弃如3.8.1取3.8,3.10.5取3.10,即只取第二个点前的部分。仅安装了一个python版本不需要。
常用的镜像网址
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
【详见 :https://blog.csdn.net/cnds123/article/details/104393385】
安装pandas 之前需要先安装numpy,在CMD中输入:
py -3.10 -m pip install -i http://mirrors.aliyun.com/pypi/simple/ numpy
我已安装过numpy,在此跳过
【查看python第三方模块(库、包)是否安装及其版本号
[py -X.Y -m] pip list
其中[]部分表示可选的,若安装了多个python版本,指定Python版本,查看由X.Y指定python版本关联的模块(库、包)情况】
要安装pandas库 ,打开cmd窗口,输入:
py -3.10 -m pip install -i http://mirrors.aliyun.com/pypi/simple/ Pandas
参见下图:
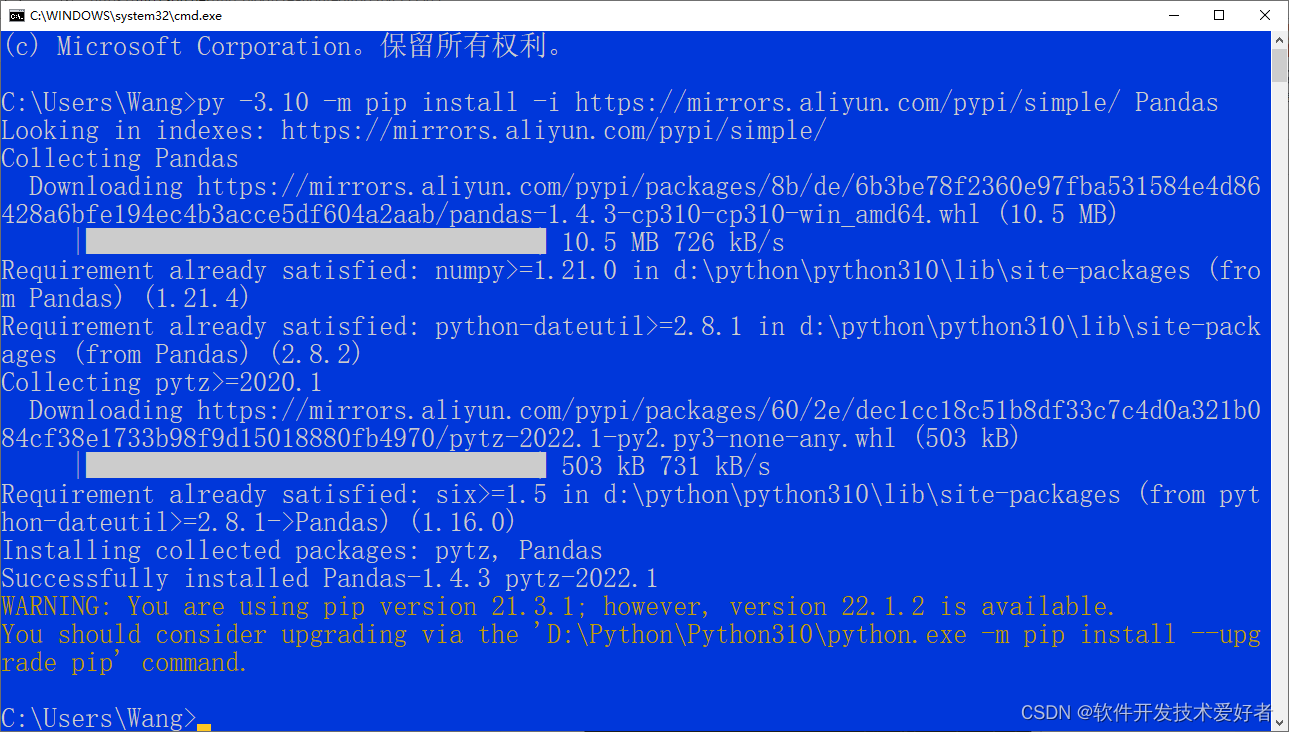
Successfully 表示成功了
WARNING部分大意是又可用的pip新的版本可以进行升级,可按提示中引号中的命令升级操作,也可不用管它
xlrd、xlwt、xlutils、openpyxl库的安装可参照上面的方法
安装成功后,我们就可以导入 pandas使用了。
pandas的基本操作
★数据读取
pandas读取excel的例子
test1.xlsx的内容如下:
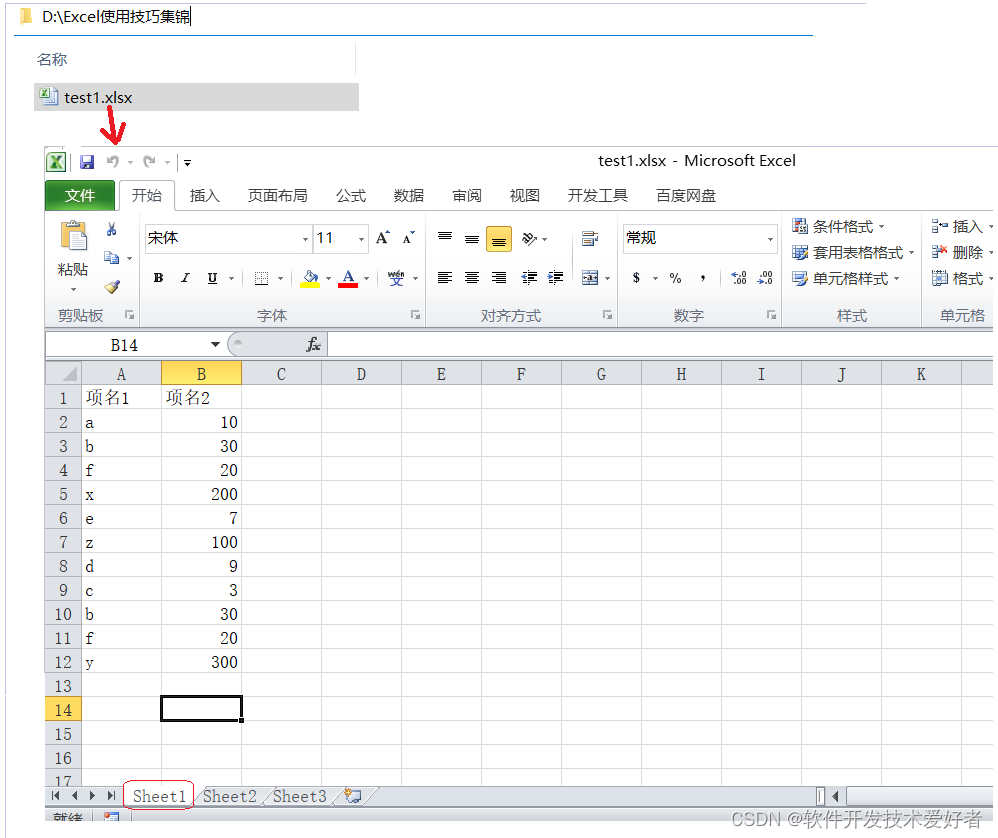
源码如下:
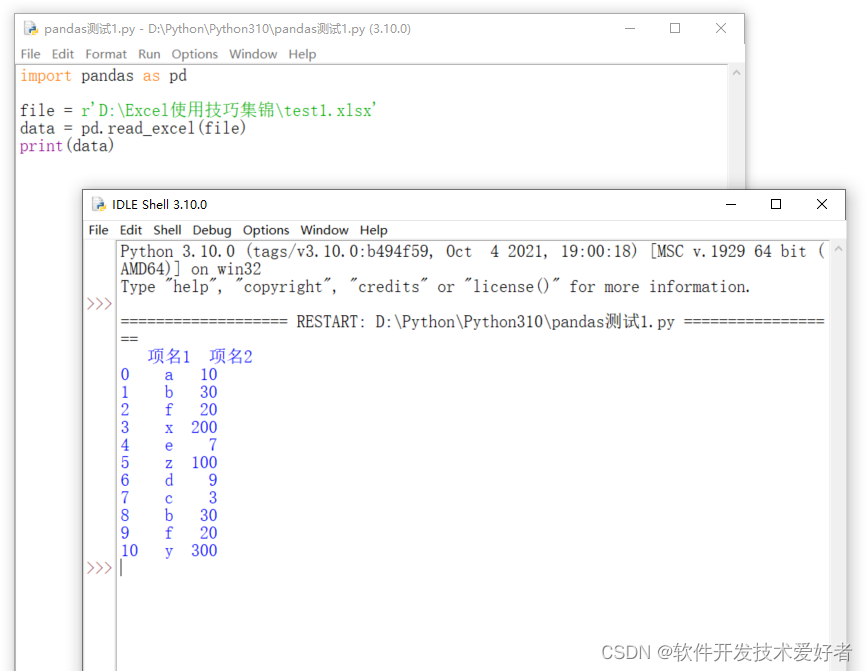
import pandas as pd
file = r'D:\Excel使用技巧集锦\test1.xlsx'
data = pd.read_excel(file)
print(data)
运行结果:
提示:
引号中是excel表格的文件路径和文件名,前面加“r”是为了防止python解释器对字符串字符转义处理。如果字符串中出现“\t”,不加“r”的话“\t”就会被转义,代表指制表符,代表着四个空格,也就是一个tab键,而加了“r”之后“\t”就能保留原有的样子。
file = r'D:\Excel使用技巧集锦\test1.xlsx' ,若直接写为file ='D:\Excel使用技巧集锦\test1.xlsx'将报错!但可改写为 file = 'D:\\Excel使用技巧集锦\\test1.xlsx'? 或file = 'D:/Excel使用技巧集锦/test1.xlsx'
read_excel()方法将Excel文件读取到pandas DataFrame中
有很多的参数详细介绍https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
常用的参数有
第一个参数指定带路径的文件名(如果需要打开的文件在当前路径下,可以省略文件路径只写文件名)
sheet_name参数可以指定sheet页名称或位置,可用字符串表示工作表(sheet)名称,用 整数索引表示工作表位置,缺省默认0即第一个位置的,如:
df= pd.read_excel(r'D:\Excel使用技巧集锦\test1.xlsx' , sheet_name='sheet1')
处理数据
#导入pandas库
import pandas as pd
# 读取excel 文件
df= pd.read_excel(r'D:\Excel使用技巧集锦\test1.xlsx' , sheet_name='Sheet1')
★ 获取列数据
df['column_name']
例如:
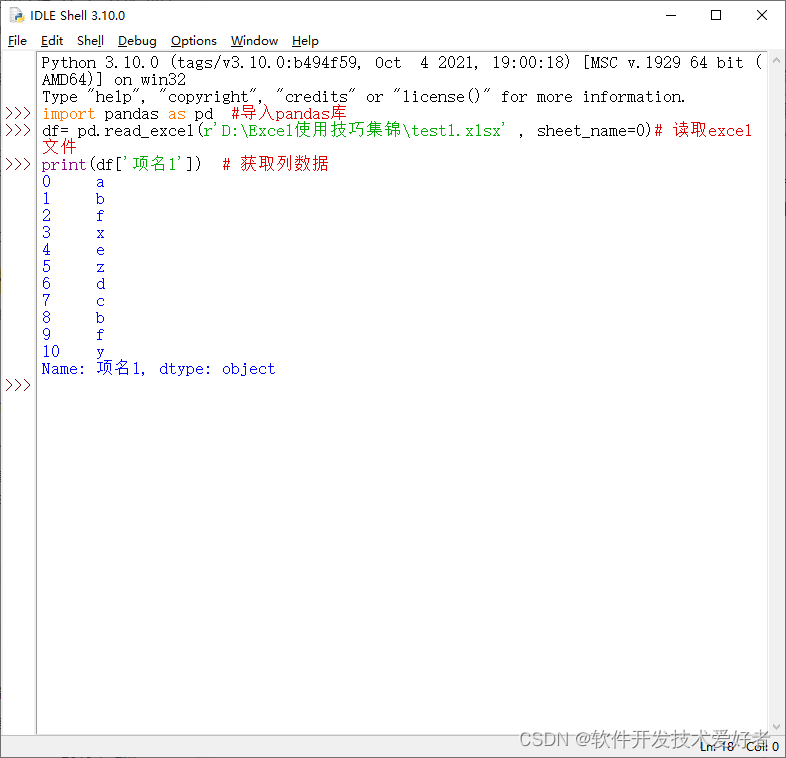
★获取多列 多列中,df[] 括号里边是一个列表
df[['columns_name1','columns_name2']]
★ 获取行数据
df.loc[Line_number [,'column_name']]
其中,Line_number是行号,column_name是列名,可缺省,列名缺省获取整行
★整体数据排序
df.sort_values(by='columns_name',ascending = False)
★Panda DataFrame 对象提供了一个数据去重的函数 drop_duplicates(),即从数据帧中删除重复项
df.drop_duplicates()
to_excel()方法将DataFrame 的内容保存到excel文件
to_excel()方法参数很多 可参见https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_excel.html?highlight=to_excel
常用的参数是指定带路径的文件名(如果需要打开的文件在当前路径下,可以省略文件路径只写文件名)
用to_excel()方法生成excel文件的简单示例如下:
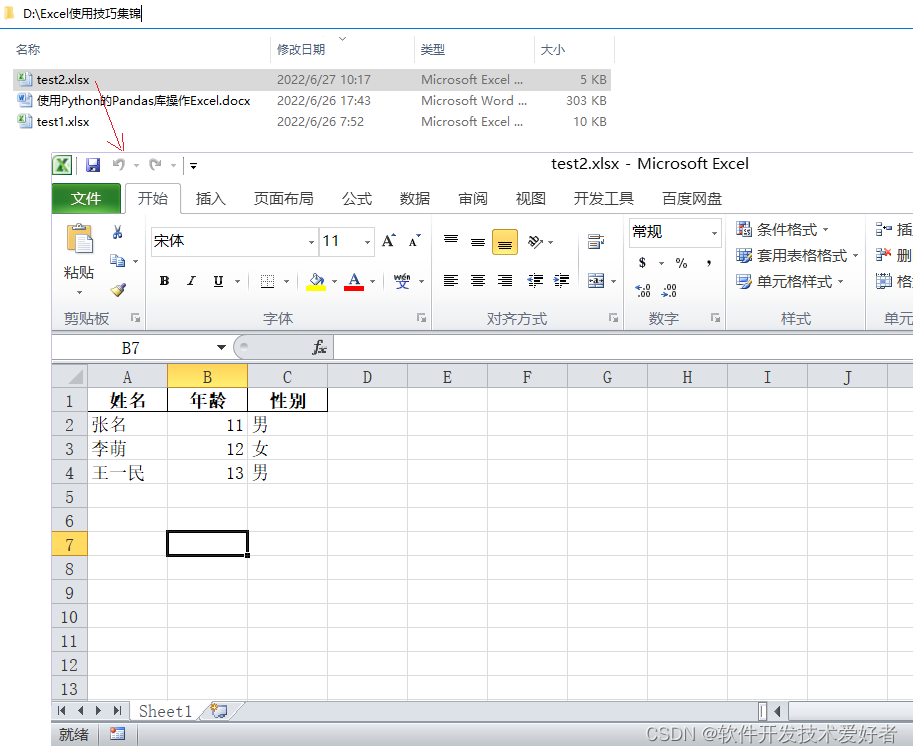
import pandas as pd # 导入模块
data = { '姓名': ['张名', '李萌', '王一民'], '年龄': [11, 12, 13], '性别': ['男', '女', '男']}
df = pd.DataFrame(data)
df.to_excel(r'D:\Excel使用技巧集锦\test2.xlsx',index=False)
运行之,结果如下:
下面,给出一个去除重复行的数据保存的例
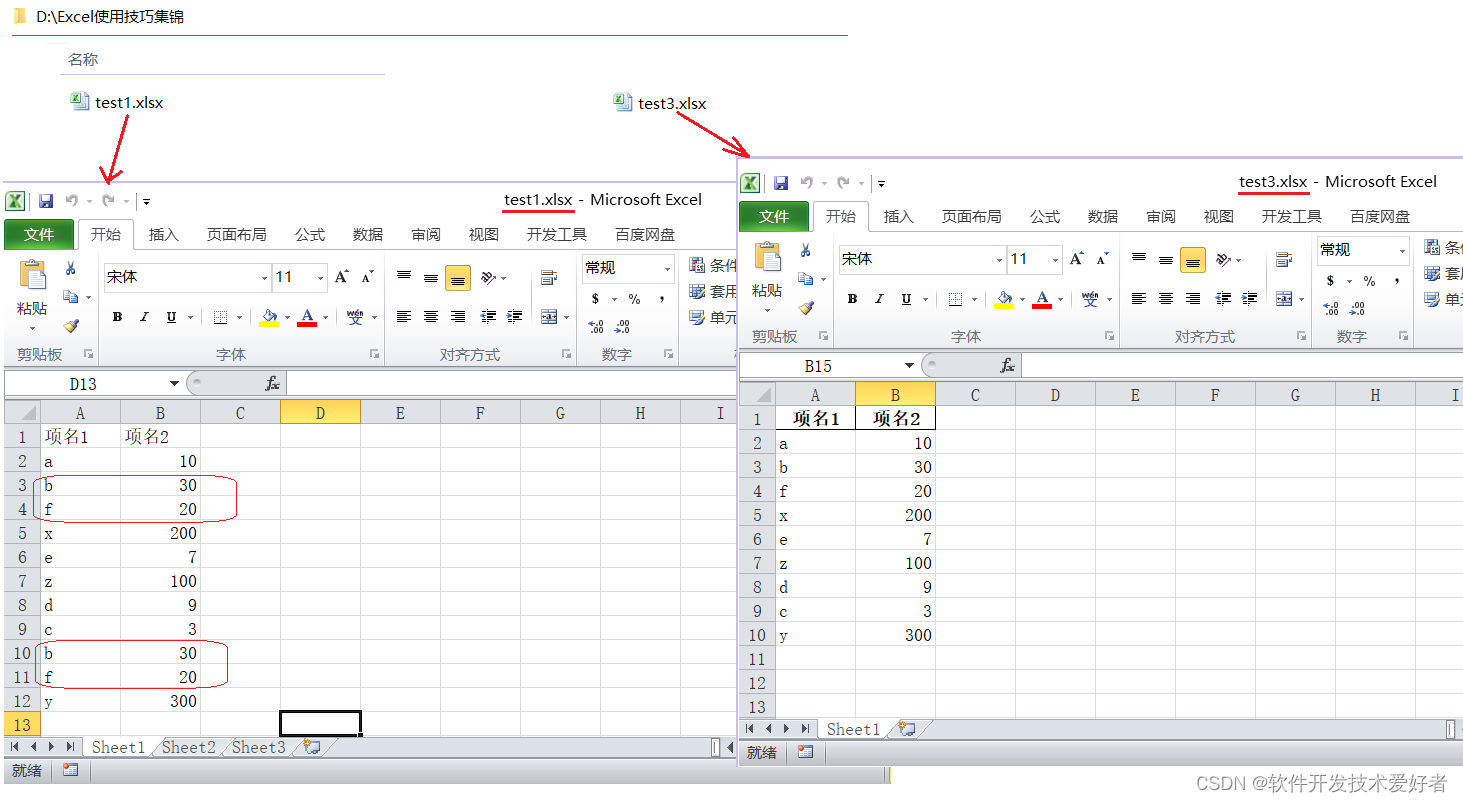
使用pandas读入test1.xlsx中Sheet1的数据删除重复行写入test3.xlsx的Sheet1中,源码如下:
import pandas as pd # 导入模块
# 读取excel 文件test1.xlsx
df= pd.read_excel(r'D:\Excel使用技巧集锦\test1.xlsx' , sheet_name='Sheet1')
#从数据帧中删除重复行
no_re_row=df.drop_duplicates()
#保存到test3.xlsx文件
no_re_row.to_excel(r'D:\Excel使用技巧集锦\test3.xlsx',index=False)
运行之,结果如下:
附录、进一步学习资料
利用Pandas来清除重复数据 https://blog.csdn.net/qq_42103091/article/details/104236873
pandas 处理excel表格数据的常用方法 https://blog.csdn.net/Flag_ing/article/details/124790461
操作Pandas和Excel表格的区别 https://blog.csdn.net/qq_45464895/article/details/124012761